第一时间捕获有价值的信号
本文译自 What if you don’t need MCP at all?。本文深入分析了 MCP 服务器的上下文开销问题,并展示了如何通过 Bash CLI 工具和代码来构建更灵活、更高效的 Agent 工具生态系统。
经过几个月的 Agent 编码狂热,Twitter 上仍然充斥着关于 MCP 服务器的讨论。我之前做过一些非常轻量的基准测试,看看 Bash 工具还是 MCP 服务器更适合特定任务。简而言之:如果你用心设计,两者都可以高效。
不幸的是,许多最流行的 MCP 服务器对于特定任务来说效率很低。它们需要覆盖所有基础,这意味着它们提供大量带有冗长描述的工具,消耗大量上下文。
扩展现有 MCP 服务器也很难。你可以 checkout 源代码并修改它,但然后你必须和你的 Agent 一起理解代码库。
MCP 服务器也不可组合。MCP 服务器返回的结果必须通过 Agent 的上下文才能持久化到磁盘或与其他结果组合。
我是个简单的人,所以我喜欢简单的东西。Agent 可以很好地运行 Bash 和写代码。Bash 和代码是可组合的。那么,有什么比让你的 Agent 直接调用 CLI 工具和写代码更简单的呢?这不是什么新鲜事。我们从一开始就一直在这样做。我只是想说服你,在很多情况下,你不需要甚至不想要一个 MCP 服务器。
让我用一个常见的 MCP 服务器用例来说明这一点:浏览器开发者工具。
我的浏览器 DevTools 用例
我的用例是和我的 Agent 一起处理 Web 前端,或者滥用我的 Agent 让它变成一个小小的刮削黑客小子,这样我就可以刮掉世界上所有的数据。对于这两个用例,我只需要一套极简的工具:
- 启动浏览器,可选使用我的默认配置文件,这样我就已经登录了
- 导航到一个 URL,在当前标签页或新标签页中
- 在当前页面上下文中执行 JavaScript
- 截取视口的屏幕截图
如果我的用例需要额外的特殊工具,我希望能快速让我的 Agent 为我生成并将其与其他工具集成。
Agent 常用浏览器 DevTools 的问题
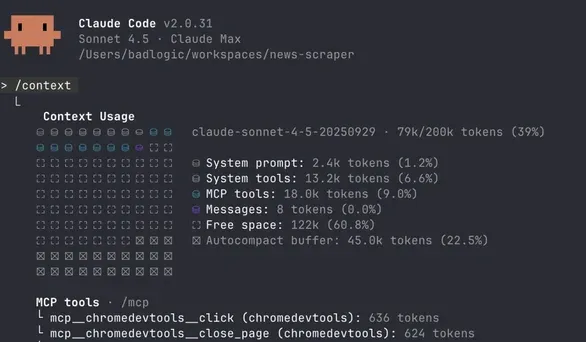
人们会为我上面说明的用例推荐 Playwright MCP 或 Chrome DevTools MCP。两者都很好,但它们需要覆盖所有基础。Playwright MCP 有 21 个工具,使用 13.7k Token(Claude 上下文的 6.8%)。Chrome DevTools MCP 有 26 个工具,使用 18.0k Token(9.0%)。这么多工具会让你的 Agent 感到困惑,特别是与其他 MCP 服务器和内置工具结合时。
使用这些工具也意味着你会遇到可组合性问题:任何输出都必须通过你的 Agent 的上下文。你可以通过使用子 Agent 来某种程度上解决这个问题,但然后你会引入子 Agent 带来的所有问题。
拥抱 Bash(和代码)
这是我的极简工具集,通过 README.md 来说明:
# Browser Tools
用于协作站点探索的极简 CDP 工具。
## Start Chrome
```bash
./start.js # 全新配置文件
./start.js --profile # 复制你的配置文件(Cookie、登录信息)
```在 :9222 上启动 Chrome 并开启远程调试。
Navigate
./nav.js https://example.com
./nav.js https://example.com --new导航当前标签页或打开新标签页。
Evaluate JavaScript
./eval.js 'document.title'
./eval.js 'document.querySelectorAll("a").length'在活动标签页中执行 JavaScript(异步上下文)。
Screenshot
./screenshot.js截取当前视口,返回临时文件路径。
这就是我提供给我的 Agent 的全部内容。这是几个覆盖了我的用例所有基础的工具。每个工具都是一个简单的 Node.js 脚本,使用 [Puppeteer Core](https://pptr.dev/)。通过阅读那个 README,Agent 知道可用的工具、何时使用它们,以及如何通过 Bash 使用它们。
当我启动一个 Agent 需要与浏览器交互的会话时,我只是让它完整读取那个文件,这就是它高效工作所需的全部。让我们看看它们的实现,了解这实际上是多么少的代码。
### 启动工具
Agent 需要能够启动一个新的浏览器会话。对于抓取任务,我经常想使用我的实际 Chrome 配置文件,这样我就已经在所有地方登录了。这个脚本要么将我的 Chrome 配置文件 rsync 到一个临时文件夹(Chrome 不允许在默认配置文件上调试),要么全新启动:
```javascript
#!/usr/bin/env node
import { spawn, execSync } from "node:child_process";
import puppeteer from "puppeteer-core";
const useProfile = process.argv[2] === "--profile";
if (process.argv[2] && process.argv[2] !== "--profile") {
console.log("Usage: start.ts [--profile]");
console.log("\nOptions:");
console.log(" --profile Copy your default Chrome profile (cookies, logins)");
console.log("\nExamples:");
console.log(" start.ts # Start with fresh profile");
console.log(" start.ts --profile # Start with your Chrome profile");
process.exit(1);
}
// 杀死现有的 Chrome
try {
execSync("killall 'Google Chrome'", { stdio: "ignore" });
} catch {}
// 等待进程完全结束
await new Promise((r) => setTimeout(r, 1000));
// 设置配置文件目录
execSync("mkdir -p ~/.cache/scraping", { stdio: "ignore" });
if (useProfile) {
// 使用 rsync 同步配置文件(后续运行更快)
execSync(
'rsync -a --delete "/Users/badlogic/Library/Application Support/Google/Chrome/" ~/.cache/scraping/',
{ stdio: "pipe" },
);
}
// 在后台启动 Chrome(分离模式,以便 Node 可以退出)
spawn(
"/Applications/Google Chrome.app/Contents/MacOS/Google Chrome",
["--remote-debugging-port=9222", `--user-data-dir=${process.env["HOME"]}/.cache/scraping`],
{ detached: true, stdio: "ignore" },
).unref();
// 尝试连接,等待 Chrome 准备就绪
let connected = false;
for (let i = 0; i < 30; i++) {
try {
const browser = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
await browser.disconnect();
connected = true;
break;
} catch {
await new Promise((r) => setTimeout(r, 500));
}
}
if (!connected) {
console.error("✗ Failed to connect to Chrome");
process.exit(1);
}
console.log(`✓ Chrome started on :9222${useProfile ? " with your profile" : ""}`);Agent 只需要知道使用 Bash 来运行 start.js 脚本,要么带 --profile,要么不带。
导航工具
一旦浏览器运行,Agent 需要导航到 URL,可以在新标签页或活动标签页中。这正是导航工具提供的:
#!/usr/bin/env node
import puppeteer from "puppeteer-core";
const url = process.argv[2];
const newTab = process.argv[3] === "--new";
if (!url) {
console.log("Usage: nav.js <url> [--new]");
console.log("\nExamples:");
console.log(" nav.js https://example.com # Navigate current tab");
console.log(" nav.js https://example.com --new # Open in new tab");
process.exit(1);
}
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
if (newTab) {
const p = await b.newPage();
await p.goto(url, { waitUntil: "domcontentloaded" });
console.log("✓ Opened:", url);
} else {
const p = (await b.pages()).at(-1);
await p.goto(url, { waitUntil: "domcontentloaded" });
console.log("✓ Navigated to:", url);
}
await b.disconnect();执行 JavaScript 工具
Agent 需要执行 JavaScript 来读取和修改活动标签页的 DOM。它写的 JavaScript 在页面上下文中运行,所以它不需要和 Puppeteer 本身打交道。它只需要知道如何使用 DOM API 写代码,而它当然知道如何做到:
#!/usr/bin/env node
import puppeteer from "puppeteer-core";
const code = process.argv.slice(2).join(" ");
if (!code) {
console.log("Usage: eval.js 'code'");
console.log("\nExamples:");
console.log(' eval.js "document.title"');
console.log(' eval.js "document.querySelectorAll(\\'a\\').length"');
process.exit(1);
}
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
const p = (await b.pages()).at(-1);
if (!p) {
console.error("✗ No active tab found");
process.exit(1);
}
const result = await p.evaluate((c) => {
const AsyncFunction = (async () => {}).constructor;
return new AsyncFunction(`return (${c})`)();
}, code);
if (Array.isArray(result)) {
for (let i = 0; i < result.length; i++) {
if (i > 0) console.log("");
for (const [key, value] of Object.entries(result[i])) {
console.log(`${key}: ${value}`);
}
}
} else if (typeof result === "object" && result !== null) {
for (const [key, value] of Object.entries(result)) {
console.log(`${key}: ${value}`);
}
} else {
console.log(result);
}
await b.disconnect();截图工具
有时 Agent 需要对页面有一个视觉印象,所以我们自然想要一个截图工具:
#!/usr/bin/env node
import { tmpdir } from "node:os";
import { join } from "node:path";
import puppeteer from "puppeteer-core";
const b = await puppeteer.connect({
browserURL: "http://localhost:9222",
defaultViewport: null,
});
const p = (await b.pages()).at(-1);
if (!p) {
console.error("✗ No active tab found");
process.exit(1);
}
const timestamp = new Date().toISOString().replace(/[:.]/g, "-");
const filename = `screenshot-${timestamp}.png`;
const filepath = join(tmpdir(), filename);
await p.screenshot({ path: filepath });
console.log(filepath);
await b.disconnect();这将截取活动标签页当前视口的截图,将其写入临时目录中的 .png 文件,并将文件路径输出给 Agent,然后 Agent 可以反过来读取它并使用其视觉能力来”看到”图像。
好处
那么与我上面提到的 MCP 服务器相比,这有什么优势呢?首先,我可以在需要时引入 README,而不是在每个会话中都为它付出代价。这与 Anthropic 最近引入的技能功能非常相似。除了它更加临时化,并且可以与任何编码 Agent 一起工作。我需要做的就是指示我的 Agent 读取 README 文件。
旁注:在 Anthropic 发布他们的技能系统之前,包括我自己在内的很多人都已经使用过这种设置。你可以在我的”Prompts are Code”博客文章或我的小 sitegeist.ai 中看到类似的东西。Armin 之前也谈到过 Bash 和代码相比 MCP 的力量。Anthropic 的技能添加了渐进式披露(喜欢),并且它们让非技术受众可以跨几乎所有产品使用它们(也喜欢)。
说到 README,与上面提到的 MCP 服务器的 13000 到 18000 Token 相比,这个 README 有惊人的 225 Token。这种效率来自于模型知道如何写代码和使用 Bash。我通过严重依赖它们现有的知识来节省上下文空间。
这些简单工具也是可组合的。Agent 可以决定将它们保存到文件以供以后处理,而不是将调用的输出读入上下文,可以是它自己或代码处理。Agent 还可以在单个 Bash 命令中轻松链接多个调用。
如果我发现工具的输出 Token 效率不高,我可以直接更改输出格式。这是很难或不可能做到的,取决于你使用什么 MCP 服务器。
而且为我的需求添加新工具或修改现有工具 ridiculously 容易。让我来说明。
添加选择工具
当 Agent 和我试图为特定站点想出一个抓取方法时,如果我能够直接通过点击它们来向它指出 DOM 元素,通常会更高效。为了让这变得超级容易,我可以直接构建一个选择器。这是我添加到 README 中的内容:
## Pick Elements
```bash
./pick.js "Click the submit button"
```交互式元素选择器。点击选择,Cmd/Ctrl+点击多选,Enter 完成。
这是代码:
(由于篇幅原因,代码部分在此省略,与原文一致)
每当我认为我直接点击一堆 DOM 元素比让 Agent 弄清楚 DOM 结构更快时,我可以告诉它使用选择工具。它超级高效,并允许我立即构建抓取器。如果站点的 DOM 布局发生变化,调整抓取器也很棒。
如果你难以理解这个工具的作用,别担心,我会在博客文章的结尾放一个视频,你可以看到它的实际操作。在我们看那个之前,让我向你展示一个额外的工具。
## 添加 Cookie 工具
在我最近的一次抓取冒险中,我需要那个站点的 HTTP-only Cookie,这样确定性抓取器就可以假装是我。执行 JavaScript 工具无法处理这个,因为它在页面上下文中执行。但我告诉 Claude 创建那个工具、将其添加到 readme 并开始工作,花了不到一分钟。

这比调整、测试和调试现有 MCP 服务器容易得多。
## 一个人为的例子
让我用一个人为的例子来说明这套工具的用法。我着手构建一个简单的 Hacker News 抓取器,我基本上为 Agent 选择 DOM 元素,基于这些元素,它然后可以编写一个极简的 Node.js 抓取器。这就是实际操作的样子。我加速了几个 Claude 平时很慢的部分。
真实世界的抓取任务看起来会稍微复杂一些。而且,对于像 Hacker News 这样简单的站点,这样做也没有意义。但你懂我的意思。
最终 Token 统计:

## 让它跨 Agent 可重用
这是我如何设置的,以便我可以与 Claude Code 和其他 Agent 一起使用它。我在我的主目录中有一个文件夹 `agent-tools`。然后我将各个工具的仓库,比如上面的浏览器工具仓库,克隆到该文件夹中。然后我设置一个别名:
```bash
alias cl="PATH=$PATH:/Users/badlogic/agent-tools/browser-tools:<other-tool-dirs> && claude --dangerously-skip-permissions"这样所有脚本都可用于 Claude 的会话,但不会污染我的正常环境。我还为每个脚本添加完整的工具名称前缀,例如 browser-tools-start.js,以消除名称冲突。我还在 README 中添加了一句话告诉 Agent 所有脚本都全局可用。这样,Agent 不必仅仅为了调用工具脚本而更改其工作目录,在这里和那里节省了一些 Token,并减少 Agent 被不断的工作目录更改弄糊涂的机会。
最后,我通过 /add-dir 将 Agent 工具目录作为工作目录添加到 Claude Code,这样我就可以使用 @README.md 来引用特定工具的 README 文件并使其进入 Agent 的上下文。我更喜欢这一点而不是 Anthropic 的技能自动发现,我发现它在实践中不能可靠地工作。这也意味着我又节省了几个 Token:Claude Code 将它能找到的所有技能的所有 frontmatter 注入到系统提示词(或第一个用户消息,我忘了,见 https://cchistory.mariozechner.at)
总结
构建这些工具 ridiculously 容易,给你所需的所有自由,并让你、你的 Agent 和你的 Token 使用高效。你可以在 GitHub 上找到浏览器工具。
这个一般原则可以应用于任何有某种代码执行环境的框架。跳出 MCP 框框思考,你会发现这比你必须遵循 MCP 的更严格结构强大得多。
然而,伴随着强大的力量而来的是巨大的责任。你必须自己想出一个如何构建和维护这些工具的结构。Anthropic 的技能系统可能是做到这一点的一种方法,尽管那对其他 Agent 来说不太可转移。或者你遵循我上面的设置。