深入解析 MySQL 事务隔离级别,包括脏读、不可重复读、幻读等并发问题。详细阐述 MVCC 实现原理、Read View 机制及如何避免长事务,助你优化数据库性能。
当数据库上有多个事务同时执行的时候,就可能出现脏读(dirty read)、不可重复读(non-repeatable read)、幻读(phantom read)的问题,为了解决这些问题,就有了“隔离级别”的概念。
事务隔离
隔离级别
mysql> show variables like 'transaction_isolation';
+-----------------------+-----------------+
| Variable_name | Value |
+-----------------------+-----------------+
| transaction_isolation | REPEATABLE-READ |
+-----------------------+-----------------+
1 row in set, 1 warning (0.00 sec)SQL标准的事务隔离级别包括:读未提交(read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(serializable ),这4种隔离级别,并行性能依次降低,效率依次降低,安全性依次提高。可以这么理解:
- 读未提交:别人改数据的事务尚未提交,我在我的事务中也能读到。
- 读已提交:别人改数据的事务已经提交,我在我的事务中才能读到。
- 可重复读:别人改数据的事务已经提交,我在我的事务中也不去读。
- 串行:我的事务尚未提交,别人就别想改数据。
样例
mysql> create table T(c int) engine=InnoDB;
insert into T(c) values(1);
| 隔离级别 | V1 | V2 | V3 | 备注 |
|---|---|---|---|---|
| READ-UNCOMMITTED | 2 | 2 | 2 | |
| READ-COMMITTED | 1 | 2 | 2 | |
| REPEATABLE-READ | 1 | 1 | 2 | |
| SERIALIZABLE | 1 | 1 | 2 | 事务B在执行『1->2』时被锁住,等事务A提交后才能继续执行 |
实现
- 在实现上,数据库里面会创建一个视图(read-view),访问的时候会以视图的逻辑结果为准
- REPEATABLE-READ的视图是在事务启动时创建的,整个事务存在期间都用这个视图
- 事务启动:begin后的第一个DML语句,begin语句本身不会开启事务
- READ-COMMITTED的视图在每个SQL语句开始执行时创建的
- READ-UNCOMMITTED没有视图概念,直接返回记录上的最新值(内存,InnoDB Buffer Pool)
- SERIALIZABLE则直接用加锁(行锁)的方式来避免并行访问
多版本
变更记录:1->2->3->4
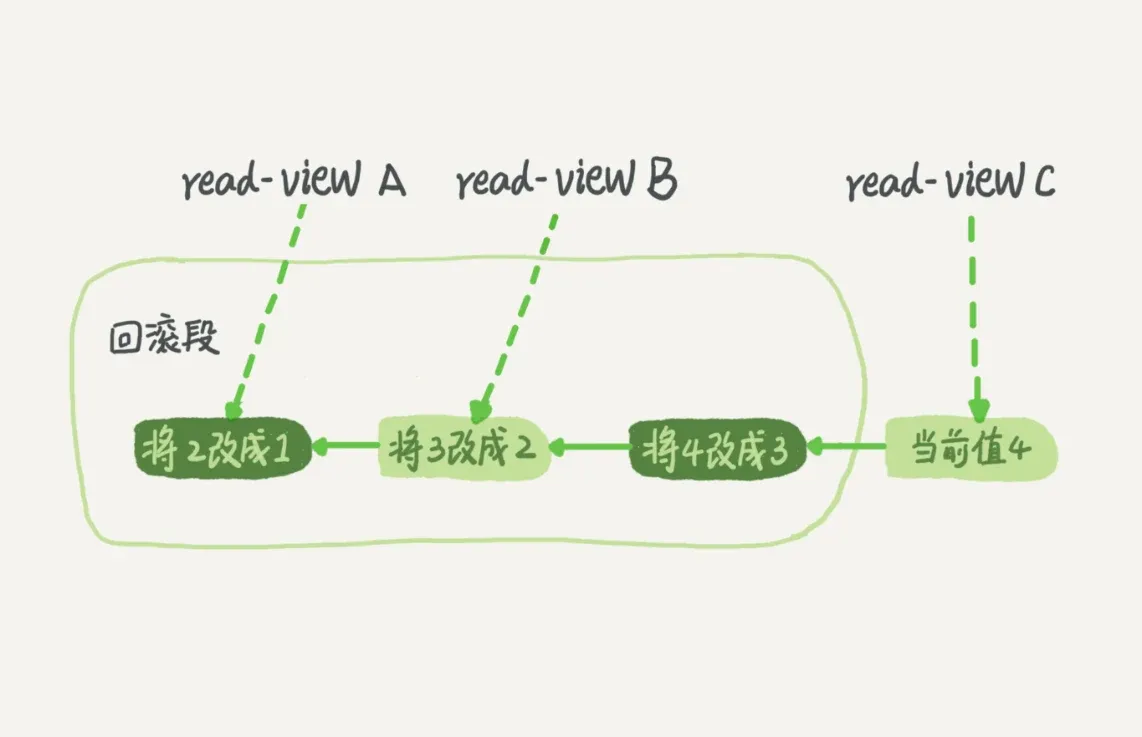
- 当前值为4,但在查询这条记录的时候,不同时刻启动的事务会有不同的视图
- 在视图A、B和C,这一个记录的值分别是1、2和4
- 同一条记录在系统中可以存在多个版本,这就是MVCC(多版本并发控制)
- 对于视图A,要得到1,必须将当前值依次执行图中的所有回滚操作
- 这会存在一定的性能开销
- 这里的视图是逻辑视图,并不是快照
- 这里的视图是InnoDB(存储引擎层)的read-view,也不是Server层都VIEW(虚表)
- 即使此时有另外一个事务正在将4改成5,这个事务跟视图A、B和C所对应的事务并不冲突
事务的启动方式
- 启动方式
- 显式启动事务,begin(start transaction) + commit/rollback
- set autocommit=0 + commit/rollback
- set autocommit=0:关闭自动提交
- 一些客户端框架会在默认连接成功后执行set autocommit=0,导致接下来的查询都在事务中
- 如果是长连接,就会导致意外的长事务
- 推荐方式
- set autocommit=1 + begin(start transaction) + commit/rollback
- set autocommit=1 + begin(start transaction) + (commit and chain)/(rollback and chain)
- 适用于频繁使用事务的业务
- 省去再次执行begin语句的开销
- 从程序开发的角度能够明确地知道每个语句是否处于事务中
避免长事务的方案
长事务
- 长事务意味着系统里面存在很老的事务视图
- 长事务随时可能访问数据库里面的任何数据,在这个事务提交之前,它可能用到的回滚段都必须保留
- 因此这会导致占用大量的存储空间
- <= MySQL5.5,回滚段跟数据字典一起放在ibdata文件里,即使长事务最终提交,回滚段被清理,文件也不会变小
- RC隔离级别一般不会导致回滚段过长的问题
# 查询持续时间超过60s的事务
mysql> select * from information_schema.innodb_trx
where TIME_TO_SEC(timediff(now(),trx_started))>60;应用开发端
- 确保set autocommit=1,可以通过general_log来确认
- 确认程序中是否有不必要的只读事务
- 业务连接数据库的时候,预估每个语句执行的最长时间(max_execution_time)
mysql> SHOW VARIABLES LIKE '%general_log%';
+------------------+-----------------------------------------+
| Variable_name | Value |
+------------------+-----------------------------------------+
| general_log | OFF |
| general_log_file | D:\mysql-8.0.16-winx64\data\MorsoLi.log |
+------------------+-----------------------------------------+
2 rows in set, 1 warning (0.05 sec)# Introduced 5.7.8
# 0 -> disable
mysql> SHOW VARIABLES LIKE '%max_execution_time%';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| max_execution_time | 0 |
+--------------------+-------+数据库端
- 监控information_schema.innodb_trx,设置长事务阈值,告警或者Kill(工具:pt-kill)
- 在业务功能的测试阶段要求输出所有的general_log,分析日志行为并提前发现问题
RR与RC
RR
- RR的实现核心为一致性读(consistent read)
- 事务更新数据的时候,只能用当前读(current read)
- 如果当前的记录的行锁被其他事务占用的话,就需要进入锁等待
- 在RR隔离级别下,只需要在事务启动时创建一致性读视图,之后事务里的其他查询都共用这个一致性读视图
- 对于RR,查询只承认事务启动前就已经提交的数据
- 表结构不支持RR,因为表结构没有对应的行数据,也没有row trx_id
快照
- 在RR隔离级别下,事务在启动的时候保存了一个快照,快照是基于整库的
- 在InnoDB,每个事务都有一个唯一的事务ID(transaction id)
- 在事务开始的时候向InnoDB的事务系统申请的,按申请的顺序严格递增
- 每行数据都有多个版本,每次事务更新数据的时候,都会生成一个新的数据版本
- 事务会把自己的transaction id赋值给这个数据版本的事务ID,记为
row trx_id,每个数据版本都有对应的row trx_id - 同时也要逻辑保留旧的数据版本,通过新的数据版本和
undolog可以计算出旧的数据版本
- 事务会把自己的transaction id赋值给这个数据版本的事务ID,记为
RC
- 在RC隔离级别下,每个语句执行前都会重新计算出一个新的一致性读视图
- 在RC隔离级别下,再来考虑样例1,事务A与事务B的查询语句的结果
START TRANSACTION WITH CONSISTENT SNAPSHOT的原意:创建一个持续整个事务的一致性视图- 在RC隔离级别下,一致性读视图会被重新计算,等同于普通的
START TRANSACTION
- 在RC隔离级别下,一致性读视图会被重新计算,等同于普通的
- 事务A的查询语句的一致性读视图是在执行这个语句时才创建的
- 数据版本
(1,3)未提交,不可见 - 数据版本
(1,2)提交了,并且在事务A当前的一致性读视图创建之前提交的,可见 - 因此事务A的查询结果为2
- 数据版本
- 事务B的查询结果为3
- 对于RC,查询只承认语句启动前就已经提交的数据
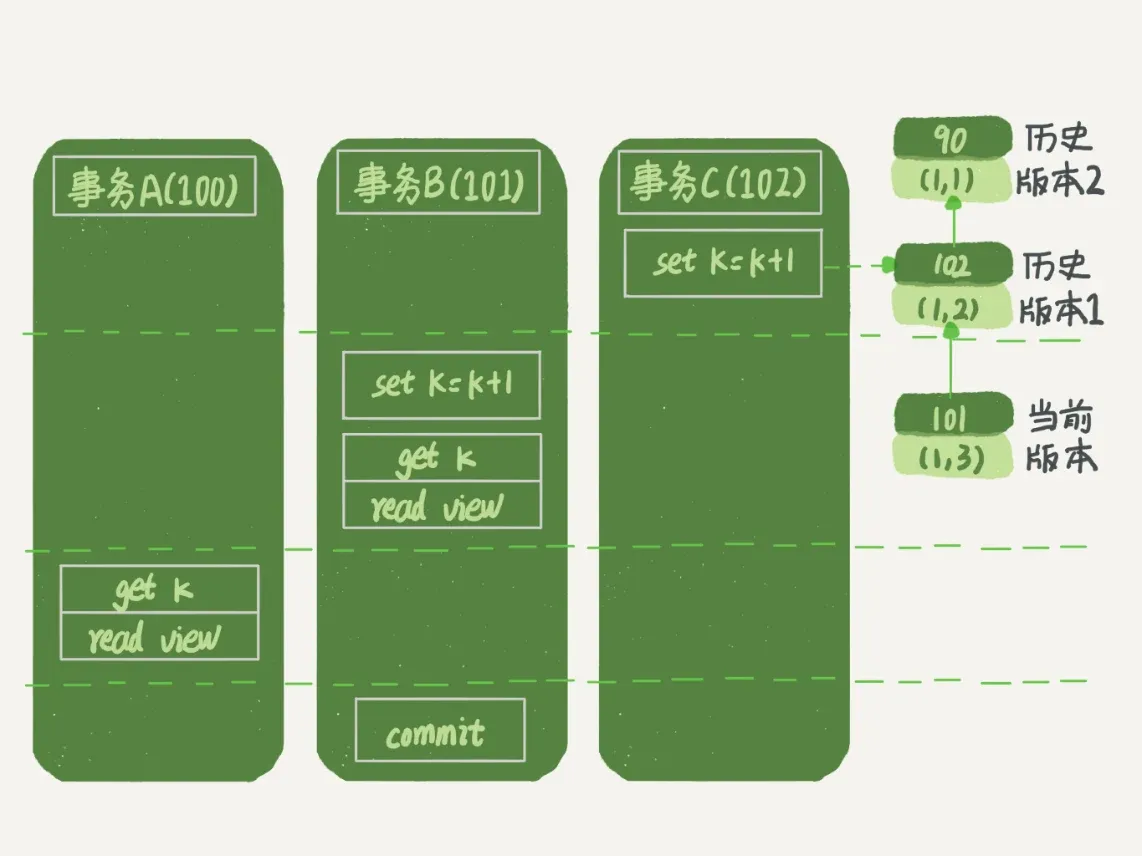
样例1事务ABC的执行流程(autocommit=1)
| 事务A | 事务B | 事务C |
|---|---|---|
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| START TRANSACTION WITH CONSISTENT SNAPSHOT; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| UPDATE t SET k=k+1 WHERE id=1; | ||
| SELECT k FROM t WHERE id=1; | ||
| SELECT k FROM t WHERE id=1; | ||
| COMMIT; | ||
| COMMIT; |