云原生技术体系
最近在了解云计算相关的知识,发现云原生这个概念很重要,所以结合读的博客以及书籍简单记录下。云原生是一个不断丰富的理念和技术体系,Pivotal 是云原生应用的提出者,并推出了 Pivotal Cloud Foundry 云原生应用平台和 Spring 开源 Java 开发框架,成为云原生应用架构中先驱者和探路者。2015年Google主导成立了云原生计算基金会(CNCF),起初CNCF对云原生(Cloud Native)的定义包含以下三个方面:应用容器化;面向微服务架构;应用支持容器的编排调度。随着容器和微服务的崛起,云原生展现出强大的生命力。
什么是云原生
云原生是一个不断丰富的理念和技术体系,Pivotal 是云原生应用的提出者,并推出了 Pivotal Cloud Foundry 云原生应用平台和 Spring 开源 Java 开发框架,成为云原生应用架构中先驱者和探路者。2015年Google主导成立了云原生计算基金会(CNCF),起初CNCF对云原生(Cloud Native)的定义包含以下三个方面:应用容器化;面向微服务架构;应用支持容器的编排调度。随着容器和微服务的崛起,云原生展现出强大的生命力。 到了2018年,随着云原生生态的不断壮大,所有主流云计算供应商都加入了该基金会,CNCF基金会中的会员以及容纳的项目越来越多,该定义已经限制了云原生生态的发展,CNCF对云原生进行了重新定位:云原生技术有利于各组织在公有云、私有云和混合云等新型动态环境中,构建和运行可弹性扩展的应用。
应用容器化
容器不同于虚拟化的实现方式,占用更少的系统资源,有效地提升了数据中心的资源利用率,同时利用容器快速弹性等特性,使业务系统可以灵活扩展,架构演进至微服务架构。对于轻量级虚拟机,虚拟机管理程序对硬件设备进行抽象处理,而容器只对操作系统进行抽象处理,容器有自己的文件系统、CPU和内存,意味着容器能像虚拟机一样独立运行,却占用更少的资源,极大地提高了资源利用率。
容器典型应用场景
- 轻量化:容器相比于虚拟机提供了更小的镜像,更快的部署速度。容器轻量化特性非常适合需要批量快速上线的应用或快速规模弹缩应用,如互联网web应用。
- 性能高、资源省:相比虚拟化,接近物理机的性能,系统开销大幅降低,资源利用率高。容器的高性能特性非常适合对计算资源要求较高的应用,如大数据和高性能计算应用。
- 跨平台:容器技术实现了OS解耦,应用一次打包,可到处运行。容器的跨平台能力非常适合作为DevOps的下层封装平台,实现应用的CI/CD流水线;容器应用可跨异构环境在不同云平台上部署。
- 细粒度:容器本身的“轻”和“小”的特性非常匹配细粒度服务对资源的诉求,与微服务化技术的发展相辅相成,可作为分布式微服务应用的最佳载体。
用Docker实现DevOps
Docker为实现DevOps的四个技术基础技术提供了完善的解决方案:
- 分布式的开发环境:Docker的分层文件系统机制,使不同的开发人员完全独立地进行开发,并最终进行文件挂载的方式搭建应用开发程序,使开发人员之间的影响最小,实现开发敏捷。
- 标准化的运行环境:Docker Image可以在各种支持Docker的开发、测试和生产环境中运行,而屏蔽不同环境间软硬件的差异。
- 丰富的应用仓库:在Docker Hub和私有镜像仓库中存储着多种类型的Docker Image,利用仓库来存储Docker镜像,快速搭建应用所需的标准化环境。
- 持续的自动化部署:各种Docker的编排工具,如Mesos、Kubernates工具能够支持应用生命周期管理,支持服务发现、负载均衡和灰度升级等,满足运维的应用不停机升级。
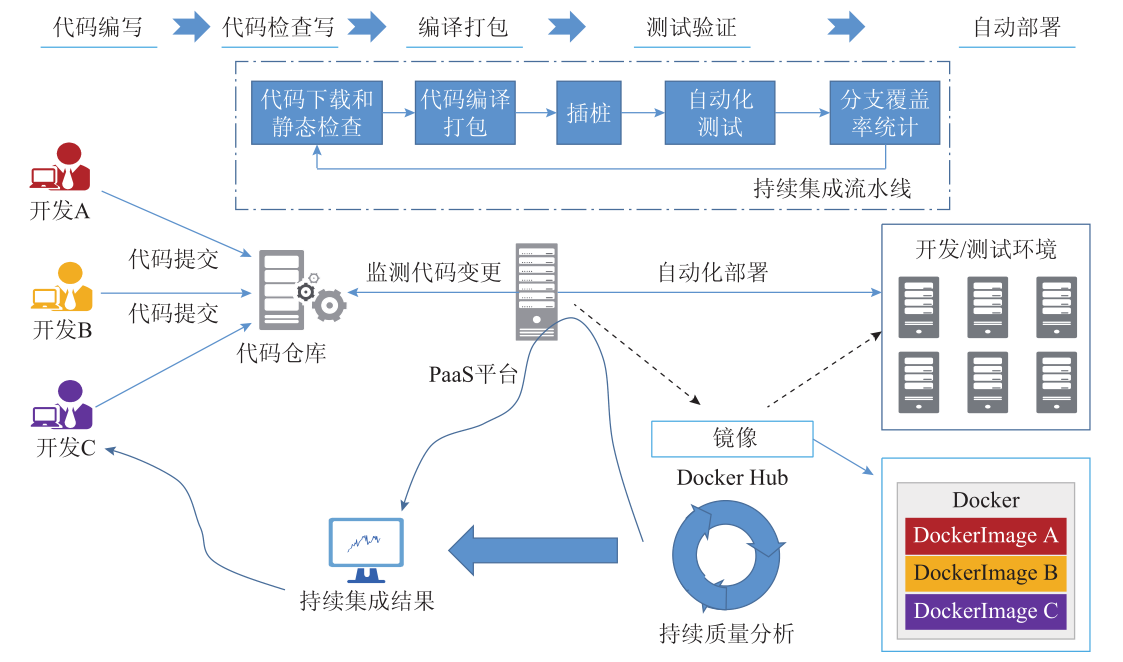
面向微服务架构
微服务是一种软件架构模式,此模式下应用被分解为一系列相互独立、边界明确、自主完成单一的任务的服务,服务之间解耦,可独立替换、升级和伸缩,服务间通过语言无关的轻量级接口,如网络通信(RPC、HTTP等)、消息队列等进行协同。 微服务架构将应用解耦分拆为小粒度服务模块,容器的轻量化可为微服务提供更细粒度的资源供给,有效地利用资源。服务启动快和弹缩快,也能更好地应对单服务和系统突发式的业务访问。
微服务开发框架
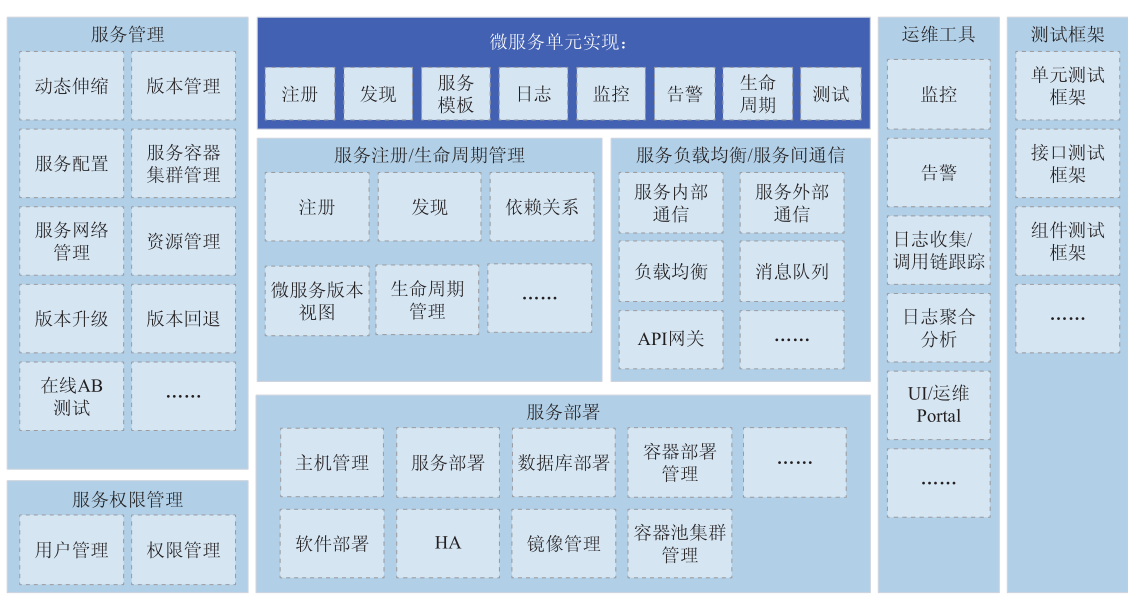 微服务是一个独立完整的服务化实体单元,在云软件系统中,完成一个应用,需要多个微服务的协同配合,同时也引入了对于微服务的管理和微服务的维护等一系列的要求。实践中,一般通过提供统一的微服务开发框架,来实现这些要求。
微服务开发框架应包含的内容为微服务注册、微服务发现、微服务代码框架模板、微服务日志、微服务监控…(Spring Cloud提供了比较全面的微服务开发支持,虽然存在一定的编程语言限制(仅Java))
微服务是一个独立完整的服务化实体单元,在云软件系统中,完成一个应用,需要多个微服务的协同配合,同时也引入了对于微服务的管理和微服务的维护等一系列的要求。实践中,一般通过提供统一的微服务开发框架,来实现这些要求。
微服务开发框架应包含的内容为微服务注册、微服务发现、微服务代码框架模板、微服务日志、微服务监控…(Spring Cloud提供了比较全面的微服务开发支持,虽然存在一定的编程语言限制(仅Java))
PaaS对微服务架构的支持
- 以Docker容器来封装微服务,因为每个微服务采用的开发语言都不一样,用Docker封装微服务,实现了应用与底层运行平台的解耦,提高了应用的灵活性。
- PasS平台实时监控每个容器的状态,保证每个微服务运行的实例数量,实现了微服务的高可用性。
- 用户可以定义基于CPU/内存的负载、定时或者周期等策略,自动地调整微服务的实例数量,实现应对负载变化的弹性伸缩。
- PaaS可以滚动升级容器应用,保证升级期间业务不掉线,与开发测试部署流水线集成,可以实现微服务的快速迭代升级,必要时可以回滚。
- PaaS的应用编排和调度功能使部署大规模的微服务成为可能。
- PaaS内部的负载均衡/代理模块用来将同一个微服务的多个实例集合起来对外提供服务。
- 服务治理模块提供了服务注册、发现和监控以及调用链分析等功能,能够快速将各个微服务集成在一起,对外提供高可靠、按需取用的云服务。
Kubernetes
Kubernetes是Google开源的容器集群管理系统,提供应用部署、维护、扩展机制等功能,利用Kubernetes能方便地管理跨机器运行容器化的应用,架构设计上Kubernetes采用典型的主——从结构,希望构建为一个可插拔组件和层的集合,具有可替换的调度器、控制器、存储系统。主要功能如下:
- 使用Docker对应用程序打包(Package)、实例化(Instantiate)、运行(Run) ;
- 以集群的方式运行、管理跨机器的容器;
- 解决Docker跨机器容器之间的通讯问题;
Kubernetes的自我修复机制使得容器集群总是运行在用户期望的状态。
Kubernetes对象模型
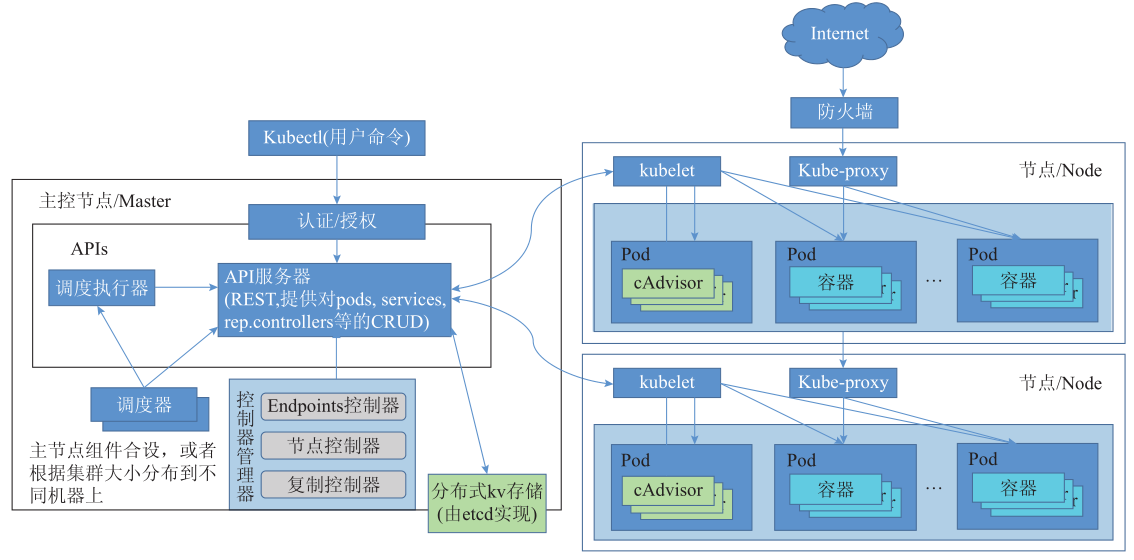 集群(Cluster):物理机或者VM的集合,是应用运行的载体。
节点(Node):可以用来创建容器集(Pod)的一个特定的物理机或者VM。
容器集(Pod):Kubernetes中的最小资源分配单位,一个Pod是一组共生容器的集合。共生指一个Pod中的容器只能在同一个节点上。
服务(Service):一组Pod集合的抽象,比如一组Web服务器;服务具有一个固定的IP或者DNS,从而使得服务的访问者不用关心服务后面具体Pod的IP地址。
复制控制器(RC,ReplicationController):Kubernetes通过RC确保一个Pod在任何时候都维持在期望的副本数。当Pod期望的副本数和实际运行的副本数不符时,RC调用Kubernetes接口创建或者删除Pod。
标签(Lable),标签选择器(LabelSelector):即与一个资源关联的键值对,方便用户管理和选择资源。资源可以是集群、节点、Pod、RC等。
集群(Cluster):物理机或者VM的集合,是应用运行的载体。
节点(Node):可以用来创建容器集(Pod)的一个特定的物理机或者VM。
容器集(Pod):Kubernetes中的最小资源分配单位,一个Pod是一组共生容器的集合。共生指一个Pod中的容器只能在同一个节点上。
服务(Service):一组Pod集合的抽象,比如一组Web服务器;服务具有一个固定的IP或者DNS,从而使得服务的访问者不用关心服务后面具体Pod的IP地址。
复制控制器(RC,ReplicationController):Kubernetes通过RC确保一个Pod在任何时候都维持在期望的副本数。当Pod期望的副本数和实际运行的副本数不符时,RC调用Kubernetes接口创建或者删除Pod。
标签(Lable),标签选择器(LabelSelector):即与一个资源关联的键值对,方便用户管理和选择资源。资源可以是集群、节点、Pod、RC等。
Kubernetes容器调度
Kubernetes的调度器是Kubernetes众多组件的一部分,独立于API服务器之外。调度器本身是可插拔的,任何理解调度器和API服务器之间调用关系的工程师都可以编写定制的调度器。
Kubernetes的调度器和API服务器是异步工作的,他们之间通过HTTP通讯。调度器通过和API服务器建立List&Watch连接来获取调度过程中需要使用的集群状态信息,例如节点的状态、Service的状态(用于Service内Pod的反亲和)、Controller的状态、所有未调度和已经被调度的Pod的状态等。
Kubernetes的默认调度器工作步骤具体如下:
- 从待调度的Pod队列中取出一个Pod。
- 依次执行调度算法中配置的过滤函数(Predicate),得到一组符合Pod基本部署条件的节点的列表。过滤函数是一些“硬约束”,例如资源是否足够,Pod要求的Label是否满足等。
- 对上一步骤中得到的节点列表中的节点依次执行打分函数(Prioritizer),为各个节点进行打分。每个打分函数输出一个0~10之间的分数,最终一个节点的得分是各个打分函数输出分数的加权和(每个打分函数都有一个权值)。
- 对所有节点的得分由高到低排序,把排名第一的节点作为Pod的部署节点(如果不唯一则在所有得分最高的节点中随机选择一个),创建一个名为Binding的API对象,通知API服务器将被调度Pod的部署节点改为计算得到的节点。
Kubernetes应用管理
除了容器资源管理和调度,Kubernetes另外一个核心价值是提供了针对不同类型应用管理的API接口集合,这些API集合把针对不同类型应用的管理能力分别集成到Kubernetes平台中。 Kubernetes提供了针对如下不同类型应用的管理能力:
- Long-Running应用:一旦应用启动,会长时间运行,如Web业务。提供应用组件可靠性保障、副本数保障、灰度升级、多组件间负载均衡等能力。
- 批量任务:提供任务创建、删除、更新、查询、状态跟踪等能力。
- DaemonSet类型应用:当用户部署一个Daemonset类型的应用时,Kubernetes在集群的每个节点上都部署一个Pod。典型的例子如日志、监控的代理程序的部署。
- PetSet类型应用:用来支持用状态应用,比如一个MySQL集群。具体管理能力如允许PetSet类型应用的不同组件独立挂载容器存储卷,提供不同组件间通信机制等。
不同类型的应用,对应一个不同类型的控制管理器(Controller Manager)。用户可以根据自己的需求,开发特定类型的自定义控制管理器。