深入理解 MySQL 索引模型,特别是 InnoDB 存储引擎中的 B+ 树、聚簇索引与二级索引。学习索引维护、自增主键及覆盖索引等优化策略,提升数据库查询性能。
索引模型
哈希表
哈希表适合只有等值查询的场景
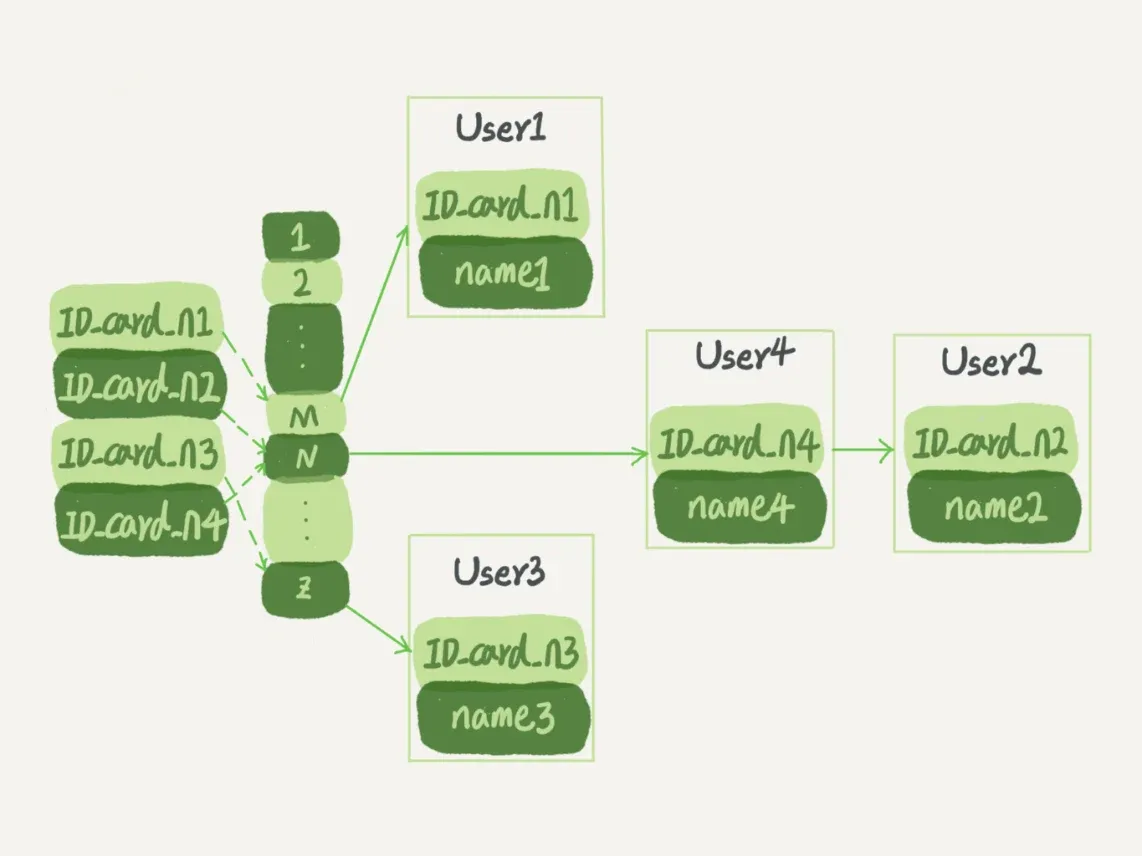
有序数组
有序数组只适用于静态存储引擎(针对不会再修改的数据)
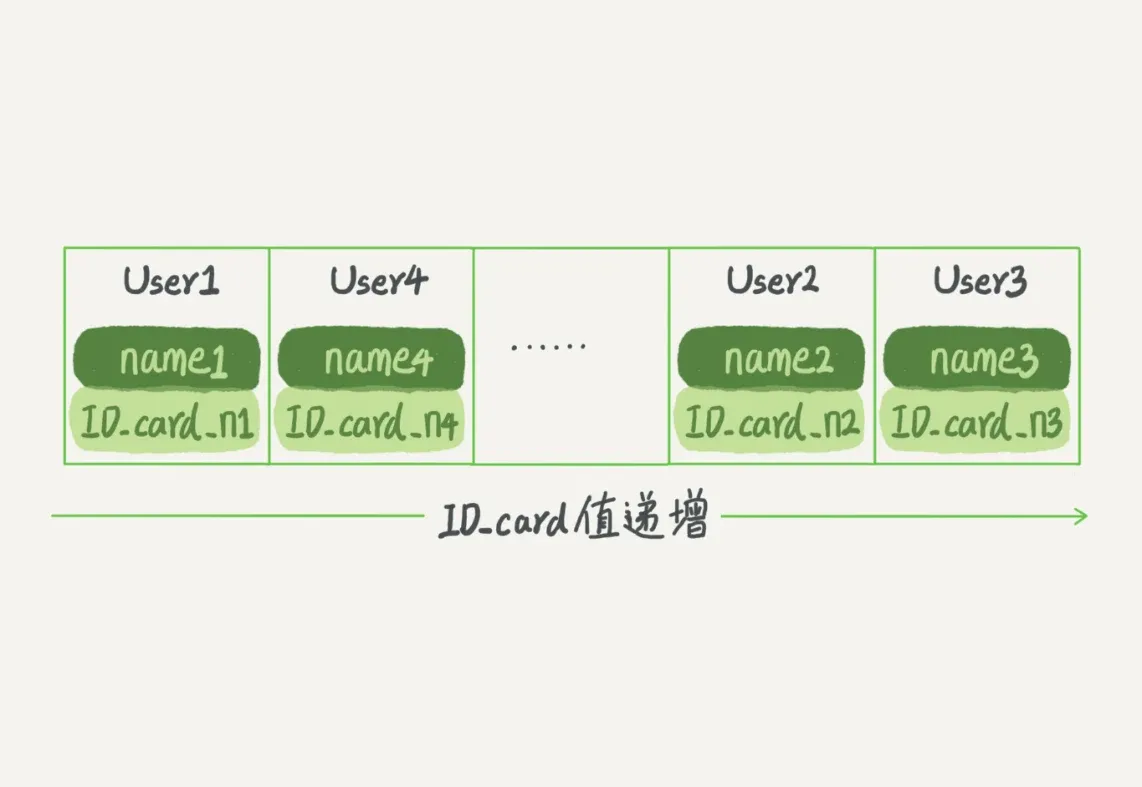
- 等值查询:可以采用二分法,时间复杂度为
O(log(N)) - 范围查询:查找
[ID_card_X,ID_card_Y]- 首先通过二分法找到第一个大于等于
ID_card_X的记录 - 然后向右遍历,直到找到第一个大于
ID_card_Y的记录
- 首先通过二分法找到第一个大于等于
- 更新操作:在中间插入或删除一个记录就得挪动后面的所有记录
搜索树
平衡二叉树
查询的时间复杂度:O(log(N)),更新的时间复杂度:O(log(N))(维持树的平衡)
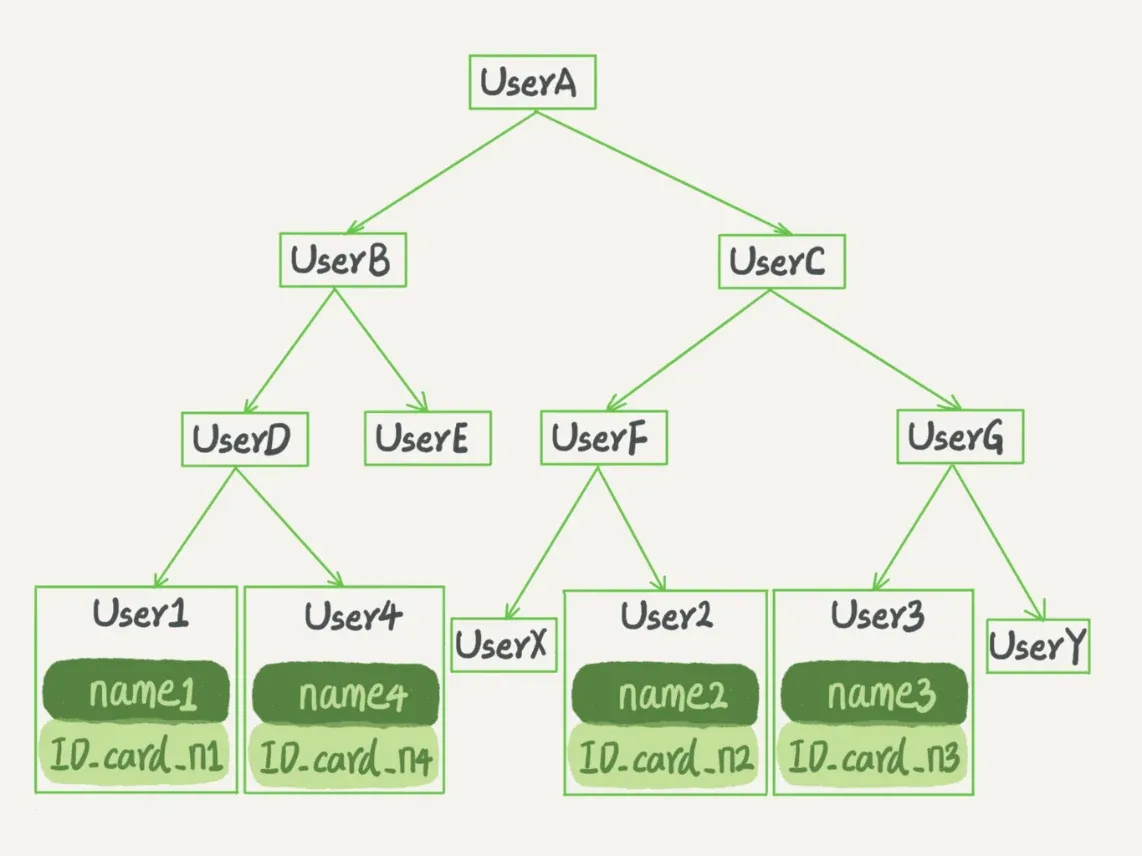
N叉树
- 大多数的数据库存储并没有采用二叉树,原因:索引不仅仅存在于内存中,还要写到磁盘上
- 对于有100W节点的平衡二叉树,树高为20,即一次查询可能需要访问20个数据块
- 假设随机读取HDD上一个数据块需要10ms左右的寻址时间,即一次查询可能需要200ms — 慢成狗
- 为了让一个查询尽量少的读取磁盘,就必须让查询过程访问尽量少的数据块,因此采用N叉树
- N的大小取决于数据页的大小和索引大小,在InnoDB中,以INT(4 Bytes)字段为索引,假设页大小为16KB,并采用Compact行记录格式,N大概是745
- 假设树高还是4(树根的数据块总是在内存中),数据量可以达到
745^3 = 4.1亿,访问这4亿行的表上的INT字段索引,查找一个值最多只需要读取3次磁盘
- N叉树由于在读写上的性能优点以及适配HDD的访问模式,被广泛应用于数据库引擎中
InnoDB的索引
索引是在存储引擎层实现的,没有统一的索引标准,不同存储引擎的索引的工作方式是不一样的,哪怕多个存储引擎支持同一类型的索引,其底层的实现也可能不同的
索引组织表
表都是根据主键顺序以索引的形式存放的,这种存储方式称为索引组织表,每一个索引在InnoDB里面都对应一棵B+树
# 建表
CREATE TABLE T(
id INT PRIMARY KEY,
k INT NOT NULL,
INDEX (k)
) ENGINE=INNODB;
# 初始化数据
R1 : (100,1)
R2 : (200,2)
R3 : (300,3)
R4 : (500,5)
R5 : (600,6)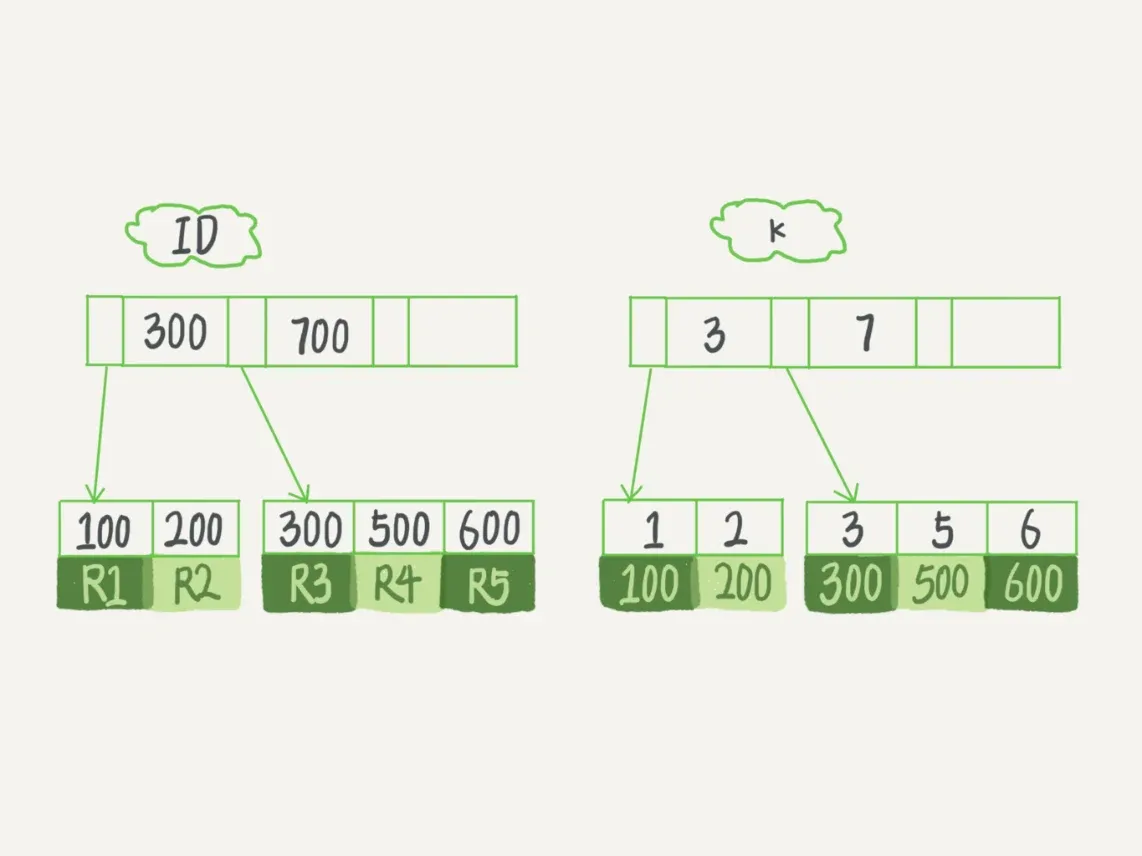
- 根据叶子节点的内容,索引类型分为聚簇索引(clustered index)和二级索引(secondary index)
- 聚簇索引的叶子节点存储的是整行数据
- 二级索引的叶子节点存储的是主键的值
select * from T where ID=500:只需要搜索ID树select * from T where k=5:先搜索k树,得到ID的值为500,再到ID树搜索,该过程称为 回表- 基于二级索引的查询需要多扫描一棵索引树,因此尽量使用主键查询
维护索引
- B+树为了维护索引的有序性,在插入新值时,需要做必要的维护
- 如果新插入的行ID为700,只需要在R5的记录后插入一个新记录
- 如果新插入的行ID为400,需要逻辑上(实际采用链表的形式,直接追加)挪动R3后面的数据,空出位置
- 如果R5所在的数据页已经满了,根据B+树的算法,需要申请一个新的数据页,然后将部分数据挪过去,称为 页分裂
- 页分裂的影响:性能、数据页的利用率
- 页合并:页分裂的逆过程
- 当相邻两个页由于删除了数据,利用率很低之后,会将数据页合并
自增主键
- 逻辑:如果主键为自增,并且在插入新记录时不指定主键的值,系统会获取当前主键的最大值+1作为新记录的主键
- 适用于递增插入的场景,每次插入一条新记录都是追加操作,既不会涉及其他记录的挪动操作,也不会触发页分裂
- 如果采用业务字段作为主键,很难保证有序插入,写数据的成本相对较高
- 主键长度越小,二级索引占用的空间也就越小;在一般情况下,创建一个自增主键,这样二级索引占用的空间最小
- 适合直接采用业务字段做主键的场景:KV场景(只有一个唯一索引)
- 无须考虑二级索引的占用空间问题
- 无须考虑二级索引的回表问题
重建索引
# 重建二级索引
ALTER TABLE T DROP INDEX k;
ALTER TABLE T ADD INDEX(k);
# 重建聚簇索引
ALTER TABLE T DROP PRIMARY KEY;
ALTER TABLE T ADD PRIMARY KEY(id);- 重建索引的原因
- 索引可能因为删除和页分裂等原因,导致数据页有空洞
- 重建索引的过程会创建一个新的索引,把数据按顺序插入
- 这样页面的利用率最高,使得索引更紧凑,更省空间
- 重建二级索引k是合理的,可以达到省空间的目的
- 重建聚簇索引是不合理的
- 不论是删除聚簇索引还是创建聚簇索引,都会将整个表重建
- 替代语句:
ALTER TABLE T ENGINE=INNODB
索引优化
覆盖索引
# 建表
CREATE TABLE T (
ID INT PRIMARY KEY,
k INT NOT NULL DEFAULT 0,
s VARCHAR(16) NOT NULL DEFAULT '',
INDEX k(k)
) ENGINE=INNODB;
# 初始化数据
INSERT INTO T VALUES (100,1,'aa'),(200,2,'bb'),(300,3,'cc'),(500,5,'ee'),(600,6,'ff'),(700,7,'gg');
需要回表的查询
SELECT * FROM T WHERE k BETWEEN 3 AND 5- 在k树上找到k=3的记录,取得ID=300
- 再到ID树上查找ID=300的记录,对应为R3
- 在k树上取下一个值k=5,取得ID=500
- 再到ID树上查找ID=500的记录,对应为R4
- 在k树上取下一个值k=6,不满足条件,循环结束
整个查询过程读了k树3条记录,回表了2次
不需要回表的查询
SELECT ID FROM T WHERE k BETWEEN 3 AND 5- 只需要查ID的值,而ID的值已经在k树上,可以直接提供查询结果,不需要回表,因为k树已经覆盖了我们的查询需求,因此称为 覆盖索引
- 覆盖索引可以减少树的搜索次数,显著提升查询性能,因此使用覆盖索引是一个常用的性能优化手段
- 扫描行数
- 在存储引擎内部使用覆盖索引在索引k上其实是读取了3个记录,
- 但对于MySQL的Server层来说,存储引擎返回的只有2条记录,因此MySQL认为扫描行数为2
联合索引
CREATE TABLE `user` (
`id` INT(11) NOT NULL,
`id_card` VARCHAR(32) DEFAULT NULL,
`name` VARCHAR(32) DEFAULT NULL,
`age` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `id_card` (`id_card`),
KEY `name_age` (`name`,`age`)
) ENGINE=InnoDB高频请求:根据id_card查询name。可以建立联合索引(id_card,name),达到覆盖索引的效果
最左前缀原则
- 只要满足最左前缀,就可以利用索引来加速检索,最左前缀有2种情况
- 联合索引的最左N个字段
- 字符串索引的最左M个字符
- 建立联合索引时,定义索引内字段顺序的原则
- 复用:如果通过调整顺序,可以少维护一个索引,往往优先考虑这样的顺序
- 空间:维护
(name,age)+age比维护(age,name)+name所占用的空间更少
索引下推
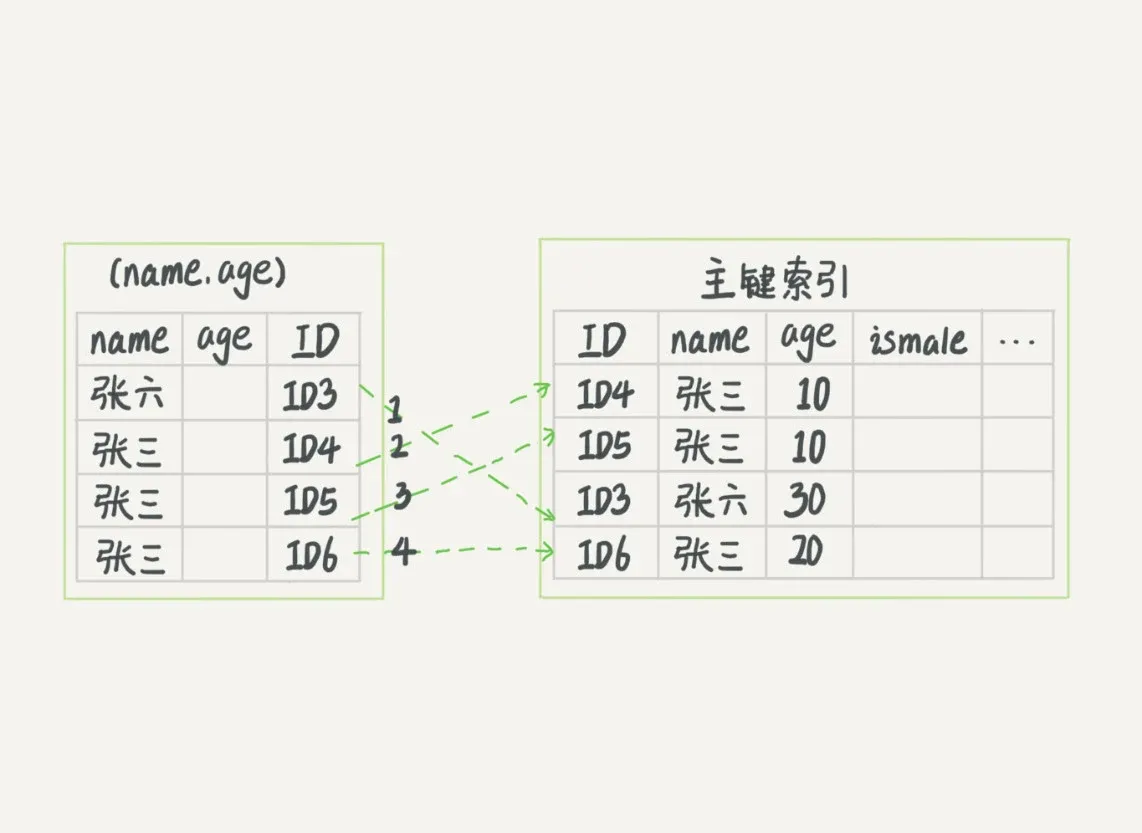
SELECT * FROM tuser WHERE name LIKE '张%' AND age=10 AND ismale=1;- 依据最左前缀原则,上面的查询语句只能用张,找到第一个满足条件的记录ID3(优于全表扫描)
- 然后判断其他条件是否满足
- 在MySQL 5.6之前,只能从ID3开始一个个回表,到聚簇索引上找出对应的数据行,再对比字段值
- 这里暂时忽略MRR:在不影响排序结果的情况下,在取出主键后,回表之前,会对所有获取到的主键进行排序
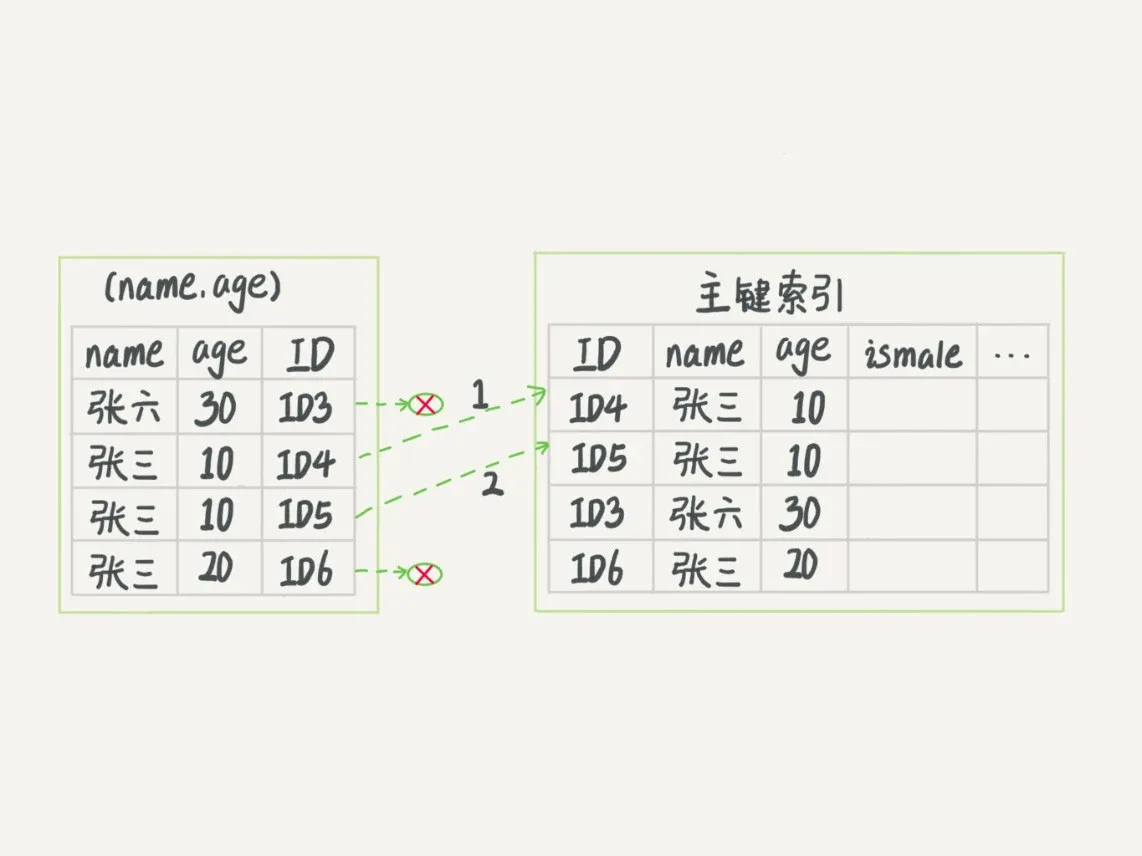
- 在MySQL 5.6引入了下推优化(index condition pushdown)
- 可以在索引遍历过程中,对索引所包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数
- 在MySQL 5.6之前,只能从ID3开始一个个回表,到聚簇索引上找出对应的数据行,再对比字段值
无索引下推,回表4次
采用索引下推,回表2次
普通索引和唯一索引
- 维护一个市民系统,有一个字段为身份证号,业务代码能保证不会写入两个重复的身份证号(如果业务无法保证,可以依赖数据库的唯一索引来进行约束),常用SQL查询语句:
SELECT name FROM User WHERE id_card = 'XXX' - 建立索引
- 身份证号比较大,不建议设置为主键
- 从性能角度出发,选择普通索引还是唯一索引?
假设字段k上的值都不重复
查询过程
- 查询语句:
SELECT id FROM T WHERE k=5 - 查询过程
- 通过B+树从根开始,按层搜索到叶子节点,即上图中右下角的数据页
- 在数据页内部通过二分法来定位具体的记录
- 普通索引
- 查找满足条件的第一个记录
(5,500),然后查找下一个,直到找到第一个不满足k=5的记录
- 查找满足条件的第一个记录
- 唯一索引
- 由于索引定义了唯一性记录,查找到第一个满足条件的记录后,就会停止继续查找
性能差异
InnoDB的数据是按照数据页为单位进行读写的,默认为16KB,当需要读取一条记录时,并不是将这个记录本身从磁盘读出来,而是以数据页为单位进行读取的。当找到k=5的记录时,它所在的数据页都已经在记录内存里了,对于普通索引而言,只需要多一次指针寻找和多一次计算,CPU消耗很低。
- 如果k=5这个记录恰好是所在数据页的最后一个记录,那么如果要取下一个记录,就需要读取下一个数据页
- 对于整型字段索引,一个数据页(16KB,compact格式)可以存放大概745个值
change buffer
- 当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InooDB会将这些更新操作缓存在change buffer中,这样就不需要从磁盘中读入这个数据页了。
- 在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行change buffer中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
- change buffer实际上是可以持久化的数据,在内存中有拷贝,也会被写入到磁盘上。
- 将更新操作先记录在change buffer,减少读磁盘,语句的执行速度会得到明显的提升。而且,数据读入内存是需要占用buffer pool的,所以这种方式还能够避免占用内存,提高内存利用率。
merge
- merge:将change buffer中的操作应用到原数据页,得到最新结果的过程称为merge
- merge的执行过程
- 从磁盘读入数据页到内存(老版本的数据页)
- 从change buffer里找出这个数据页的change buffer记录(可能多个)
- 然后依次执行,得到新版本的数据页记录
- 写入redolog,包含内容:数据页的变更+change buffer的变更
- merge执行完后,内存中的数据页和change buffer所对应的磁盘页都还没修改,属于脏页,通过其他机制,脏页会被刷新到对应的物理磁盘页
- 触发时机
- 访问这个数据页会触发merge
- 系统有后台线程会定期merge
- 在数据库正常关闭(shutdown)的过程中
change buffer的使用场景
- 因为merge的时候是真正进行数据更新的时刻,而change buffer的主要目的就是将记录的变更动作缓存下来,所以在一个数据页做merge之前,change buffer记录的变更越多(也就是这个页面上要更新的次数越多),收益就越大。因此,对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时change buffer的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
- 反过来,假设一个业务的更新模式是写入之后马上会做查询,那么即使满足了条件,将更新先记录在change buffer,但之后由于马上要访问这个数据页,会立即触发merge过程。这样随机访问IO的次数不会减少,反而增加了change buffer的维护代价。所以,对于这种业务模式来说,change buffer反而起到了副作用。
# 默认25,最大50
mysql> SHOW VARIABLES LIKE '%innodb_change_buffer_max_size%';
+-------------------------------+-------+
| Variable_name | Value |
+-------------------------------+-------+
| innodb_change_buffer_max_size | 25 |
+-------------------------------+-------+change buffer + redolog
- redolog记录:节省记录随机写磁盘的IO消耗(顺序写)
- change buffer记录:节省记录随机读磁盘的IO消耗
更新过程
插入一个新记录(4,400)
- 第一种情况是,这个记录要更新的目标页在内存中,普通索引和唯一索引对更新语句性能影响的差别不大。
- 第二种情况是,这个记录要更新的目标页不在内存中。这时,InnoDB的处理流程如下:
- 对于唯一索引来说,需要将数据页读入内存,判断到没有冲突,插入这个值,语句执行结束;
- 对于普通索引来说,则是将更新记录在change buffer,语句执行就结束了。
- 将数据从磁盘读入内存涉及随机IO的访问,是数据库里面成本最高的操作之一。change buffer因为减少了随机磁盘访问,所以对更新性能的提升是会很明显的。
建议关闭change buffer记录的场景,如果所有的更新后面,都伴随着对这个记录的查询,控制参数innodb_change_buffering
mysql> SHOW VARIABLES LIKE '%innodb_change_buffering%';
+-------------------------+-------+
| Variable_name | Value |
+-------------------------+-------+
| innodb_change_buffering | all |
+-------------------------+-------+
none / inserts / deletes / changes / purges / all
# change buffer的前身是insert buffer,只能对insert操作进行优化索引选择
- 优化器选择索引,目的是找到一个最优的执行方案,并用最小的代价去执行语句,大多数时候优化器都能找到正确的索引
- 在数据库里面,影响执行代价的因素
- 扫描行数
- 是否使用临时表
- 是否排序
- MySQL在真正开始执行语句之前,并不能精确地知道满足条件的记录有多少,只能统计索引的区分度来估算记录数(不准确的),基数(cardinality)越大(不同的值越多),索引的区分度越好
mysql> SHOW INDEX FROM t;
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type | Comment | Index_comment | Visible |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+
| t | 0 | PRIMARY | 1 | id | A | 100256 | NULL | NULL | | BTREE | | | YES |
| t | 1 | a | 1 | a | A | 100512 | NULL | NULL | YES | BTREE | | | YES |
| t | 1 | b | 1 | b | A | 100512 | NULL | NULL | YES | BTREE | | | YES |
+-------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+---------+基数统计
- 方法:采样统计
- 基数:InnoDB默认会选择N个数据页,统计这些页面上的不同值,得到一个平均值,然后乘以这个索引的页面数,就得到了这个索引的基数。
- 当变更的数据行数超过1/M的时候,会自动触发重新做一次索引统计。
- 两种存储索引统计的方式,可以通过设置参数
innodb_stats_persistent选择- ON:持久化存储统计信息,N=20,M=10
- OFF:统计信息只会存储在内存中,N=8,M=16
- 手动触发索引的采样统计:
ANALYZE TABLE t- 使用场景:当explain预估的rows与实际情况差距较大时
mysql> SHOW VARIABLES LIKE '%innodb_stats_persistent%';
+--------------------------------------+-------+
| Variable_name | Value |
+--------------------------------------+-------+
| innodb_stats_persistent | ON |
| innodb_stats_persistent_sample_pages | 20 |
+--------------------------------------+-------+索引选择异常
mysql> EXPLAIN SELECT * FROM t WHERE (a BETWEEN 1 AND 1000) AND (b BETWEEN 50000 AND 100000) ORDER BY b LIMIT 1;
+----+-------------+-------+------------+-------+---------------+------+---------+------+-------+----------+------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+-------+----------+------------------------------------+
| 1 | SIMPLE | t | NULL | range | a,b | b | 5 | NULL | 50128 | 1.00 | Using index condition; Using where |
+----+-------------+-------+------------+-------+---------------+------+---------+------+-------+----------+------------------------------------+- 这次优化器选择了索引b,而rows字段显示需要扫描的行数是50128:
- 扫描行数的估计值依然不准确;
- MySQL选错了索引
force index
mysql> EXPLAIN SELECT * FROM t FORCE INDEX(a) WHERE (a BETWEEN 1 AND 1000) AND (b BETWEEN 50000 AND 100000) ORDER BY b LIMIT 1;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | t | NULL | range | a | a | 5 | NULL | 1000 | 11.11 | Using index condition; Using where; Using filesort |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+修改语句
# 可以考虑修改语句,引导MySQL使用我们期望的索引
mysql> EXPLAIN SELECT * FROM t WHERE a BETWEEN 1 AND 1000 AND b BETWEEN 50000 AND 100000 ORDER BY b,a LIMIT 1;
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+
| 1 | SIMPLE | t | NULL | range | a,b | a | 5 | NULL | 1000 | 11.11 | Using index condition; Using where; Using filesort |
+----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+----------------------------------------------------+其他办法
- 新建一个更合适的索引
- 删除误用的索引
字符串索引
CREATE TABLE user(
id BIGINT UNSIGNED PRIMARY KEY,
name VARCHAR(64),
email VARCHAR(64)
) ENGINE=InnoDB;
# 创建索引
ALTER TABLE user ADD INDEX index1(email);
ALTER TABLE user ADD INDEX index2(email(6));
# 查询
SELECT id,name,email FROM user WHERE email='[email protected]';index1
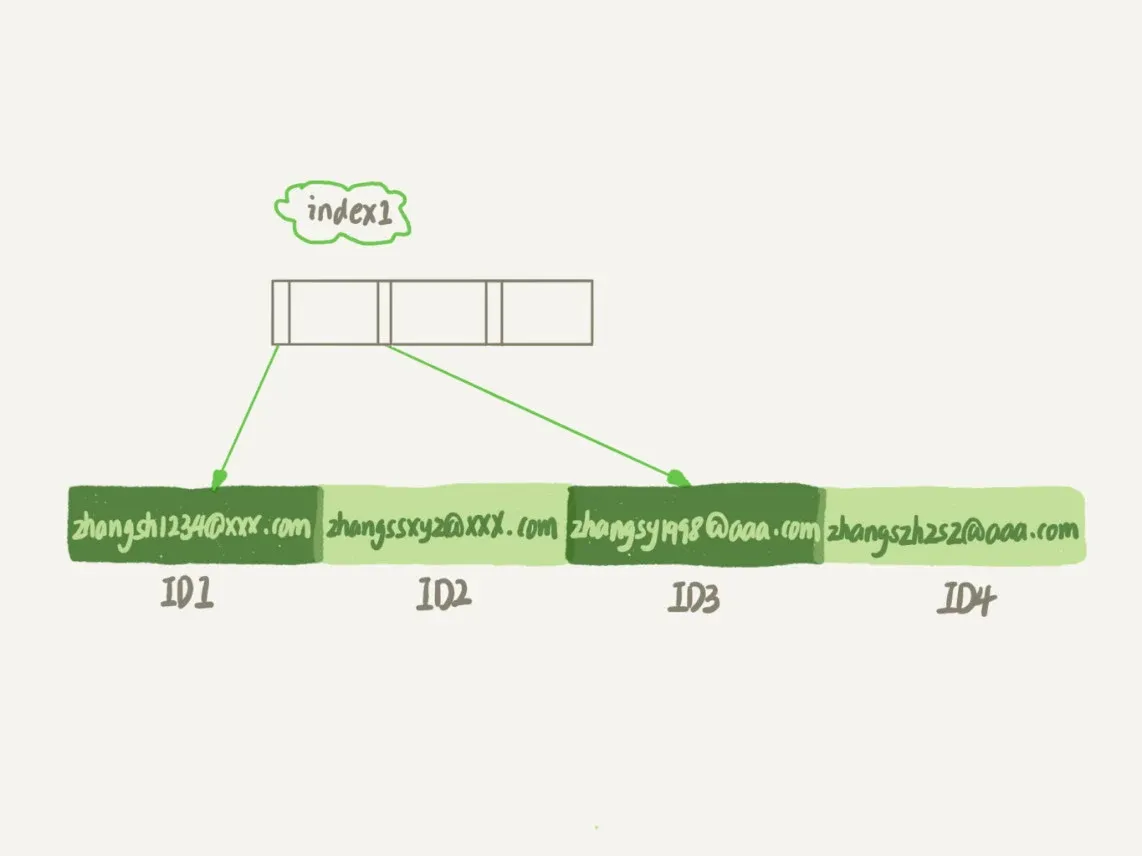
- 索引长度:包含了每个记录的整个字符串
- 执行顺序:
- 从index1索引树找到满足索引值是’[email protected]’的这条记录,取得ID2的值;
- 到主键上查到主键值是ID2的行,判断email的值是正确的,将这行记录加入结果集;
- 取index1索引树上刚刚查到的位置的下一条记录,发现已经不满足email=‘[email protected]’的条件了,循环结束。
- 这个过程中,只需要回主键索引取一次数据,所以系统认为只扫描了一行
index2
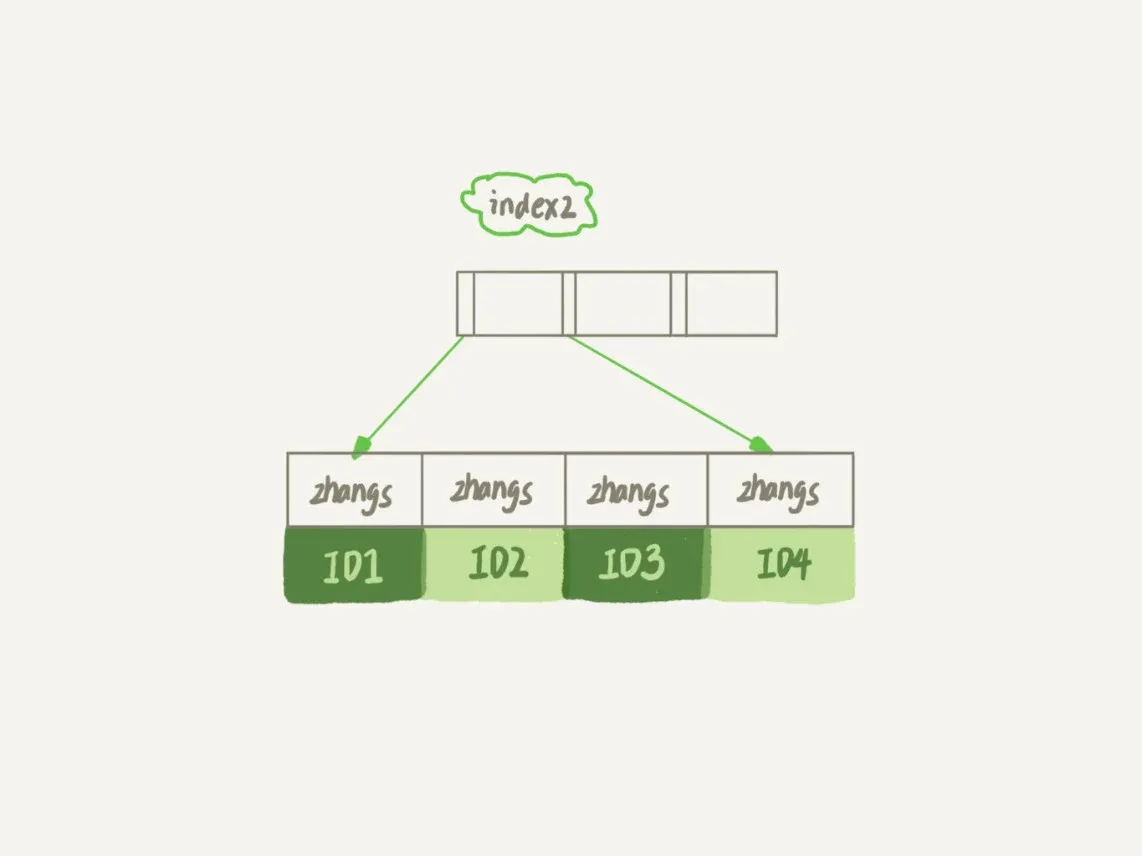
- 索引长度:对于每个记录都是只取前6个字节
- 执行顺序:
- 从index2索引树找到满足索引值是’zhangs’的记录,找到的第一个是ID1;
- 到主键上查到主键值是ID1的行,判断出email的值不是’[email protected]’,这行记录丢弃;
- 取index2上刚刚查到的位置的下一条记录,发现仍然’zhangs’,取出ID2,再到ID索引上取整行然后判断,这次值对了,将这行记录加入结果集;
- 重复上一步,直到在idxe2上取到的值不是’zhangs’时,循环结束。
- 整个过程,要回主键索引取4次数据,也就是扫描了4行。
- 假设index2为
email(7),满足前缀zhangss只有一个,只需要回表一次- 使用前缀索引,定义好长度,就可以做到既节省空间,又不用额外增加太多的查询成本。
- 在建立索引时关注的是区分度,区分度越高,意味着重复的键值越少,可以通过统计索引上有多少个不同的值来判断要使用多长的前缀。
前缀索引与覆盖索引
SELECT id,email FROM user WHERE email='[email protected]';- 使用index1的话,可以利用覆盖索引,从index1查到结果后直接就返回了,不需要回到ID索引再去查一次
- 使用index2的话,就不得不回到ID索引再去判断email字段的值
- 即使将index2的定义修改为email(18)的前缀索引,虽然index2已经包含了所有的信息,但InnoDB还是要回到id索引再查一下,因为系统并不确定前缀索引的定义是否截断了完整信息。
- 使用前缀索引就用不上覆盖索引对查询性能的优化
遇到前缀的区分度不够好的情况时
倒序存储
存储身份证号的时候把它倒过来存,每次查询的时候,你可以这么写
SELECT field_list FROM t WHERE id_card = REVERSE('input_id_card_string');使用hash字段
ALTER TABLE t ADD id_card_crc INT UNSIGNED, ADD INDEX(id_card_crc);
SELECT field_list FROM t WHERE id_card_crc=CRC32('input_id_card_string') AND id_card='input_id_card_string';- 每次插入新记录的时候,都需要使用
CRC32()函数得到校验码 - 由于校验码可能会冲突,因此查询语句的条件需要加上id_card(精确匹配)
- 索引的长度变为了4个字节,比直接用身份证作为索引所占用的空间小很多
异同点
- 都不支持范围查询,只支持等值查询
- 空间占用
- 倒序存储:N个字节的索引
- 使用hash字段:字段+索引
- CPU
- 倒序存储:每次读写都需要额外调用一次
REVERSE函数,开销比CRC32函数略小 - 增加hash字段:每次读写都需要额外调用一次
CRC32函数
- 倒序存储:每次读写都需要额外调用一次
- 查询效率
- 增加hash字段方式的查询性能会更加稳定一些
- CRC32虽然会有一定的冲突概率,但概率非常低,可以认为平均扫描行数接近1
- 倒序存储一般会用到前缀索引,这会增加扫描行数(无法利用覆盖索引,必须回表)
- 增加hash字段方式的查询性能会更加稳定一些