This is the first article focusing on RAG technology. Over the past year, RAG has become one of the most popular directions in large model applications, leading to the emergence of numerous related projects in the open-source community. These include SDK integrations for individual developers, enterprise-level frameworks, and general RAG applications. This article highlights projects with high maturity levels that specialize in RAG technology. Hence, innovative research projects like FlashRAG (an efficient, modular open-source toolkit for reproducing existing RAG methods and developing new algorithms) and GraphRAG (a graph-based RAG approach leveraging structural information between entities to enhance retrieval accuracy and context-aware responses) are not discussed here. Similarly, comprehensive frameworks such as LangChain, which include RAG processing modules, are also excluded.
1. LlamaIndex (Individual Development)
LlamaIndex is a data framework for your LLM applications
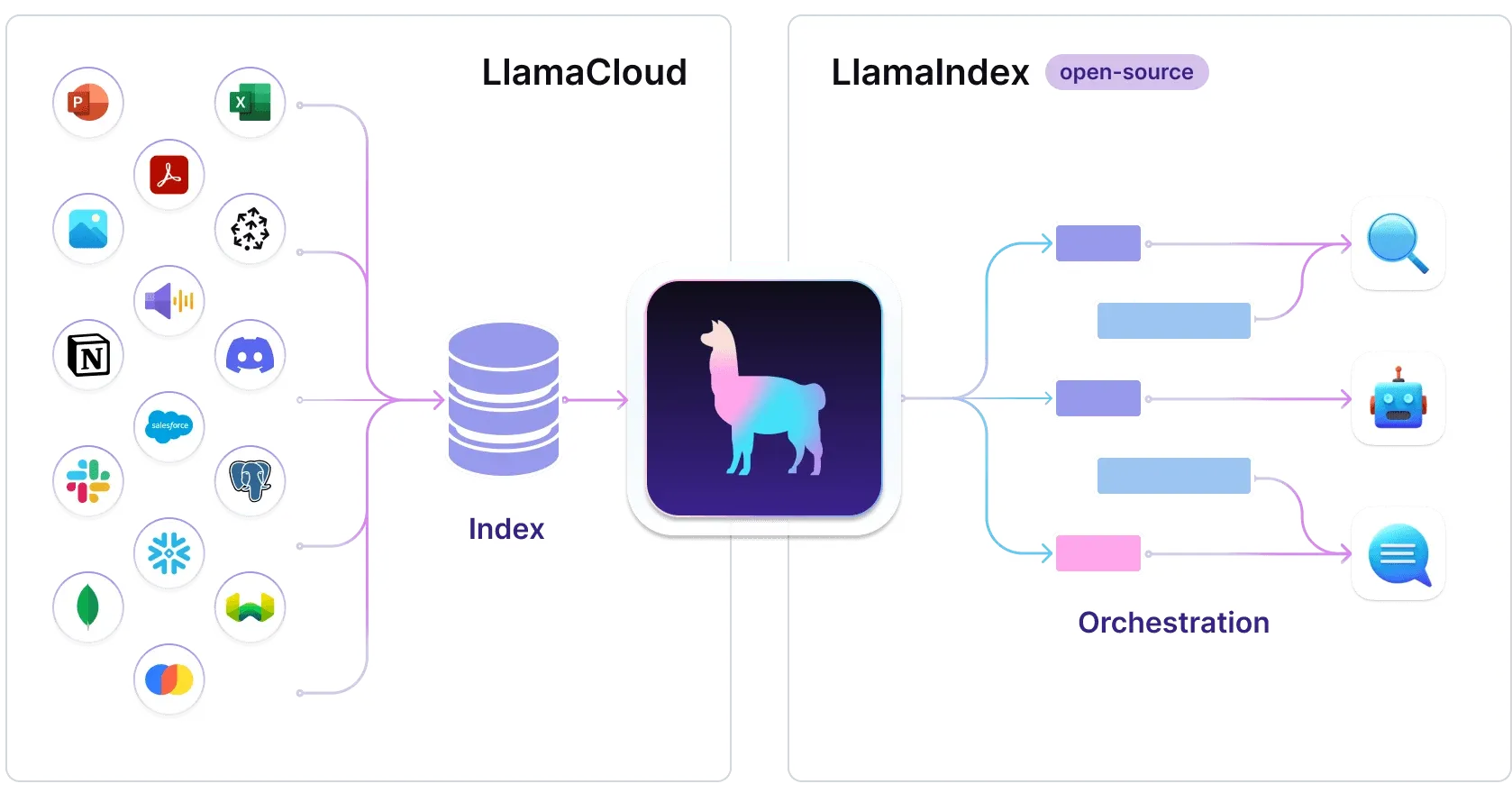
LlamaIndex is a versatile, efficient, and user-friendly RAG framework. As one of the earliest RAG frameworks, it supports numerous data sources and enjoys active community support. This was my first encounter with a RAG framework, which I adopted in August last year when developing a large model-assisted reading tool. Its interface design is excellent, offering a great user experience, and many RAG process optimization methods and standardized component definitions originate from this project’s blog.
LlamaIndex supports various data sources, including tabular data (such as DataFrames) that can be processed directly, suitable for scenarios requiring information extraction and usage from tables. Additionally, LlamaIndex is compatible with graph databases like NebulaGraph. Through integration, it can leverage graph database functionalities to store and manage knowledge graph data, effectively utilizing graph database query and analysis capabilities when building knowledge graph question-answering systems. LlamaIndex provides simple and easy-to-use APIs and tools, making it convenient for developers to quickly integrate into applications. The project also includes a series of tutorials and examples to help users understand and implement complex RAG technologies. If you’re a beginner looking to systematically master RAG technology from basic to advanced levels, this framework is recommended as a starting point.
2. Verba (Individual Development)
Verba is a modular RAG framework open-sourced by vector database provider Weaviate in March 2024.
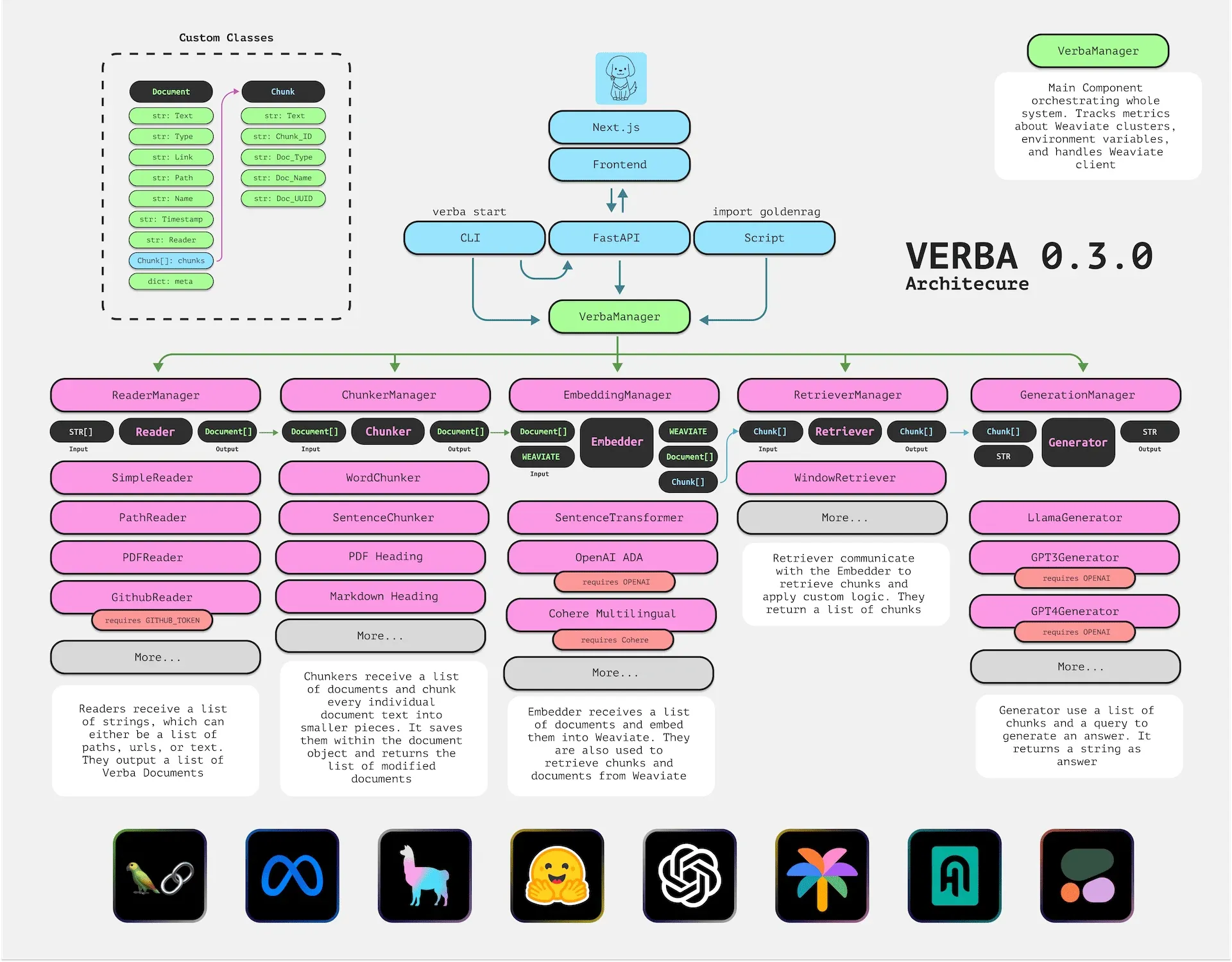
Verba supports rapid data upload and management, including CRUD (Create, Read, Update, Delete) functionality, and can display specific data sources and paragraphs used to generate answers. Verba’s architecture is divided into five key steps: ReaderManager, ChunkerManager, EmbeddingManager, RetrieveManager, and GenerationManager, with each step being customizable to suit different use cases.
Features:
- Generation Model Support: Supports various models including Ollama, HuggingFace, Cohere, Anthropic, and OpenAI.
- Embedding Support: Supports embedding models from Weaviate, SentenceTransformers, and VoyageAI.
- Data Source Support: Can process multiple data formats including PDF, CSV/XLSX, .DOCX files, import files from GitHub and GitLab, and even crawl web pages using Firecrawl.
- RAG Features: Includes hybrid search, autocomplete suggestions, filtering, customizable metadata, and asynchronous data preprocessing.
- Chunking Techniques: Supports various text chunking techniques, including token-based, sentence-based, semantic-based chunking, and special chunking methods for HTML, Markdown, code, and JSON files.
- Integration Support: Compatible with LangChain, Haystack, and LlamaIndex.
- Usability: Provides an intuitive user interface and simplified workflow, making it easy for users to import data, configure models and embeddings, and execute RAG tasks. It also offers detailed documentation and community support to help users get started quickly.
However, as a newly open-sourced project, it still needs improvement in community support and documentation completeness. When handling extremely large-scale data, performance and resource usage may need further optimization. If you’re using the Weaviate vector database, it’s recommended to use them together, as issue response is active.
For a detailed introduction to its design philosophy, see the official blog post 《Verba: Building Open-Source, Modular RAG Applications》
3. QAnything (Enterprise Deployment)
QAnything is a RAG-based local knowledge base Q&A system open-sourced by NetEase Youdao in January 2024.
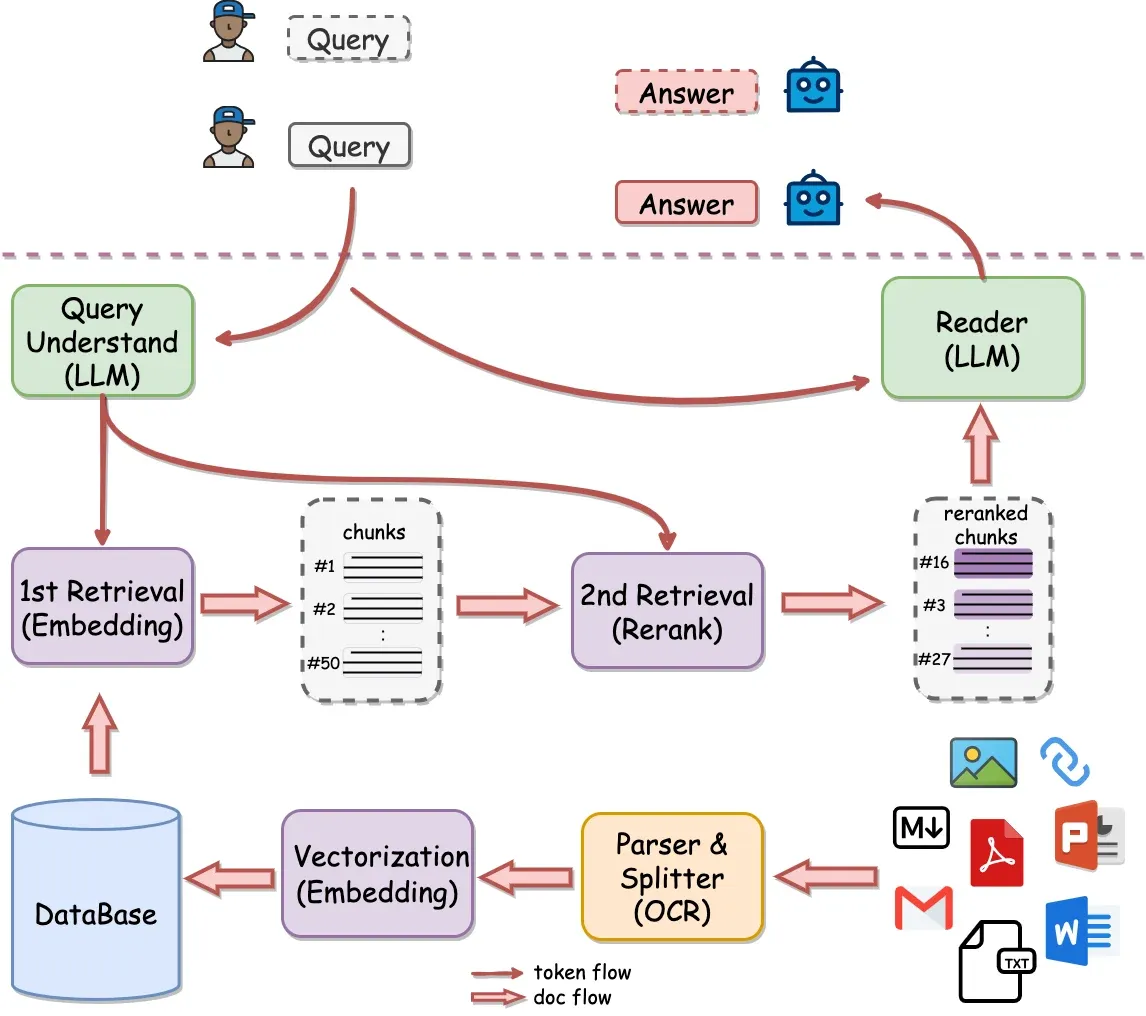
QAnything is a Q&A system based on local files and databases, supporting various file formats such as Word, PPT, Markdown, CSV, and web links. The system can also process images and tables in PDFs, perform web searches, manage FAQs, and create custom bots, offering high flexibility. QAnything emphasizes data security, supports offline deployment, and is suitable for users with strict data confidentiality requirements. It can efficiently handle large-scale Q&A tasks, ensuring query accuracy through a two-stage retrieval mechanism. As a complete RAG system, QAnything uses specially optimized proprietary BCEmbedding model and BCEmbedding-Reranker model at the backend, along with fine-tuned generation models. It includes a highly complete frontend interaction component and is designed to be easy to install and deploy, allowing quick startup without complex configuration.
It’s particularly important to note that QAnything uses the AGPL-3.0 open source license. This means if you plan to run your software as a network service and don’t want to open source it, you should avoid using this project. For users considering enterprise-level software development based on QAnything, it’s recommended to carefully evaluate the associated risks and consider purchasing a paid license if necessary.
For a detailed introduction to its design philosophy, see 《The Story Behind Youdao QAnything---Sharing Some Experience About RAG》
4. RAGFlow (Enterprise Deployment)
RAGFlow is an open-source RAG engine built on deep document understanding. RAGFlow can provide enterprises and individuals of various scales with a streamlined RAG workflow, combining large language models (LLMs) to provide reliable Q&A and well-founded references for various complex format data from users.
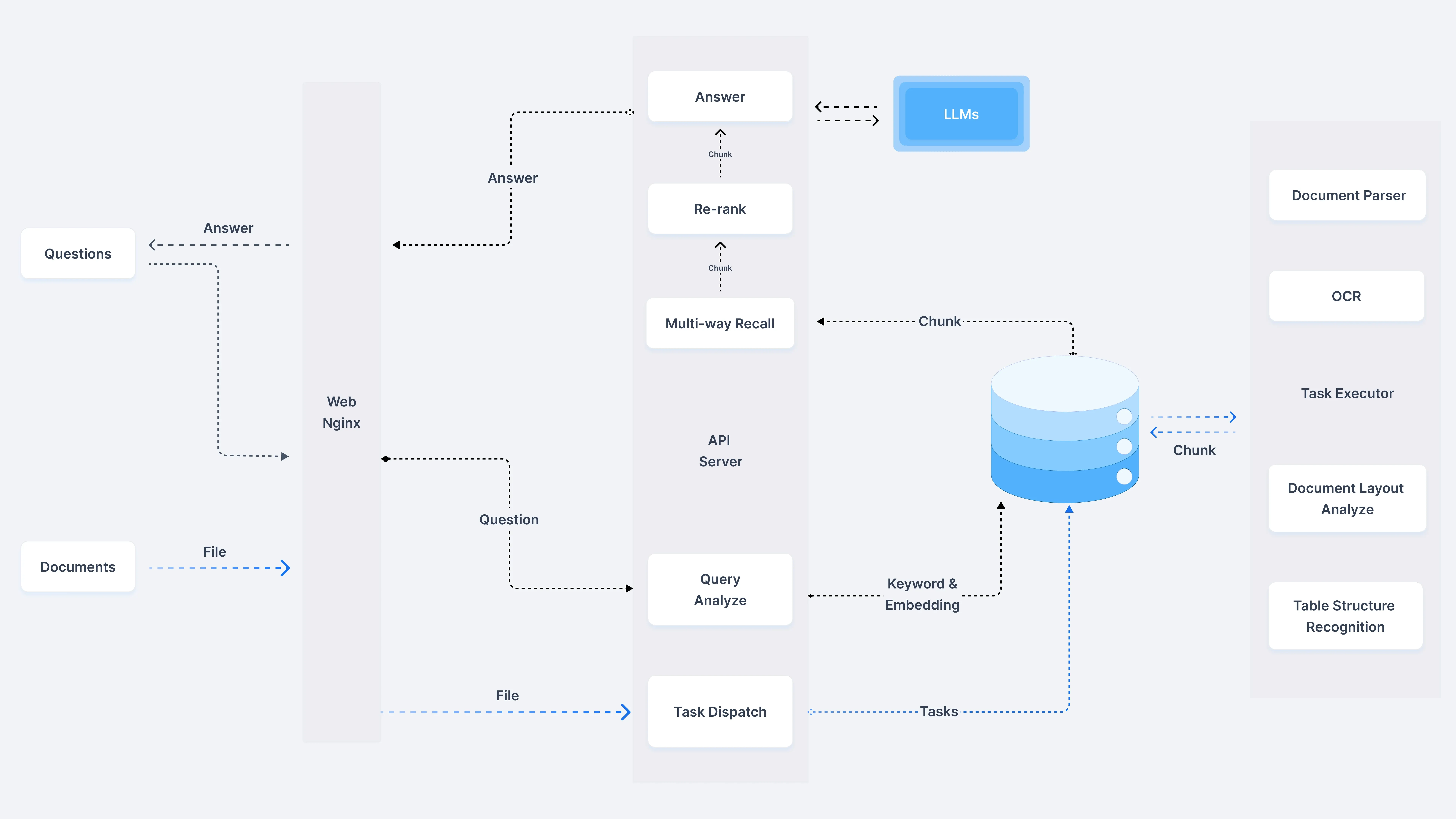
RAGFlow is a RAG engine open-sourced by a Chinese team (InfiniFlow) in April 2024. Its design philosophy is “high-quality input, high-quality output,” therefore RAGFlow provides extensive support for data preprocessing, particularly its core component DeepDoc, which focuses on unstructured data preprocessing.
DeepDoc’s functionalities include:
- OCR Scanning: Uses OCR models to process complex documents.
- Layout Recognition: Uses Yolov8 to identify document layouts such as titles, paragraphs, tables, images, etc.
- Table Structure Recognition (TSR): Identifies table structures, including rows, columns, headers, cell merging, etc.
- Chunking Methods: Users can choose appropriate chunking strategies based on document types, such as Q&A, resumes, papers, manuals, etc.
- Document Parsing: Supports multiple file formats including Word, PPT, PDF, CSV, etc. RAGFlow can automatically extract key information from unstructured text and process it structurally, for example, parsing resume text into name, contact information, work experience, educational background, etc.
One of RAGFlow’s highlights is its visualization of the text chunking process and support for human intervention. Users can not only view the system’s processing results but also clearly understand how documents are chunked and parsed. This design helps users verify and adjust AI outputs to ensure the accuracy and reliability of final results. Additionally, similar to LlamaIndex, RAGFlow also supports Agentic RAG (enhancing system capabilities by introducing AI agents into the RAG process, see What is Agentic RAG for detailed introduction).
This project uses the Apache License 2.0, which is a relatively permissive open source license suitable for commercial use. Although RAGFlow supports multiple data sources, it still has some limitations when processing special format texts in specific industries. It’s recommended that enterprises consider purchasing more professional document intelligence commercial services (which will be discussed in detail in subsequent articles) to enhance the user experience.
5. quivr (Personal Use)
Quivr helps you build a second brain by leveraging the power of Generative AI to become your personal assistant!
Quivr is a knowledge management platform designed to help individuals and enterprises build a “second brain.” For personal users, it provides a RAG-powered personal knowledge base, while for enterprises, it offers a comprehensive knowledge management solution. The platform integrates internal knowledge into a unified knowledge base, allowing teams to access and utilize knowledge efficiently rather than merely searching for information.
Quivr emphasizes leveraging collective wisdom and expertise within a company to continuously update and improve internal knowledge bases, fostering cross-department collaboration. Additionally, it supports integration with multiple applications and data sources, spanning cloud and local storage, chat logs, and more. Through an intuitive interface, users can organize and share critical information, create document collections, and ensure consistency across team communications.
Features:
- Universal Data Acceptance: Supports almost any type of data, including text, images, and code snippets.
- Speed and Efficiency: Designed for fast and efficient data access.
- Security: Allows users to retain control over their data, ensuring privacy and security.
- File Compatibility: Supports diverse file formats, including Markdown, PDF, PPT, Excel, Word, audio, and video.
If you’re looking for a high-completion and mature RAG-powered personal knowledge management product, Quivr is an excellent choice.
6. khoj (Personal Use)
Your AI Second Brain: Ask anything, understand documents, create new content.
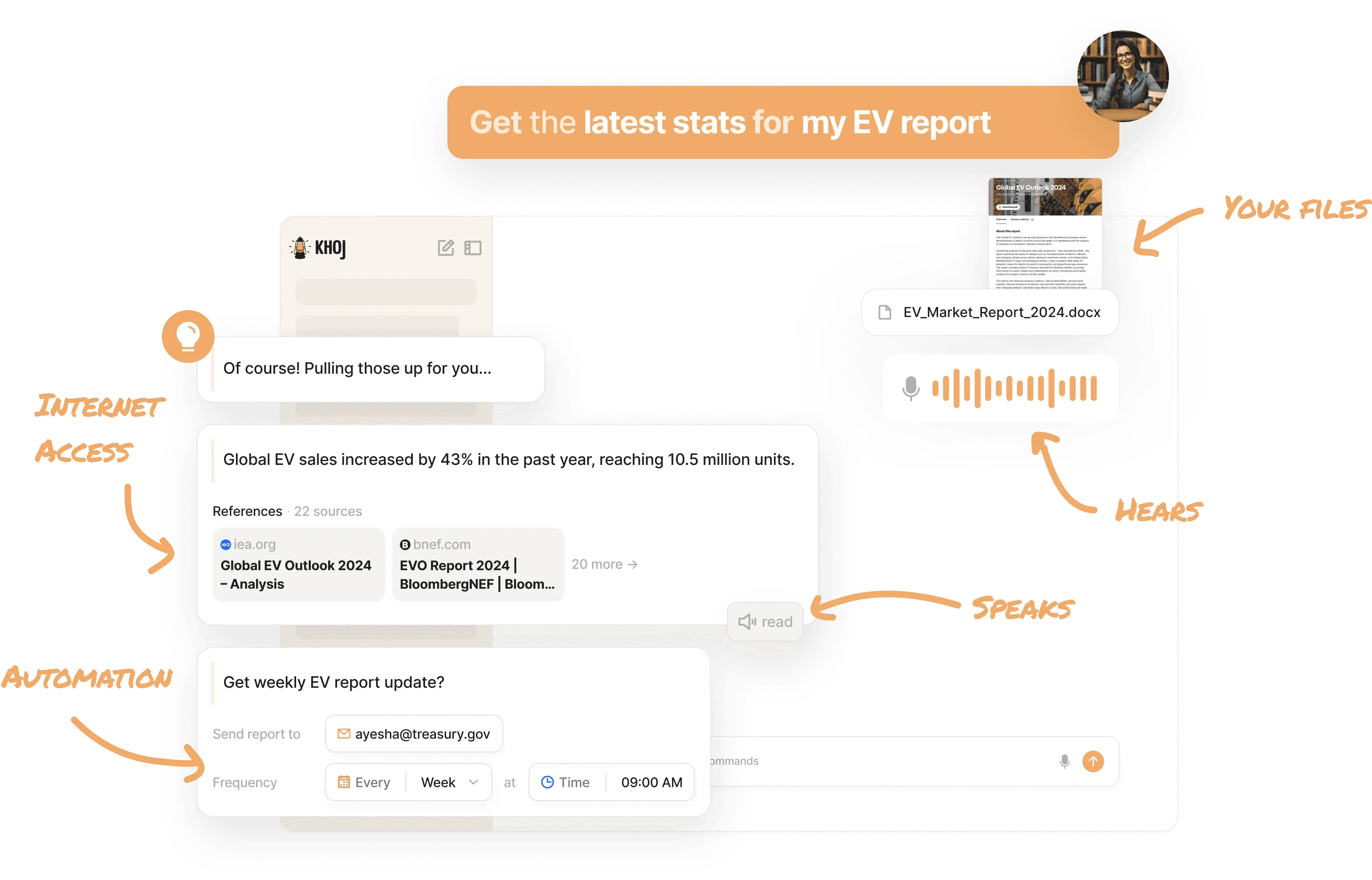
Khoj aims to be a powerful tool for creating a “second brain.” It combines the functionality of Quivr with additional research tools to inspire creativity and generate new content. This makes it particularly well-suited for users with frequent output needs. Khoj AI offers a multimodal AI assistant capable of answering complex questions across documents and the internet, visualizing concepts, and enabling voice interactions. It integrates seamlessly with tools like Obsidian and Emacs, ensuring it fits into users’ daily workflows. My personalized setup allows access via WeChat and supports custom agents to perform specific tasks periodically. Compared to Quivr, Khoj AI aligns better with my knowledge management needs.
7. mem0 (Personalized Memory)
The Memory Layer For Your AI Agents

Mem0 abstracts the retrieval and data storage process further than traditional RAG implementations. It supports multiple data storage methods, including vector, key-value, and graph databases, providing AI agents with a robust memory layer. This ensures the most relevant information is always accessible. Unlike typical RAG implementations based on static document retrieval, Mem0 incorporates context over time by prioritizing the most recent and relevant information. It also enables multi-session context continuity and dynamic data updates.
Features:
- Multi-Level Memory: Supports user-level, session-level, and agent-level memory storage.
- Adaptive Personalization: Continuously optimizes based on user interactions, providing precise personalization.
- Developer-Friendly API: Simple and easy to integrate.
- Intelligent Data Management: Manages stored data based on recency, relevance, and importance.
- Entity Relationship Processing: Understands and links entities across interactions for deeper context comprehension.
- Dynamic Update Mechanism: Adjusts stored information in real-time, ensuring the use of the most up-to-date data.
While Mem0 is highly abstract, it lacks customizable memory management rules. However, the roadmap includes plans to introduce such features. The core idea revolves around time-weighted summarization of interactions to ensure critical information is retained within a model’s context window. Despite challenges in efficiently summarizing historical interactions and relying on large language models for summarization, Mem0 offers excellent foundational capabilities for developing personalized assistants like virtual companions or medical assistants.
8. Perplexica (AI Search)
Perplexica is an AI-powered search engine, serving as an open-source alternative to Perplexity AI.
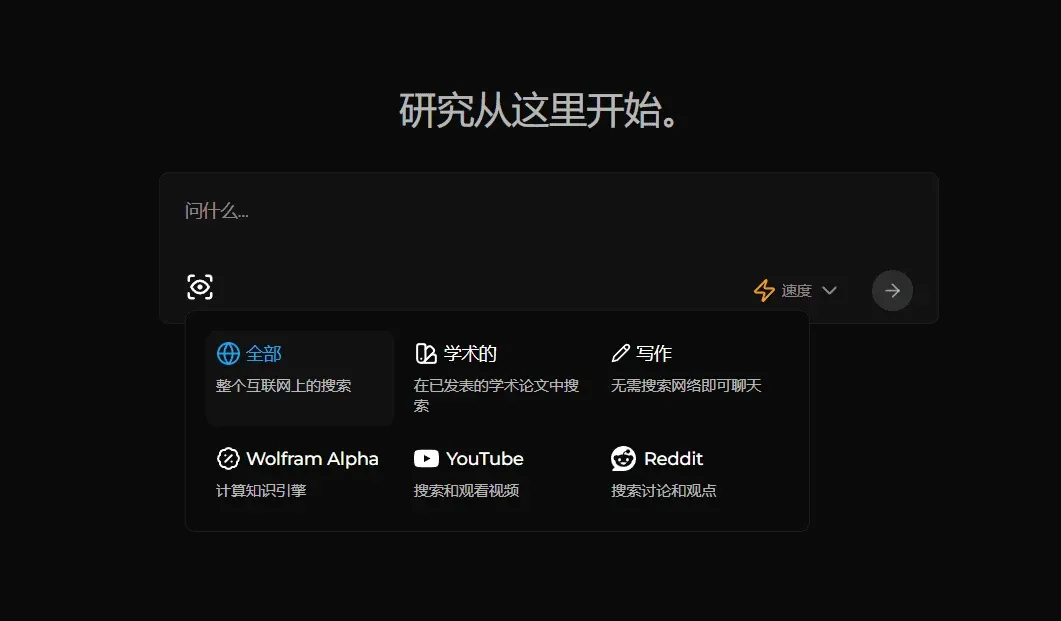
Perplexica is an AI-driven search engine leveraging SearxNG (a free, privacy-focused metasearch engine aggregating results from over 70 services). It integrates local large language models, such as Llama3 and Mixtral, and offers two primary modes of operation: Copilot mode, which enhances relevance through diverse query generation, and standard mode for direct query handling. Perplexica also includes six specialized search modes: general search, writing assistant, academic search, YouTube search, Wolfram Alpha search, and Reddit search.
Among the many open-source AI search engine projects, Perplexica stands out for its maturity, active maintenance, and high code quality, making it an ideal choice for further development. Developers interested in AI search engine technologies may also explore alternatives like morphic, Lepton Search, and llm-answer-engine.
Conclusion
This article serves as a summary and cannot cover every detail. Reply with “RAG” for more extended reading materials, including reviews, open-source tools, application references, enterprise-level practices, research papers, and strategies for building RAG systems. If you found this article helpful, don’t forget to follow, share, and like it!