本文深入比较 Semantic Kernel 和 LangChain 两大 LLM 应用开发框架。通过构建支持联网的智能 AI 助手,分析其关键概念、语言支持及实现差异,助你选择最适合的工具。
Semantic Kernel 和 LangChain 是当前比较受欢迎的两款 LLMs 应用开发框架,笔者通过实现一个支持联网功能的智能 AI 助手来比较分析下两个框架的差异(适合自己场景的工具才是最好滴 🧑🏻💻)
关键概念对应(非严谨版)
| LangChain | Semantic Kernel | 备注 |
|---|---|---|
| Chains | Kernel | 构造调用序列 |
| Agents | Planner | 自动规划任务以满足用户的需求 |
| Tools | Plugins (semantic functions + native function) | 可在不同应用之间重复使用的自定义组件 |
| Memory | Memory | 将上下文和嵌入存储在内存或其他存储中 |
语言支持
| 编程语言 | LangChain | Semantic Kernel |
|---|---|---|
| Python | ✅ | ✅ |
| JavaScript | ✅ | ❌ |
| C# | ❌ | ✅ |
| Java | ✅ | ✅ |
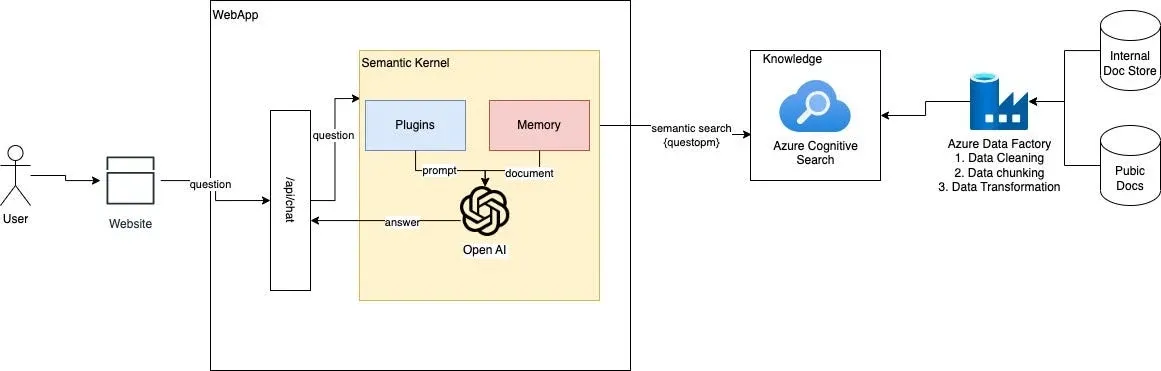
基于Semantic Kernel 构建应用过程概览
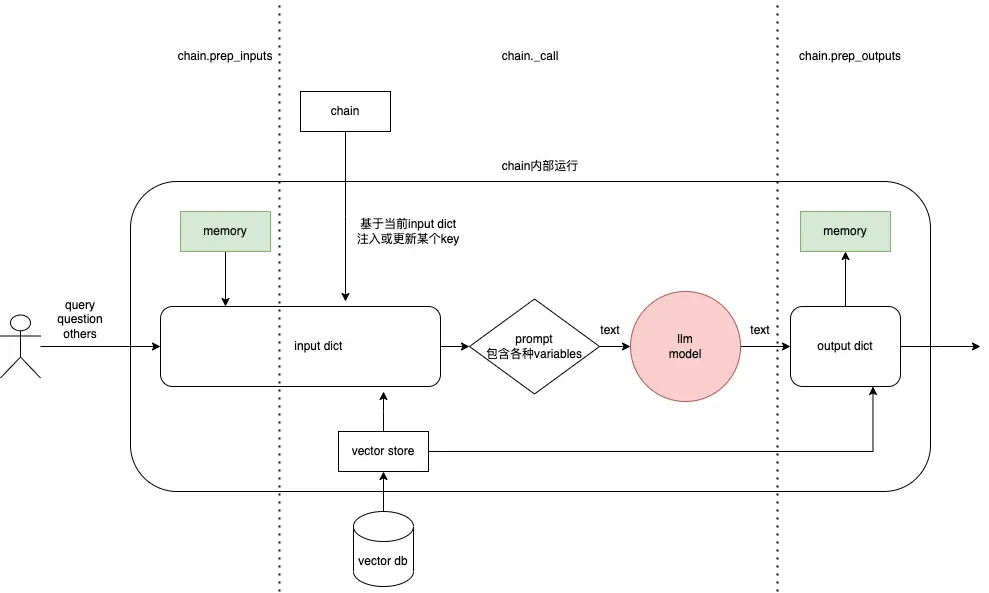
基于LangChain 构建应用过程概览
AI 助手的设计
- 能够结合上下文识别提问意图
- 使用向量数据库获取相关信息
- 回答内容参考自最新外部知识
功能
意图识别
首先根据历史对话记录确定用户的询问意图
LangChain 实现
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
from langchain.memory import ChatMessageHistory
from langchain.prompts.chat import ChatPromptTemplate, SystemMessagePromptTemplate
from langchain.retrievers.web_research import WebResearchRetriever
from langchain.vectorstores.chroma import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models.openai import ChatOpenAI
from langchain.utilities.google_search import GoogleSearchAPIWrapper
def _summarize_user_intent(self, query: str) -> str:
"根据历史对话,推断用户意图"
chat_history_str = ""
for item in self.chat_history.messages:
chat_history_str += f"{item}\n"
system_template = (
"你是一个中文AI助手,正在阅读用户和助手之间对话的记录。根据聊天历史和用户的问题,推断用户的真实意图。"
"聊天历史记录:```{chat_history_str}```\n 用户查询问题内容:```{query}```\n"
)
chat_template = ChatPromptTemplate(
messages=[SystemMessagePromptTemplate.from_template(system_template)]
)
llm_chain = LLMChain(llm=self.llm, prompt=chat_template)
uesr_intent = llm_chain({"chat_history_str": chat_history_str, "query": query})
return uesr_intent.get("text")Semantic Kernel实现
import os
import chromadb
import semantic_kernel as sk
from semantic_kernel.connectors.ai.open_ai import OpenAIChatCompletion, OpenAITextEmbedding
from semantic_kernel.connectors.memory.chroma import ChromaMemoryStore
from semantic_kernel.semantic_functions.chat_prompt_template import ChatPromptTemplate
from semantic_kernel.semantic_functions.prompt_template_config import PromptTemplateConfig
from semantic_kernel.semantic_functions.semantic_function_config import SemanticFunctionConfig
async def _summarize_user_intent(self, query: str)->str:
self.variables["query"] = query
system_template = (
"你是一个中文AI助手,正在阅读用户和助手之间对话的记录。根据聊天历史和用户的问题,推断用户的真实意图。"
"聊天历史记录:```{{$chat_history_str}}```\n 用户查询问题内容:```{{$query}}```\n"
)
prompt_config_dict = {
"type": "completion",
"description": "一个能推断用户意图的AI助手",
"completion": {
"temperature": 0.7,
"top_p": 0.5,
"max_tokens": 200,
"number_of_responses": 1,
"chat_system_prompt": system_template,
"presence_penalty": 0,
"frequence_penalty": 0
},
"inputs": {
"parameters":[
{
"name": "chat_history_str",
"description": "用户和助手所有消息历史记录",
"defaultValue": ""
},
{
"name": "query",
"description": "用户查询问题内容",
"defaultValue": "",
}
]
}
}
prompt_config = PromptTemplateConfig.from_dict(prompt_config_dict)
prompt_template = ChatPromptTemplate(
template=system_template,
prompt_config=prompt_config,
template_engine=self.kernel.prompt_template_engine
)
user_intent_function_config = SemanticFunctionConfig(
prompt_config, prompt_template
)
user_intent_function = self.kernel.register_semantic_function(
skill_name=PLUGIN,
function_name="user_intent_function",
function_config=user_intent_function_config
)
response = await self.kernel.run_async(
user_intent_function, input_vars=self.variables
)
return str(response)信息检索功能
使用向量数据库 Chroma 存储嵌入后的文本向量,获取相关上下文
LangChain 实现
def _get_web_research_retriever(self):
vectorstore = Chroma(
embedding_function=OpenAIEmbeddings(), persist_directory="./chroma_db"
)
search = GoogleSearchAPIWrapper()
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore,
llm=self.llm,
search=search,
)
return web_research_retriever
def _get_context(self, user_intent: str)-> list[str]:
"从搜索引擎获取相关信息"
retriever = self._get_web_research_retriever()
docs = retriever.get_relevant_documents(user_intent)
context = [doc.page_content for doc in docs]
return contextSemantic Kernel实现
async def _get_context(self, query: str) -> list[str]:
kernel = sk.Kernel()
kernel.add_text_embedding_generation_service(
"openai-embedding",
OpenAITextEmbedding(
api_key=OPENAI_API_KEY,
model_id="text-embedding-ada-002"
)
)
kernel.register_memory_store(
memory_store=ChromaMemoryStore(client_settings=chromadb.Settings(persist_directory="./chroma_db"))
)
docs = await kernel.memory.search_async(collection="chatbot_collection", query=query)
context = [doc.text for doc in docs]
return context结合上下文(检索增强生成)
结合历史对话记录,回答用户问题
LangChain 实现
def _rag(self, context: list[str], query: str)-> str:
self.chat_history.add_message(query)
context_str = "\n\n".join(context)
system_template = (
"你是一个中文AI助手,请使用您在上下文中可以找到的信息来回答用户的问题,如果用户的问题与上下文中的信息无关,请说你不知道。"
"上下文内容:```{context_str}```\n"
)
user_template = ChatPromptTemplate(
messages=[SystemMessagePromptTemplate.from_template(system_template)] + self.chat_history.messages
)
llm_chain = LLMChain(llm=self.llm, prompt=user_template)
response = llm_chain({"context_str": context_str}).get("text")
self.chat_history.add_ai_message(response)
return responseSemantic Kernel实现
async def _rag(self, context: list[str], query: str)-> str:
context_str = "\n\n".join(context)
self.variables["context"] = context_str
system_template = (
"你是一个中文AI助手,请使用您在上下文中可以找到的信息来回答用户的问题,如果用户的问题与上下文中的信息无关,请说你不知道。"
"上下文内容:```{{$context_str}}```\n"
)
self.variables["query"] = query
user_template = "{{$chat_history}}" + f"{USER}" + "{{$query}}\n"
prompt_config_dict = {
"type": "completion",
"description": "一个智能助手",
"completion": {
"temperature": 0.7,
"top_p": 0.5,
"max_tokens": 200,
"number_of_responses": 1,
"chat_system_prompt": system_template,
"presence_penalty": 0,
"frequency_penalty": 0,
},
"input": {
"parameters": [
{
"name": "query",
"description": "用户查询问题内容",
"defaultValue": "",
},
{
"name": "context",
"description": "上下文内容",
"defaultValue": "",
},
{
"name": "chat_history",
"description": "用户和助手所有消息历史记录",
"defaultValue": "",
},
]
},
}
prompt_config = PromptTemplateConfig.from_dict(prompt_config_dict)
prompt_template = ChatPromptTemplate(
template=user_template,
prompt_config=prompt_config,
template_engine=self.kernel.prompt_template_engine
)
rag_function_config = SemanticFunctionConfig(prompt_config, prompt_template)
rag_function = self.kernel.register_semantic_function(
skill_name=PLUGIN,
function_name="rag_function",
function_config=rag_function_config
)
response = await self.kernel.run_async(rag_function, input_vars=self.variables)
self.variables["chat_history"] = f"{USER}: {query}\n{ASSISTANT}:{response}\n"
return str(response)问答功能实现
async def ask(self, query: str) -> str:
user_intent = await self._summarize_user_intent(query)
context_list = await self._get_context(user_intent)
response = await self._rag(context_list, query)
print(
"========\n"
f"问题:{query}\n"
f"用户意图:{user_intent}\n"
f"回答:{response}\n"
"========\n"
)
return response结论
Langchain更适合构建MVP,Semantic Kernel更适合生产级应用
Langchain更适合独立开发,Semantic Kernel更适合企业应用
LangChain 的优势在于丰富的组件支持,以WebResearchRetriever的封装实现为例,将向量数据库和搜索引擎结合起来,只需几行代码就可以完成复杂功能,加速MVP实现,需求验证。LangChain 的缺点主要是过度封装,Prompt 模板组件做这么抽象实在没必要,应用调试和生产环境可观测性方面都不太友好,软件工程方面的组织相对较差。
Semantic Kernel生态比起 LangChain 还差点,但是背靠大厂“巨硬”,这点也能快速赶上,设计整体奔着构建生产级应用去的,把LangChain的一些缺点基本都规避了。Semantic Kernel主要面向C#开发者,也支持Python,C#开发者只能选择Semantic Kernel。