This is the second article focusing on intelligent document processing (especially PDF and image parsing). Whether in the data collection phase for model pre-training or in the knowledge base construction phase for RAG, a large amount of high-quality data often appears in the form of PDFs or scanned images. Due to the diverse layouts, inconsistent formats, and varying scan quality of these files, utilizing this data is extremely challenging. The main difficulties lie in: first, effectively extracting content and layout information (such as body text, headings, captions, images, tables, formulas, etc.); and second, processing the relationships between layout elements. Given the huge demand in this field, there are both open-source frameworks and commercial solutions, ranging from traditional OCR recognition to new multimodal large models, and even combinations of the two. This article will inventory them, explain their functions, compare their advantages and disadvantages, and recommend application scenarios.
Document intelligence has always been an important topic of academic research and a pain point for industrial needs. It involves the understanding, classification, extraction, and summarization of text and layout information from web pages, digital documents, and scanned documents. The diversity of document layouts and formats, low-quality scanned images, and the complexity of template structures pose many challenges to document intelligence. Automatic, accurate, and fast information processing is crucial for improving productivity. Since the explosion of large model technology, structured analysis and content extraction from documents and images have become key factors for enterprises implementing LLMs. In the financial sector, document intelligence can be used for financial report analysis and intelligent decision support; in the medical field, it can digitize medical records, improve diagnostic accuracy, and propose potential treatment plans by analyzing the correlation between medical literature and medical records; in the financial field, it can automate the information extraction of invoices and purchase orders, greatly reducing the time cost of manual processing. For a detailed history of the evolution of document intelligence, you can read this review from Microsoft Research Asia: “Document Intelligence: Datasets, Models, and Applications”.
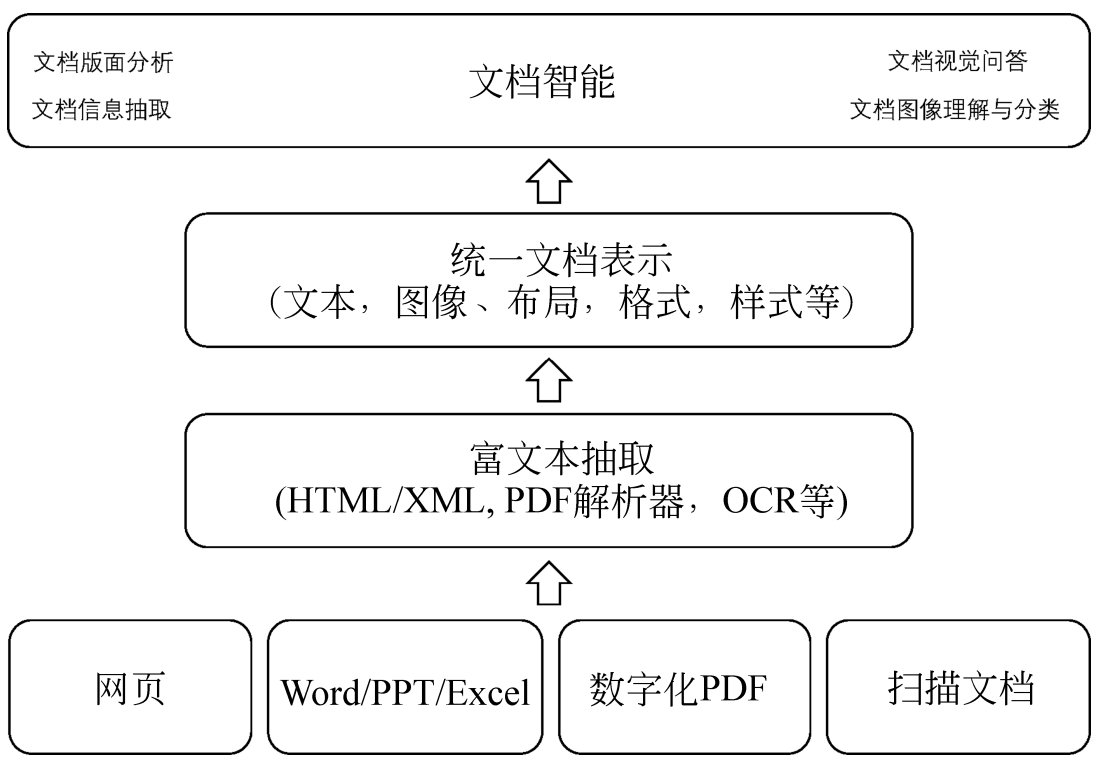
Typical Workflow
Whether it is the intelligent document recognition and processing services provided by vendors, or the extraction of PDF content and recognition of image scans that we encounter daily, the core technology behind them is document intelligence. Here’s a quick overview of the key steps and technologies in the document intelligence processing workflow, to better understand the subsequent comparison analysis of 12 open-source PDF tools and 5 intelligent document processing services. These solutions can be roughly divided into two categories: one is the more mature and widely applicable conventional workflow solution; and the other is the end-to-end solution based on multimodal models that is still in the exploratory stage with limited application scenarios.
First, let’s look at the conventional processing flow, which usually involves the following steps:
-
Document Preprocessing: Preprocessing measures may include denoising, skew correction, binarization, and contrast enhancement. This step is to improve the quality of (image) documents to ensure the accuracy of subsequent analysis and recognition.
-
Physical Layout Analysis: Use regression-based single-stage detection models (such as Faster R-CNN, YOLO, etc.) to detect physical layout elements in the document (such as columns, sections, etc.). By analyzing features such as blank areas, boundaries, and text density in the image, identify different regions such as headings, paragraphs, pictures, and tables.
-
Text Region Analysis: Further analyze the detected text regions, identify words, lines, and paragraphs. This may involve sub-tasks such as text line extraction and character segmentation.

-
Content Recognition: Apply technologies such as OCR and table parsing to extract content such as tables, formulas, and text.
-
Logical Layout: Understand the structure and hierarchical relationships of the document through semantic analysis, and organize text blocks into semantic units such as paragraphs and lists.
-
Data Output: Output the analysis results in formats such as HTML and JSON for subsequent processing and application.
Content Recognition
Open Content Recognition
Content recognition is a follow-up step to the layout analysis process. Layout analysis focuses on the overall layout and structure of the document, while content recognition focuses on the identification of specific content in the document. It mainly includes three scenarios: table parsing, formula recognition, and text extraction.
Table Parsing
Table structure recognition is a task performed after completing table region detection, aiming to parse the layout and hierarchical structure of tables and transform visual information into a structural description that can be used to reconstruct the table. These descriptions cover the exact positions of cells, the relationships between cells, and the row and column positioning of cells. Currently, table structure information is mainly described in two ways: 1) a list of cells (including the position, row list information, and content of each cell); 2) HTML or LaTeX code (in addition to the position of the cell, sometimes including the content). In practical applications, table types are diverse, with varying structures. According to the position of the table header, tables can be roughly divided into four categories:
- Vertical Tables: The first row is the header, and the remaining rows are vertically arranged data, which is the most basic form of a table.
- Horizontal Tables: The first column is the row header, and the remaining columns are horizontally arranged data, which is common in character information records in Wikipedia.
- Hierarchical Tables: The headers have a hierarchical structure, and the tables contain merged cells, which are common in statistical reports and academic papers. Such tables may have hierarchical structures for both row and column headers.
- Complex Tables: The headers are not limited to the left or top of the table but can appear at any position, or even mixed with regular data, such as the forms commonly found in professional equipment manuals, government registration forms, and company job applications.

Formula Recognition
Formula recognition is used to convert mathematical formulas in images into formats such as LaTeX and MathML, ensuring that they are displayed and edited correctly in the document. However, the recognition of handwritten mathematical formulas still faces challenges in scenarios such as automatic grading, digital library construction, and office automation. This is mainly because these formulas have complex two-dimensional structures, diverse writing styles, and ambiguities in handwritten symbols. Specifically, the difficulty of recognizing handwritten mathematical formulas is reflected in the following aspects:
- Complex two-dimensional structures, such as fractions, subscripts and superscripts, and square roots;
- Diverse writing styles, where different people may have variations in writing the same symbol;
- Ambiguities of handwritten symbols, where some symbols can be easily confused when handwritten.
Text Extraction
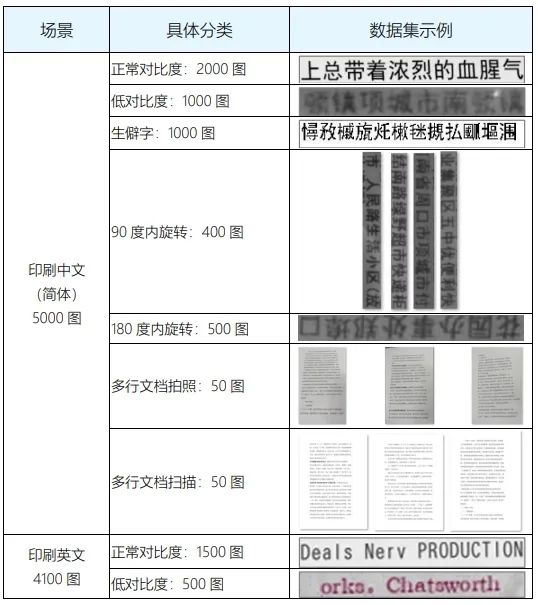
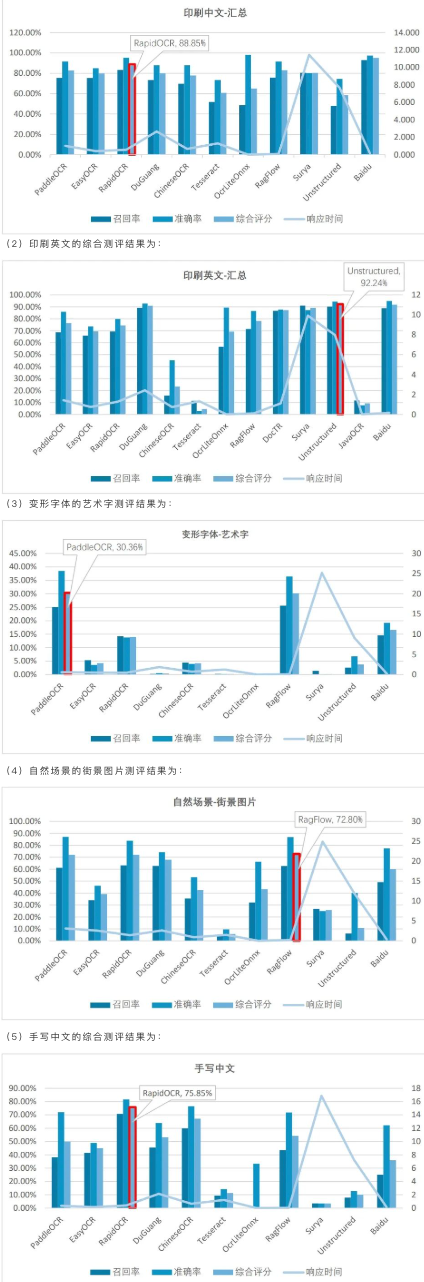
Here, it is important to focus on OCR recognition. OCR (Optical Character Recognition) is used to recognize text content in images and convert it into an editable text format. Text recognition is one of the core application scenarios of OCR technology. The Guangzhou Institute of Software Application Technology has released a performance evaluation report on 12 open-source OCR tools (including PaddleOCR, RapidOCR, 读光 (DuGuang), ChineseOCR, EasyOCR, Tesseract, OcrLiteOnnx, Surya, docTR, JavaOCR and the document analysis components RagFlow and Unstructured). The evaluation covers five key scenarios: printed Chinese, printed English, handwritten Chinese, complex natural scenes, and deformed fonts. The datasets used in this evaluation (see the figure below) are convincing in terms of quantity and diversity, and the timeframe is recent (June 2024), which makes it highly valuable for reference. You can obtain the complete evaluation report by replying “文档解析” in the background of the WeChat public account “莫尔索随笔”, which will be helpful for your technology selection and for designing a test dataset that suits your scenario.

End-to-End Multimodal Models
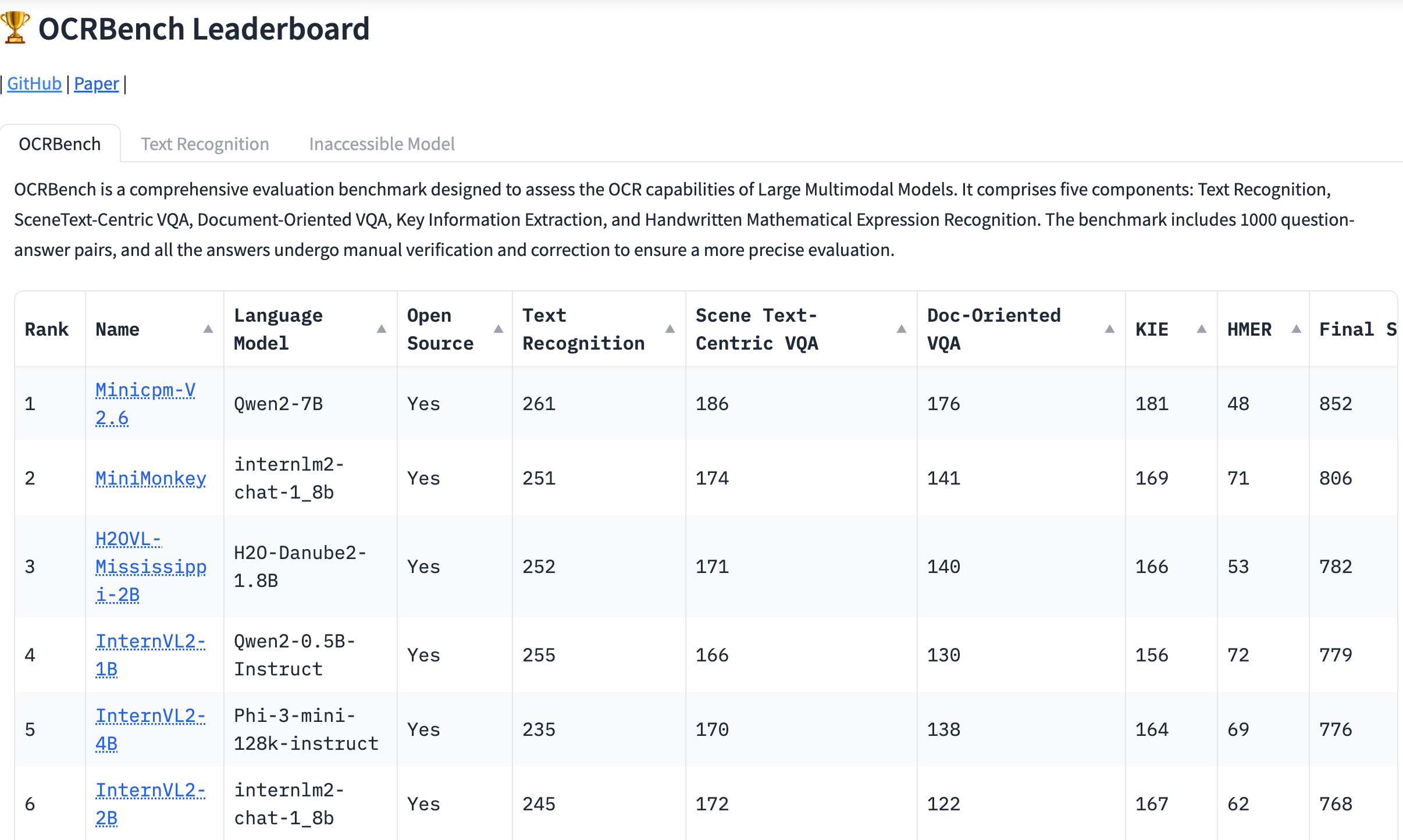
End-to-end solutions based on multimodal large models (such as MiniCPM-V 2.6 from the Wall Lab) are more direct. By designing specific prompts, they can directly extract and analyze information from image documents and output structured data. Although there are many related projects in the open-source community, they are far from mature, which I will discuss in detail later. For multimodal models, there is an evaluation tool called OCR Task Benchmark (OCRBench), which covers test dimensions such as text recognition, scene text-centric Visual Question Answering (VQA), document-oriented VQA, Key Information Extraction (KIE), and Handwritten Mathematical Expression Recognition (HMER). Multimodal models perform well on traditional text tasks, but they have limitations in processing text lacking semantic context, handwritten text, multilingual text, and high-resolution input images.
Open-Source Frameworks
After understanding the core capabilities, we can now compare the 12 open-source document parsing frameworks. First, I will quickly introduce each tool, and finally, I will use a table to visually show the capabilities of each framework. If you don’t want to read the introductions, you can skip directly to the summary section.
Conventional Workflow
1. MinerU
MinerU is placed first because this project has a particularly high degree of completion. As an open-source data extraction tool developed by the Large Model Data Base Team (OpenDataLab) of the Shanghai Artificial Intelligence Laboratory, MinerU specializes in efficiently extracting content from complex PDF documents, web pages, and e-books. It can remove non-text elements such as headers, footers, footnotes, and page numbers from documents, ensuring the semantic coherence of the extracted content. This tool supports single-column, multi-column, and complex layout text extraction, and can retain the structure of the original document, such as headings, paragraphs, and lists. In addition, MinerU can also extract images, image descriptions, tables, table titles, and footnotes. For mathematical formulas in documents, MinerU can automatically recognize and convert them to LaTeX format, while converting tables to HTML format. For scanned PDFs and garbled PDFs, MinerU is equipped with OCR capabilities, supporting detection and recognition of 84 languages, and outputs in various formats, including Markdown and JSON.
However, MinerU does not support the processing of vertical text. Tables of contents and lists rely on rule-based recognition, and a few uncommon list types may not be correctly recognized. It only supports first-level headings and does not support multi-level headings. Comic books, art albums, elementary school textbooks, and exercise books cannot be accurately parsed currently. Row and column errors may occur when processing complex tables. OCR recognition of small-language PDFs may not accurately recognize special characters, such as Latin accent marks or confusing characters in Arabic. Some mathematical formulas may not be displayed correctly in Markdown.
Despite the above limitations, I still highly recommend this project. Its PDF parsing function has been split into an independent project PDF-Extract-Kit, through which you can gain a deeper understanding of the specific implementation of the document processing flow, including table parsing methods and the design of layout analysis models. In addition, the OpenDataLab team has also shared a PPT about MinerU, linked here, which contains many valuable insights, especially about systematic thinking in web content collection and PDF parsing.
2. PaddleOCR
PaddleOCR is placed second, its ecosystem is prosperous, its influence is huge, and there are many extended projects. The topic of OCR basically cannot avoid it. The PDF-Extract-Kit mentioned above uses it. PaddleOCR is an open-source multilingual OCR toolkit developed based on the PaddlePaddle deep learning framework. It provides developers with rich and practical OCR solutions to help train higher-quality models and apply them to practical scenarios. PaddleOCR provides a series of functional models, covering intelligent analysis of text images, general OCR, layout analysis, table recognition, and seal text recognition. In addition, it also supports the following advanced functions:
- Document Scene Information Extraction (PP-ChatOCRv3-doc): used to extract key information from documents.
- High-Precision Layout Region Detection Model (based on RT-DETR): suitable for applications that require high-precision detection.
- High-Efficiency Layout Region Detection Model (based on PicoDet): suitable for scenarios with high processing speed requirements.
- High-Precision Table Structure Recognition Model SLANet_Plus: can accurately recognize the structure of tables.
- Text Image Correction Model UVDoc: used to correct distorted text images.
- Formula Recognition Model LatexOCR: can recognize and convert mathematical formulas.
- Document Image Orientation Classification Model (based on PP-LCNet): used to determine the orientation of document images.
3. Marker
Marker is used to quickly and accurately convert PDF files into Markdown, JSON, and HTML formats. It also has a corresponding commercial service Datalab, which includes the following features:
- Page Layout Detection: Use the Surya model to detect page layouts and determine the reading order of the text.
- Content Cleaning and Formatting: Use heuristics, texify, and tabled models to clean and format text, ensuring the clear structure of elements such as tables and code blocks.
- Text Extraction: In addition to using conventional PDF parsing methods, OCR technology (such as heuristics and the Surya model) is also used to recognize text in images.
- Formula Image Processing: Extract images from PDFs and convert formulas into LaTeX format.
The core of Marker is the open-source Surya, which is a document OCR toolkit that supports more than 90 languages, providing text detection, layout analysis, reading order, and table recognition, among other functions. The details of its capabilities are described in detail in the previous open-source OCR tool evaluation report, which you can read on your own.
4. Unstructured
Unstructured is an open-source library and API suite designed to build custom data preprocessing pipelines. It is mainly used for data extraction, transformation, and loading (ETL) processes in machine learning tasks. It supports multiple document formats such as PDF and images, helping developers extract structured information from unstructured data for use in annotation, training, or production environments for machine learning models. The founder of this project has built an enterprise-level data preprocessing tool on this basis, providing commercial services, and has raised $25 million in funding.
Multimodal Models
5. gptpdf
The idea is good. This is the first project I’ve seen that uses a multimodal model to process PDFs. Although it is no longer maintained, I still include it here. It has a few hundred lines of code and uses GPT-4o to parse PDF files. First, it uses the PyMuPDF library to analyze the PDF file, identify and mark all non-text areas, such as charts and pictures. Then, it uses GPT-4o to process these marked non-text areas, providing the model with appropriate prompts to guide it in converting the content of these areas into Markdown format.
DEFAULT_PROMPT = """Using markdown syntax, convert the text identified in the image into markdown format for output. You must do:
1. Output in the same language as the identified image, for example, if an English field is identified, the output must be in English.
2. Do not explain or output irrelevant text, output directly the content of the image. For example, strictly prohibit outputting examples like "The following is the markdown text I generated based on the image content:" Instead, output markdown directly.
3. The content should not be enclosed in `markdown`, use $$ $$ for paragraph formulas, use $ $ for inline formulas, ignore long straight lines, and ignore page numbers.
Again, do not explain and output irrelevant text, output directly the content of the image.
"""
DEFAULT_RECT_PROMPT = """In the image, some areas are marked with red boxes and names (%s).
If the area is a table or picture, insert it into the output content in the form of ![](), otherwise output the text content directly.
"""
DEFAULT_ROLE_PROMPT = """You are a PDF document parser, use markdown and latex syntax to output the content of the image.
"""6. Zerox
Zerox first converts formats such as PDF and Docx into a series of images. This step uses tools such as graphicsmagick and ghostscript to process PDF files. For the Docx format, it uses tools like libreoffice to convert it to PDF first and then performs image conversion. The converted images are passed to the multimodal model, and the following steps are consistent with the idea of gptpdf. The Markdown text returned by the model for each page is aggregated to form a complete Markdown document. By the way, the founder of the project has also launched the OmniAI product based on this, which is used to convert various types of documents into structured data and has raised $3.2 million in funding.
Combined Solutions
7. Chunkr
Chunkr can convert files in formats such as PDF, PPT, Docx, and Excel into structured data. It performs document layout analysis by using 11 semantic labels (combined with multimodal models), supports OCR technology to extract text content, and can generate structured output containing border information in formats such as HTML and Markdown. The company that open-sourced this project is called Lumina, which also makes an AI search engine and has received YC investment.
8. pdf-extract-api
pdf-extract-api is used to convert images and PDF documents into Markdown or JSON formats. It supports multiple OCR strategies, including surya, llama_vision (multimodal model), and tesseract. In addition, it also integrates LLMs (such as LLama 3.1) to improve the quality of OCR text.
9. Sparrow
The Sparrow project is used to efficiently extract and process data from various documents and images, including unstructured data sources such as tables, bank statements, invoices, and receipts. It has a modular architecture, including multiple components. Among them, Sparrow Parse supports data extraction using multimodal models, and Sparrow OCR uses OCR technology for character recognition. Sparrow is only good at handling common formalized documents.
Other
The title mentions 12 open-source projects, so why are only 9 listed? Don’t worry, the remaining 3 were already covered in the first article of this series, an introduction to RAG frameworks, as well as RAGFlow’s open-source DeepDoc and Quivr’s open-source MegaParse. These components not only provide document parsing functions, but also handle the content chunking step, which are indispensable parts of building an efficient RAG framework, and will not be discussed further here.
Summary
Here comes the important part!
| Function | MinerU | PaddleOCR | Marker | Unstructured | gptpdf | Zerox | Chunkr | pdf-extract-api | Sparrow | LlamaParse | DeepDoc | MegaParse |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PDF and Image Parsing | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Parsing of Other Formats (PPT, Excel, DOCX, etc.) | ✓ | - | - | ✓ | - | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ |
| Layout Analysis | ✓ | ✓ | ✓ | - | ✓ | - | ✓ | - | - | ✓ | ✓ | - |
| Text Recognition | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Image Recognition | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Simple (Vertical/Horizontal/Hierarchical) Tables | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Complex Tables | - | - | - | - | - | - | - | - | - | - | - | - |
| Formula Recognition | - | - | - | - | - | - | - | - | - | - | - | - |
| HTML Output | ✓ | - | ✓ | ✓ | - | - | ✓ | - | - | - | ✓ | - |
| Markdown Output | ✓ | ✓ | ✓ | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | - | ✓ |
| JSON Output | ✓ | - | ✓ | ✓ | - | - | ✓ | ✓ | - | ✓ | ✓ | - |
PDF, DOCX, Excel, and PPT all have corresponding parsers, with PDF parsing being the most complex and therefore often used as a benchmark for evaluating document parsing capabilities. Although there are many excellent open-source projects, they mostly perform poorly when processing complex tables and formula recognition. For example, when a formula is embedded in a context page, frameworks with layout analysis capabilities often have a large number of recognition errors. In addition, these projects have their own limitations: gptpdf and PaddleOCR lack necessary post-processing steps; Marker supports a limited number of languages, and Figure processing is not perfect; MinerU consumes more computing resources, etc. Most projects support Markdown and HTML conversion formats to facilitate LLM understanding and processing. However, projects that do not support HTML output can be identified as unable to parse relatively complex tables, because standard Markdown syntax is only suitable for simple table structures, while complex tables need to be implemented using HTML tables or other document formats (such as LaTeX, AsciiDoc, ReStructuredText).
File parsing is a continuous optimization process. For files of different formats and complexities, it is necessary to continuously explore and adjust solutions. When dealing with PDF files, digital signatures, scans, photocopies, and complex table parsing are all special cases that require specialized methods. There are still many opportunities in this field. If you are interested in collaboration, please contact me in the background for discussion and consultation.
Intelligent Document Processing Services
Given the poor performance of open-source projects in handling complex tables and formulas, I further tested 5 paid intelligent document processing services and found that their performance is indeed better. It seems that high prices do indeed come with better performance. For example, consider the complex merged cell below. (For more document test data with complex tables and formulas, you can obtain it by replying “文档解析” in the background of the WeChat public account “莫尔索随笔.” This should be helpful for you to choose a vendor and design a test dataset that suits your scenario).
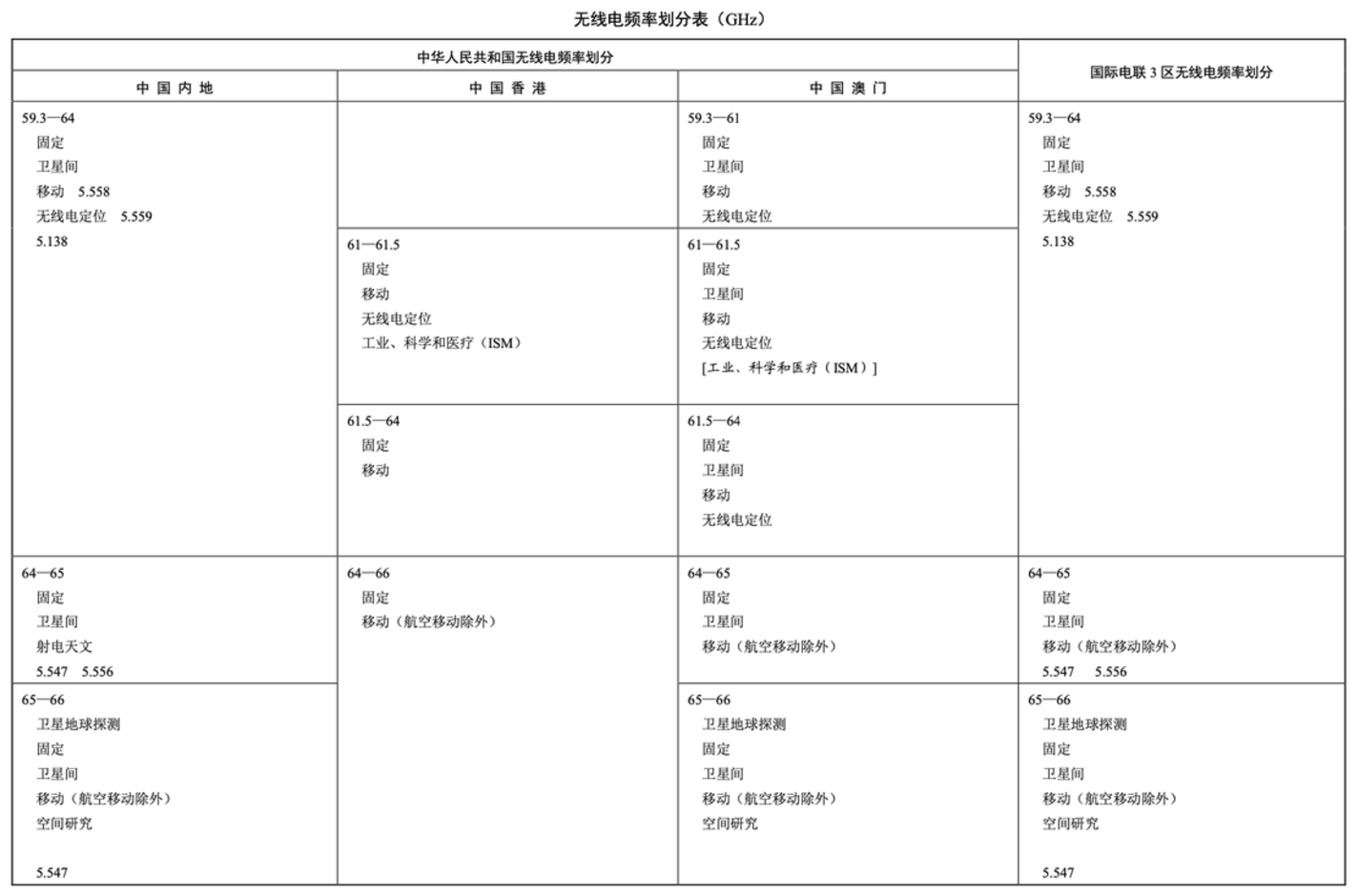
TextIn
TextIn is a general document parsing service launched by Heyge Information. It can recognize text information in documents or images and parse the document content into HTML format while maintaining the common reading order. This service has high accuracy in table recognition and can handle wired tables, wireless tables, dense tables, as well as cell merging and cross-page table merging. The parsing speed is extremely fast, with a 100-page long document only taking 1.5 seconds at its fastest. It also supports online and offline batch processing. TextIn ParseX supports multiple document formats, including PDF, Word, and HTML, and can obtain text, tables, heading levels, formulas, handwritten characters, and image information at once. TextIn’s parsing is correct, but the distinction of the content within the table is not obvious.

PDFlux
PDFlux is a data extraction tool designed specifically for PDF documents, realizing intelligent recognition and extraction of table and text content in PDFs or images. In terms of content recognition, PDFlux can intelligently recognize table and text content in PDFs or images, support wireless table recognition, precise extraction of complex layouts, automatic straightening of skewed tables, removal of seal interference, intelligent merging of cross-page tables, and one-click removal of spaces and line breaks. In terms of format conversion, PDFlux supports converting PDFs to various formats such as Word, Excel, and HTML, which is convenient for users to edit and read on mobile devices, while retaining the chapter and directory structure of the document. The recognition result of PDFlux lost the table title.
Mathpix
Through OCR technology, it can recognize formulas and quickly and accurately convert mathematical formula screenshots and handwritten formulas into LaTeX format. Whether it is interline or inline formulas, they can be accurately recognized, supporting multiple languages. It can recognize tables in images or PDF files and output TSV (tab-separated value) format, and can directly convert PDFs to LaTeX, Word, and HTML formats. Immersive translation, Anthropic, Google Bard, etc., all use its services. Mathpix recognition is correct, but there are no merged cells.

Doc2x
Upload PDFs or images, accurately recognize formulas and tables, and efficiently convert them to various formats such as Word, LaTeX, HTML, and Markdown with one click. Doc2x’s recognition is correct, and the content is separated by spaces.
Baidu Intelligent Cloud Office Document Recognition Service
As a large company’s product, I first tried Baidu’s. The content was correct, but the table structure was lost. I directly gave up on it, and I didn’t continue to try other companies’ products.

Concluding Remarks
In the future, when you see new open-source projects related to document parsing, you can quickly determine whether they have substantial innovation by using the following techniques: first, check whether the project follows the traditional OCR process; second, observe whether the table recognition and layout analysis models are self-developed or based on open-source tools such as PaddleOCR. If there is innovation in these aspects, then the project is worth further research. If you plan to apply relevant technologies in actual products, in the spirit of responsibility to users, prioritize commercial intelligent document processing services (commercial intelligent document processing services mainly focus on three dimensions: fast, accurate, and stable: accurate recognition of (tables and formulas), fast parsing speed, and good stability). For documents containing a large number of tables and formulas, I recommend the following choices: for formula recognition in English context, Mathpix is preferred; for formula recognition in Chinese context, Doc2X should be selected; and for complex tables, PDFlux or TextIn are more reliable. If you want to build your own document parsing solution, use MinerU as a base, and use the PaddleOCR toolkit to train the corresponding models for specific scenarios that cannot be handled. If you find the content helpful, please follow, share and give a thumbs up!