本文译自 How to Scale a System from 0 to 10 million+ Users。作者曾在大公司工作,服务过数百万请求的系统,也从零开始扩展过自己的创业公司。文章揭示了一个关键洞见:不应从一开始就过度工程化。先从简单开始,识别瓶颈,再增量扩展。
扩展是一个复杂的话题,但在大公司工作过服务数百万请求的系统,也从零开始扩展过自己的创业公司(AlgoMaster.io)之后,我意识到大多数系统在成长过程中会经历一组惊人相似的阶段。
关键洞见是:不应从一开始就过度工程化。先从简单开始,识别瓶颈,再增量扩展。
在本文中,我将带你了解系统从 0 到 1000 万用户及以上的 7 个扩展阶段。每个阶段都解决不同增长点出现的特定瓶颈。你将学到添加什么、何时添加、为什么有帮助,以及涉及的权衡取舍。
无论你是在构建应用或网站、准备系统设计面试,还是只是好奇大规模系统如何工作,理解这种演进都会锐化你思考架构的方式。
免责声明:本文中提到的用户范围和数字是近似的,旨在说明扩展之旅。实际阈值会根据你的产品、工作负载特征和流量模式而有所不同。
第 1 阶段:单服务器(0-100 用户)
当你刚刚开始时,你的首要任务很简单:发布一些东西并验证你的想法。在这个阶段过早优化会在你可能永远不会面对的问题上浪费时间和金钱。
最简单的架构将所有内容都放在单服务器上:你的 Web 应用程序、数据库,以及任何后台作业都运行在同一台机器上。
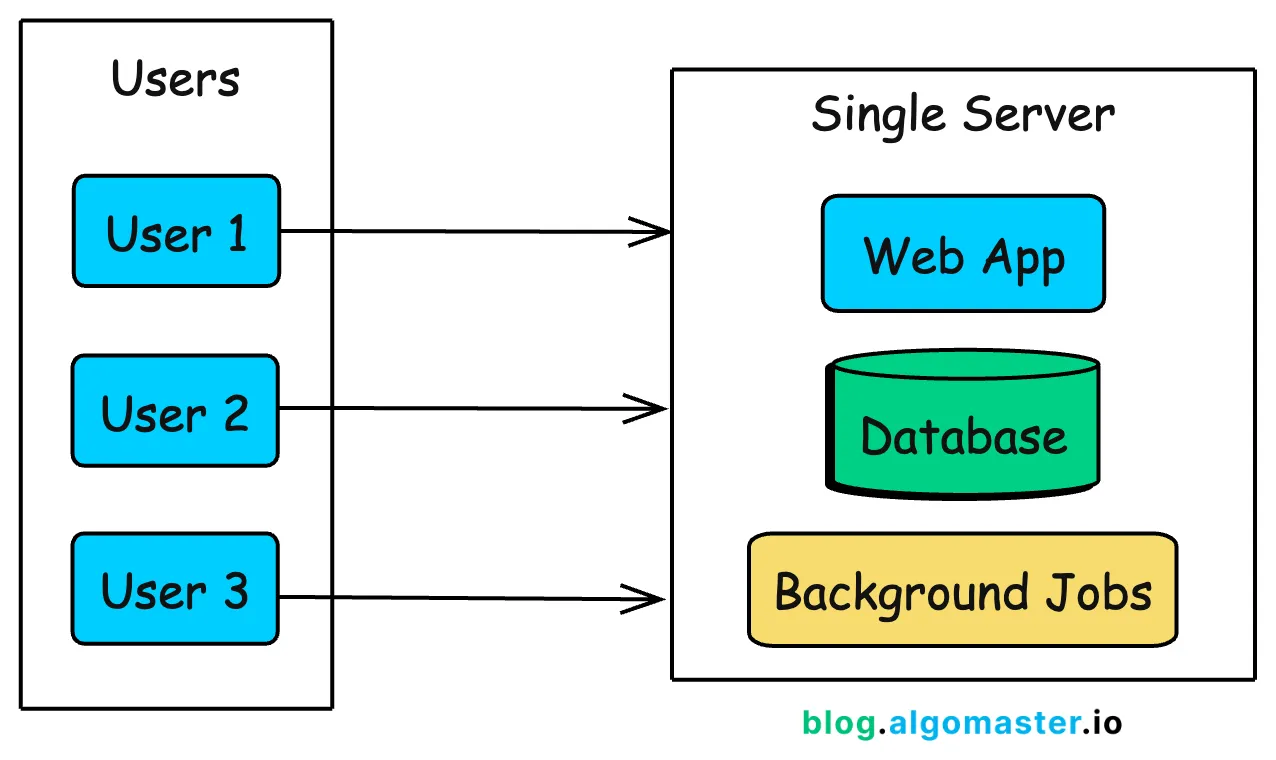
Instagram 就是这样开始的。当 Kevin Systrom 和 Mike Krieger 在 2010 年发布第一个版本时,第一天就有 25,000 人注册。
他们没有提前过度工程化。凭借一个小团队和简单的设置,他们响应实际需求进行扩展,随着使用量的增长添加容量,而不是为假设的未来流量构建。
这个架构是什么样的
实际上,单服务器设置意味着:
- 一个 Web 框架(Django、Rails、Express、Spring Boot)处理 HTTP 请求
- 一个数据库(PostgreSQL、MySQL)存储你的数据
- 后台作业处理(Sidekiq、Celery)用于异步任务
- 也许前面有一个反向代理(Nginx)用于 SSL 终止
所有这些都运行在一个虚拟机上。你的云提供商账单对于一个基本的 VPS(DigitalOcean Droplet、AWS Lightsail、Linode)可能是每月 20-50 美元。
为什么这在早期阶段有效
在这个阶段,简单性是你最大的优势:
- 快速部署:一台服务器意味着一个部署、监控和调试的地方。
- 低成本:单个每月 20-50 美元的虚拟专用服务器(VPS)可以轻松处理你的前 100 个用户。
- 更快迭代:没有分布式系统的复杂性来拖慢开发速度。
- 更容易调试:所有日志都在一个地方,组件之间没有网络问题。
- 全栈可见性:你可以端到端追踪每个请求,因为只有一条执行路径。
你正在做的权衡
这种简单性伴随着你明知接受的权衡:

何时继续前进
当你注意到这些迹象时,你就知道是时候演进了:
- 数据库查询在峰值流量期间变慢:应用程序和数据库争夺相同的 CPU 和内存。一个繁重的查询会拖慢每个人的 API 延迟。
- 服务器 CPU 或内存持续超过 70-80%:你正在接近单台机器可以可靠处理的极限。
- 部署需要重启并导致停机:即使是短暂的中断也变得明显,用户开始抱怨。
- 后台作业崩溃会拖垮 Web 服务器:没有隔离,非面向用户的工作会影响用户体验。
- 你甚至无法承受短暂的停机时间:你的产品已经变得足够重要,即使维护窗口也不再可接受。
在某个时刻,服务器开始在做所有事情的重压下挣扎。这时就是你进行第一次架构拆分的时候了。
第 2 阶段:分离数据库(100-1,000 用户)
随着流量增长,你的单服务器开始挣扎。Web 应用程序和数据库争夺相同的 CPU、内存和磁盘 I/O。单个繁重的查询可能会导致延迟飙升并拖慢每个 API 响应。
第一个扩展步骤很简单:将数据库与应用服务器分离。
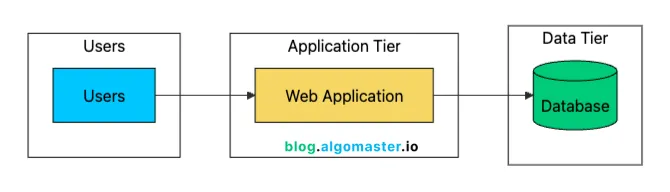
这种两层架构给你几个直接的好处:
- 资源隔离:应用程序和数据库不再争夺 CPU/内存。每个都可以使用其分配资源的 100%。
- 独立扩展:升级数据库(更多 RAM、更快的存储)而不接触应用服务器。
- 更好的安全性:数据库服务器可以位于私有网络中,不暴露在互联网上。
- 专门优化:针对其特定工作负载调整每台服务器。应用服务器使用高 CPU,数据库使用高 I/O。
- 备份简单性:数据库备份不影响应用程序性能,因为它们在不同的机器上运行。
托管数据库服务
在这个阶段,大多数团队使用托管数据库,如 Amazon RDS、Google Cloud SQL、Azure Database 或 Supabase(我在 algomaster.io 使用 Supabase)。
托管服务通常处理:
- 自动备份(每日快照、时间点恢复)
- 安全补丁和更新
- 基本监控和警报
- 可选的只读副本(稍后会介绍)
- 故障转移到备用实例
一旦你考虑工程时间,自托管和托管之间的成本差异通常很小。托管 PostgreSQL 实例可能比原始 VM 每月贵 50-100 美元,但每周可以节省数小时的维护时间。这些时间更好地用于发布功能。
自管理数据库的主要原因是:
- 超大规模的成本优化
- 托管服务不支持的特定配置
- 禁止托管服务的合规要求
- 你正在构建数据库产品
对于大多数团队来说,托管服务是正确的选择,直到你的数据库账单增长到每月数千美元。
连接池
这个阶段经常被忽视的一个改进是连接池。每个数据库连接都会消耗资源:
- 连接状态的内存(PostgreSQL 中每个连接通常 5-10MB)
- 应用程序和数据库服务器上的文件描述符
- 连接管理的 CPU 开销
打开新连接也很昂贵。在 TCP 握手、SSL 协商和数据库身份验证之间,每个请求可能会增加 50-100 毫秒的开销。
像 PgBouncer(用于 PostgreSQL)这样的连接池器保持一小组数据库连接打开,并在请求之间重用它们。
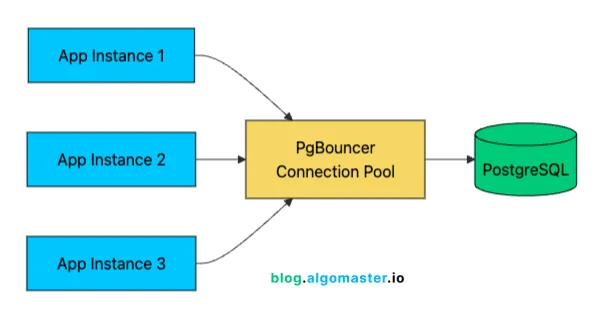
有 1,000 个用户时,你可能有 100 个并发连接命中你的 API。没有池化,这就是 100 个消耗资源的数据库连接。有了池化,20-30 个实际数据库连接可以通过连接重用有效地服务这 100 个应用程序连接。
连接池模式:
- 会话池化:每个客户端连接一个池连接(最兼容,最低效)
- 事务池化:每个事务后连接返回到池(大多数应用的最佳平衡)
- 语句池化:每个语句后连接返回(最高效,但可能会破坏功能)
大多数应用程序使用事务池化效果最好,这通常将连接效率提高了 3-5 倍。
网络延迟注意事项
分离数据库会引入网络延迟。当应用程序和数据库在同一台机器上时,“网络”延迟本质上为零(环回接口)。现在每个查询增加 0.1-1 毫秒的网络往返时间。
对于大多数应用程序,这可以忽略不计。但如果你的代码每个请求进行数百个数据库查询(这是一种反模式,但很常见),这种延迟会累积起来。解决方案不是把它们放回同一台机器,而是优化你的查询模式:
- 尽可能批量查询
- 使用 JOIN 而不是 N+1 查询模式
- 缓存频繁访问的数据
- 使用连接池来避免重复的连接设置开销
有了数据库在自己的服务器上,你就为自己争取到了增长空间。但你也创建了一个新的单点故障:应用服务器现在是薄弱环节。当它宕机时,或者当它根本无法跟上需求时,会发生什么?