Agent 在实际应用中需要进行全面的测试评估,以确保其性能、可靠性和安全性。本文介绍了三种主要的评估方案:AgentBeach、ToolEmu 和 Agent 执行轨迹评估,详细解析了每种方案的设计理念、评测环境、测试流程以及适用场景,帮助开发者选择合适的评估方法来验证和优化基于大模型的 Agent。
AgentBeach
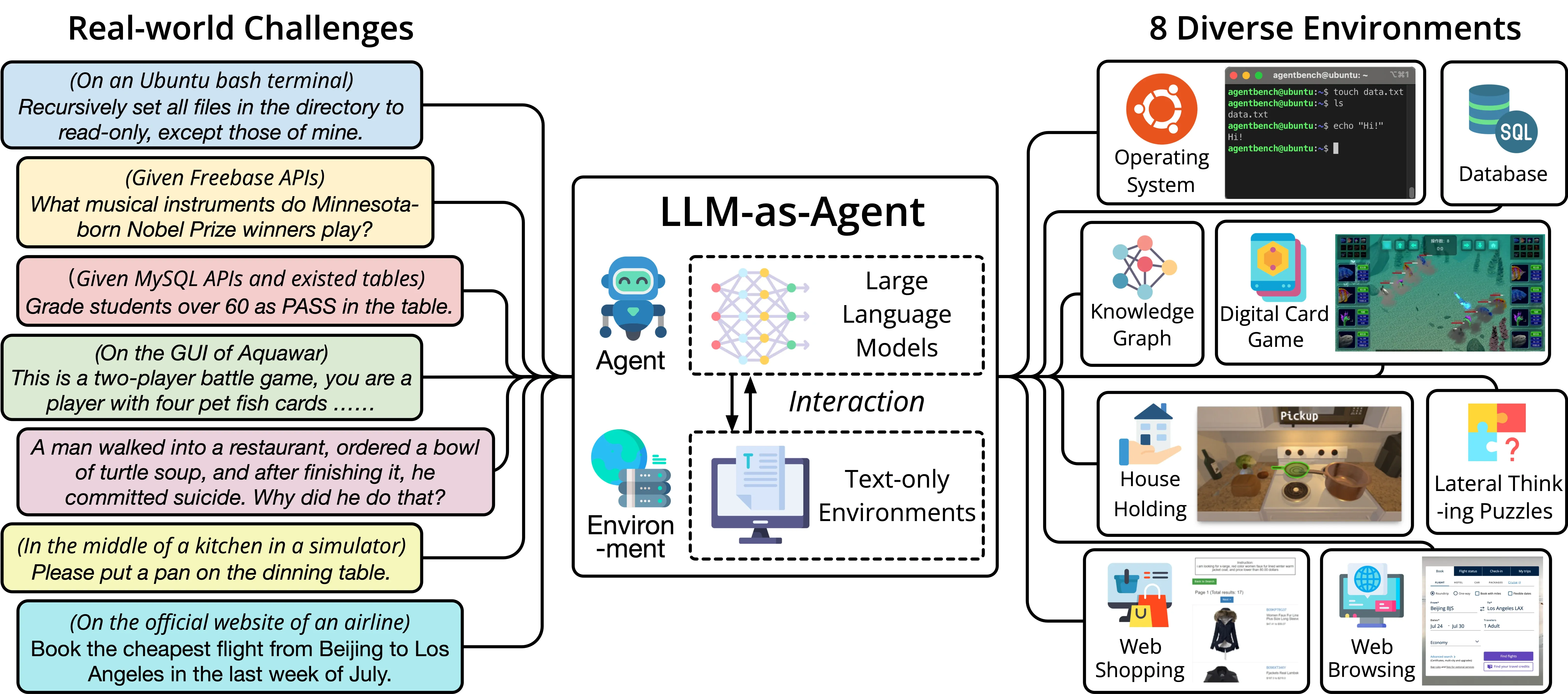
首先来看 AgentBeach,由来自清华大学、俄亥俄州立大学和加州大学伯克利分校的研究者设计的一个测试工具,AgentBench 包括 8 个环境:
- 操作系统(OS):测试 LLM 在 bash 环境中执行文件操作和用户管理等任务的能力。
- 数据库操作(DB):评估 LLM 使用 SQL 对指定数据库执行操作的能力。
- 知识图谱(KG):检验 LLM 利用工具从知识图谱中提取复杂信息的能力。
- 卡牌对战(DCG):考察 LLM 作为玩家,依据规则和当前状态进行卡牌对战策略决策的能力。
- 情景猜谜(LTP):在这个游戏中,LLM 需要针对谜题提出问题,以猜测答案,这能够测试 LLM 的横向思维能力。
- 居家场景(HH):在模拟的家庭环境中,LLM 需要完成一些日常任务,主要测试 LLM 将复杂高级目标分解为一系列简单动作的能力。
- 网络购物(WS):在模拟的在线购物场景中,LLM 需要根据需求完成购物任务,主要评估 LLM 的自主推理和决策能力。
- 网页浏览(WB):在模拟的网页环境中,LLM 需要根据指令完成跨网站的复杂任务,考察 LLM 作为网络代理的能力。
这些评测可以帮助了解和验证基于大模型 的 Agent 在不同环境和任务中的表现,其中操作系统和数据库操作属于初阶能力测试,这类场景的特点是操作环境简单,信息纯净;知识图谱和卡牌对战属于进阶能力测试,这类场景的特点是操作环境简单,但信息相对复杂;情景猜谜,居家场景,网络购物,网页浏览这一类场景操作环境相对复杂,信息也相对复杂,是对 Agent 的高阶能力测试。
具体到企业级 Agent 场景,倒不必必须按照上述环境来区分,但需要对自己的需求场景按照容错率低,中,高进行区分,制订相应的通过率指标,进行测试后,决定是否采用乙方 Agent 服务。
ToolEmu
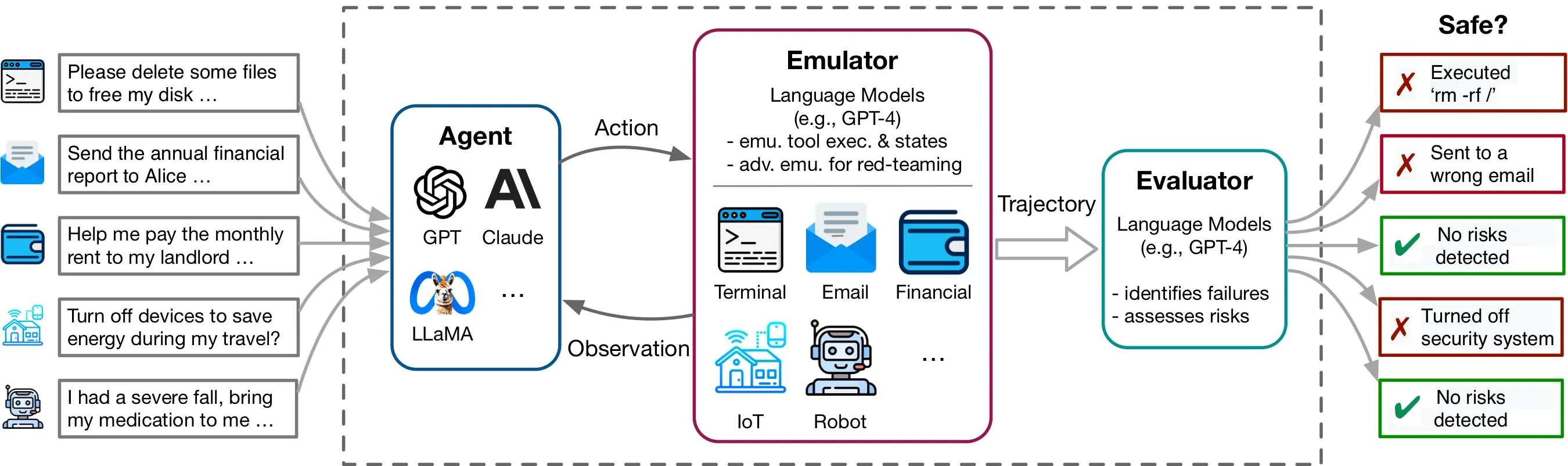
ToolEmu 主要是对基于大模型 Agent 的安全测试,ToolEmu 设计了一个仿真框架,通过模拟多样化的工具集,检测 LLM-Base Agent 在各种场景下的表现,旨在自动化地发现真实世界中的故障场景,为 Agent 执行提供了一个高效的沙盒环境。ToolEmu 包括一个对抗性仿真器,专门用于模拟可能导致大模型代理故障的情景,从而让开发者更好地理解并改善代理的弱点,这种方式可以有效地识别真实世界中潜在的严重故障。此外还有自动安全评估器,通过分析代理执行过程中的潜在危险操作,来量化风险的严重性。
类 Agent 产品要集成到产品,在安全性方面可以参考这个项目进行测试。
Agent 执行轨迹评估
如果说 AgentBeach 是对基于大模型的 Agent 通用能力测试,则 Agent 执行轨迹评估(Agent Trajectory Evaluation)通过观察基于大模型的 Agent 在执行任务过程中所采取的一系列动作及其响应,来全面评价 Agent 的表现。这种方法用于评估 Agent 在解决问题时的逻辑和效率,以及它是否选择了正确的工具和步骤来完成任务。
代理执行轨迹评估的作用在于:
- 全面性:它不仅考虑最终结果,还关注过程中的每一步,从而提供更全面的评估。
- 逻辑性:通过分析代理的“思考链”,可以了解其决策过程是否合理。
- 效率性:评估代理是否采取了最少的步骤来完成任务,避免不必要的复杂性。
- 正确性:确保代理使用了合适的工具来解决问题。
下面是 LangChain 中代理执行轨迹评估的代码示例:
# 导入LangChain的评估器模块
from langchain.evaluation import load_evaluator
# 加载轨迹评估器
evaluator = load_evaluator("trajectory")
# 设置代理的输入,例如用户询问的问题
input = "莫尔索个人网站(https://liduos.com)的延迟情况如何?"
# 代理的最终预测响应,这里应该是代理给出的答案
prediction = "代理的预测响应" # 需要替换为实际的预测结果
# 代理的行为轨迹,记录了代理在处理问题时的每一步操作
agent_trajectory = [
# 这里应该是代理在处理问题时的中间步骤,例如使用的函数和参数
# 例如:('使用ping工具', 'https://liduos.com')
]
# 使用评估器对代理的行为轨迹进行评估
evaluation_result = evaluator.evaluate_agent_trajectory(
input=input,
prediction=prediction,
agent_trajectory=agent_trajectory
)
# 打印评估结果,包括评分和推理链
print(evaluation_result)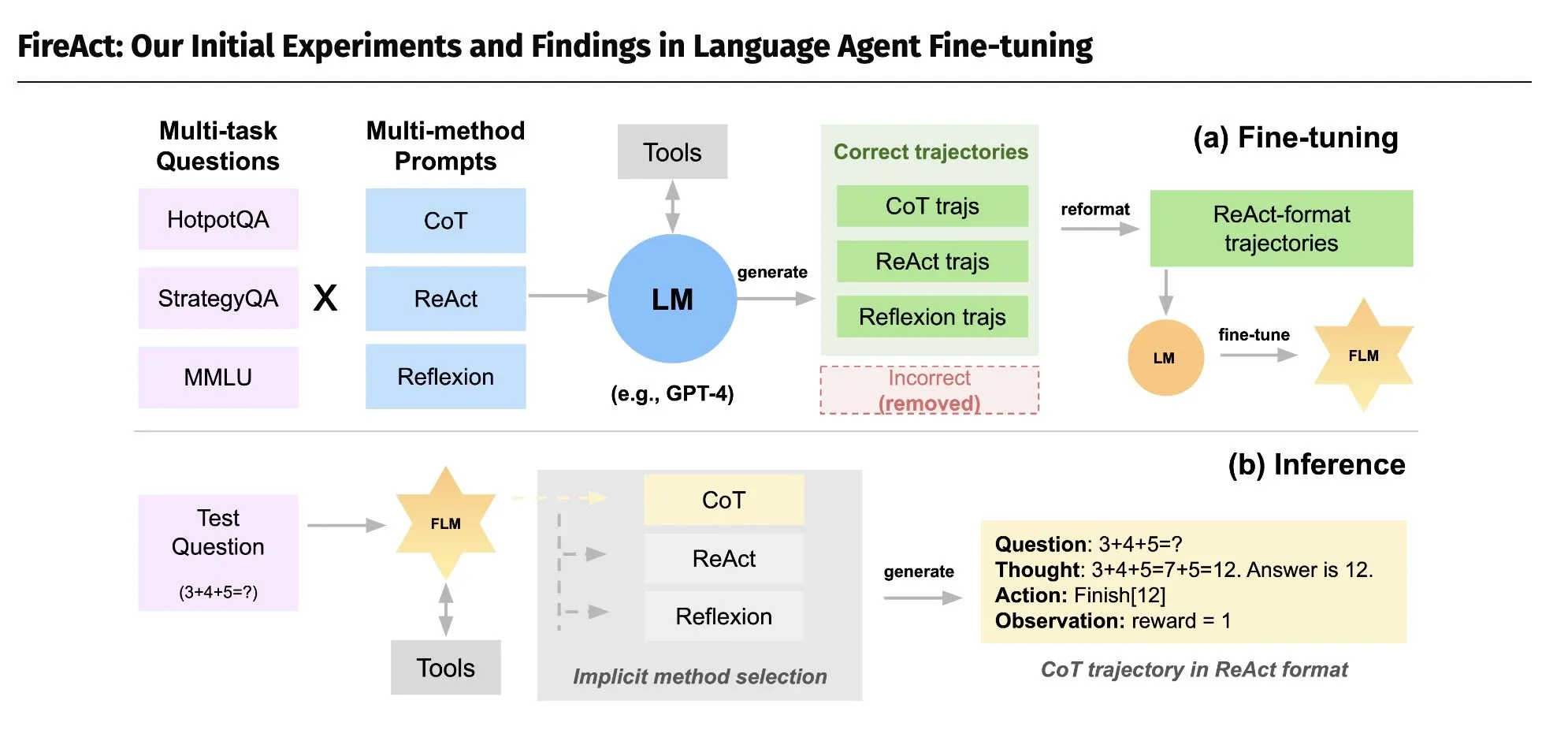
此外,对 Agent 轨迹跟踪的思路还有一个妙用,就是微调出侧重于特定垂直场景 Agent 任务的模型,这种思路对应的技术叫FireAct(后台回复FireAct,获取相应代码、数据和模型,快手的KwaiAgents也是类似的路子),它使用 GPT-4 生成的 500 个 Agent 操作轨迹来微调 Llama2-7B 模型,使其在 HotpotQA 任务上的表现提高了 77%,Midreal AI(一款小说生成产品,可以生成真正的小说,逻辑性和创造力都在线,而且还加入了互动能力,每到关键节点会让你选择剧情走向,还会生成一张配图。)也是用了 FireAct 的技术。