Full Stack LLM Bootcamp 笔记,聚焦 LLMOps 实践。详细讲解大模型选择、评估、部署、Prompt 管理与持续改进,是 LLM 应用开发的实用清单。
国内各大厂商的大模型服务纷纷上线,应用密集落地应该是接下来的主旋律,将之前看过的 LLM Bootcamp 系列视频(由 The Full Stack 出品,内容由 11 节 talk 组成,质量很能打,感兴趣可以去看原视频)分享下。本篇主要是 LLMOps 这节讲座的笔记,包括如何选择基础模型、如何评估模型性能、模型的部署、如何管理Prompt的迭代过程、监控和持续改进,以及最后提出的测试驱动 LLM 应用开发的理念,比我的之前这篇更详尽,可以作为每个 LLM 应用开发者的一个 checklist,在应用国内基础语言模型服务时提供参考。
如何选择语言模型
兼顾需求和可用模型的优缺点
- 不同任务对模型质量、速度、成本、可定制化以及数据安全和许可的需求不同
- 目前闭源模型质量比较高,但开源模型更容易定制
- 许可限制会影响商业化应用
闭源模型与开源模型的比较标准
- 参数数量:参数越多表示模型规模越大,质量越高
- 上下文窗口大小:上下文窗口越大,模型理解能力越强
- 训练数据类型:多样性、代码、prompt和人类反馈训练数据皆重要
- 主观质量得分:基于实际使用情况给出的质量评分
- 推理速度:部分模型做了速度与质量的权衡
- 微调性:某些模型更适合微调
闭源模型具体对比

- GPT-4:最高质量
- GPT-3.5:仅次于 GPT-4,较快较廉价
- Claude:质量与 GPT-3.5 相近,全面训练数据
- Cohere 等其他模型:便宜且快但质量下降
开源模型具体对比

- Flan-T5:许可符合要求,质量较好
- LLama 系列:社区生态完善,但许可有限制
- OPT:类似早期 GPT-3,质量有限
- 开源可能会在今年年底前赶上 GPT-3.5 级别的性能
如何评估模型的性能
为何需要评估
- 语言模型容易出现错误,仅凭少量样本无法判断其性能
- 需要广泛的测试数据,评估模型在不同情况下的健壮性
- 影响用户对系统输出的信任度,关系到用户留存
评估面临的挑战
- 无法获取模型的训练数据分布信息
- 生成式输出难以进行定量评估
- 通用模型不同领域的表现参差不齐
- 单一指标难以概括模型的多样能力
如何构建评估数据集
- 采用渐进方式构建,从一开始就收集各类样本
- 利用语言模型自动生成更多测试用例
- 持续从用户反馈中获取新样本,发现瑕疵
- 考虑提高测试覆盖率,覆盖真实用例范围
如何设计评估指标
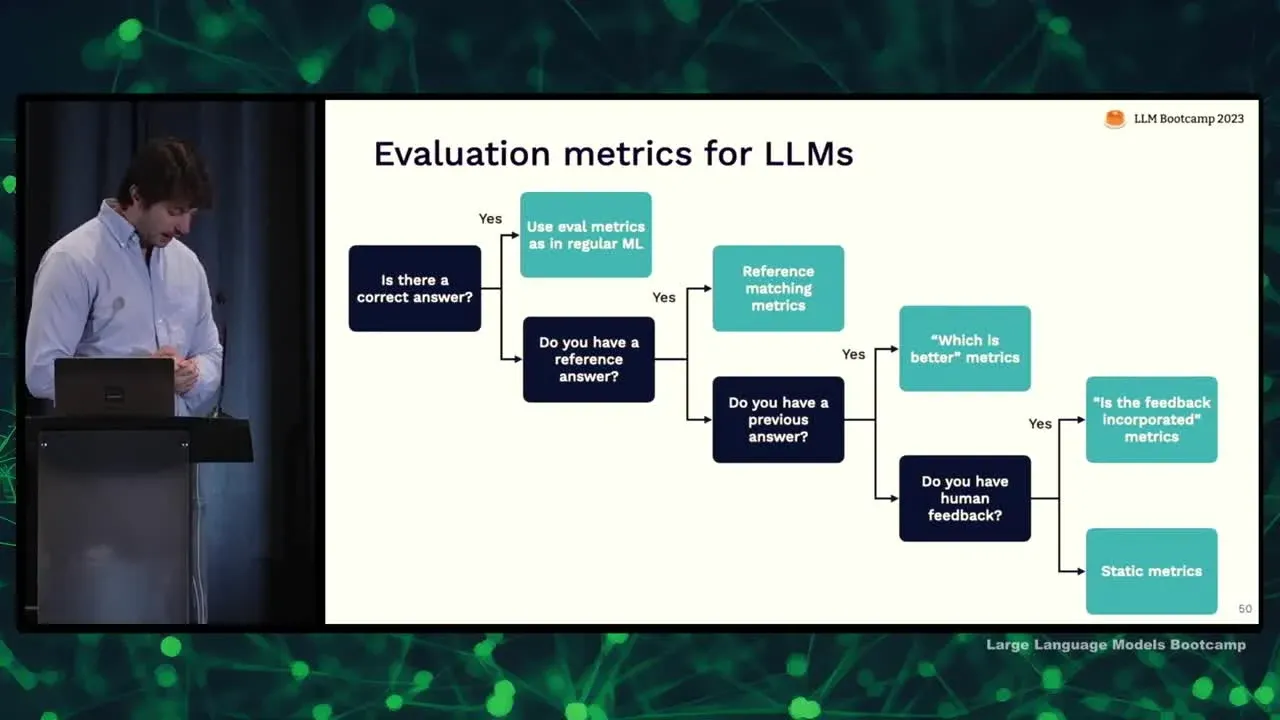
- 正确答案存在时,可以使用精确度等传统指标
- 无正确答案时,使用其他模型判断质量
- 可以设计不同的prompt,评估哪个更好、是否正确等
- 需要定量指标和定性判断相结合,不能仅仅依赖单一指标
如何评估
- 自动评估可加速迭代,但仍需人工检查结果
- 人工检查也可生成新的反馈数据,进入评估数据集
- 自动评估和人工检查需配合使用
语言模型的部署
基本部署方式
- 最简单的方式是前端直接调用语言模型 API
- 如果逻辑复杂,可以将语言模型封装在服务中,降低耦合
提高输出质量

- 自我批评(self-critique):使用第二个语言模型检验第一个模型的输出
- 多采样:对同一输入进行多次采样,选择最佳输出
- 模型集成:使用多个语言模型,对结果集成
开源模型部署
- 训练及部署开源语言模型较为复杂
- 可以使用一些现成的开源解决方案,如 Transformers 等
- 需要解决模型转换、部署托管等问题
注意事项
- 不同的质量优化技术会增加调用成本和延迟
- 需权衡成本和质量需求
- GPU 及其它硬件也会影响部署形式
如何管理 prompt 的迭代过程

缺少系统化的工具
因为这个系列 talk 是五月份发布的,过去三个月,当下已经有很多相关的管理工具了,既有之前的 MLOps 基础设施增加这类支持,如 Weights & Biases,Comet 和 MLflow,也有 HoneyHive,PromptLayer 这类新型的创业公司。
管理 prompt 的三个级别
- 级别一:简单记录 prompt,不追踪迭代
- 级别二:使用 Git 进行版本控制
- 级别三:使用专门的prompt追踪工具进行协同
Git 追踪 prompt 即可满足大多数团队需求
- Git 易用,符合现有工作流程
- 可以回溯 prompt 的变更历史
专业prompt追踪工具
- 与 Git 解耦,非技术人员也可以参与 prompt 设计
- 提供 UI 交互界面,直观反映 prompt 调整影响
监控和持续改进

监控指标
- 最重要的是监控用户满意度,关注业务指标
- 可以设定模型性能指标,如响应准确率、相似度等
- 监控常见问题,如无用回复、缓慢响应等
收集用户反馈
- 提供低摩擦反馈方式,如简单打分、填写表单等
- 分析反馈,总结用户不满意的主要原因
- 继续扩充反馈样本,关注长尾问题
持续优化 Prompt
- 根据反馈主题,调整 Prompt 的内容、长度、表示方式等
- 针对反馈提出的问题,设计更全面的 Prompt
- 验证修改是否解决了对应的问题
微调模型
- 使用反馈提取的数据进行监督微调
- 调整损失函数,优化模型关注用户关心的维度
- 测试微调后模型是否优化,防止过拟合
过程迭代
- 持续收集用户反馈和优化 Prompt
- 定期使用新数据微调模型,防止模型过时
- 测试驱动开发,及时发现和解决问题
测试驱动 LLM 应用开发
最后提出的测试驱动 LLM 应用开发的理念也很实用
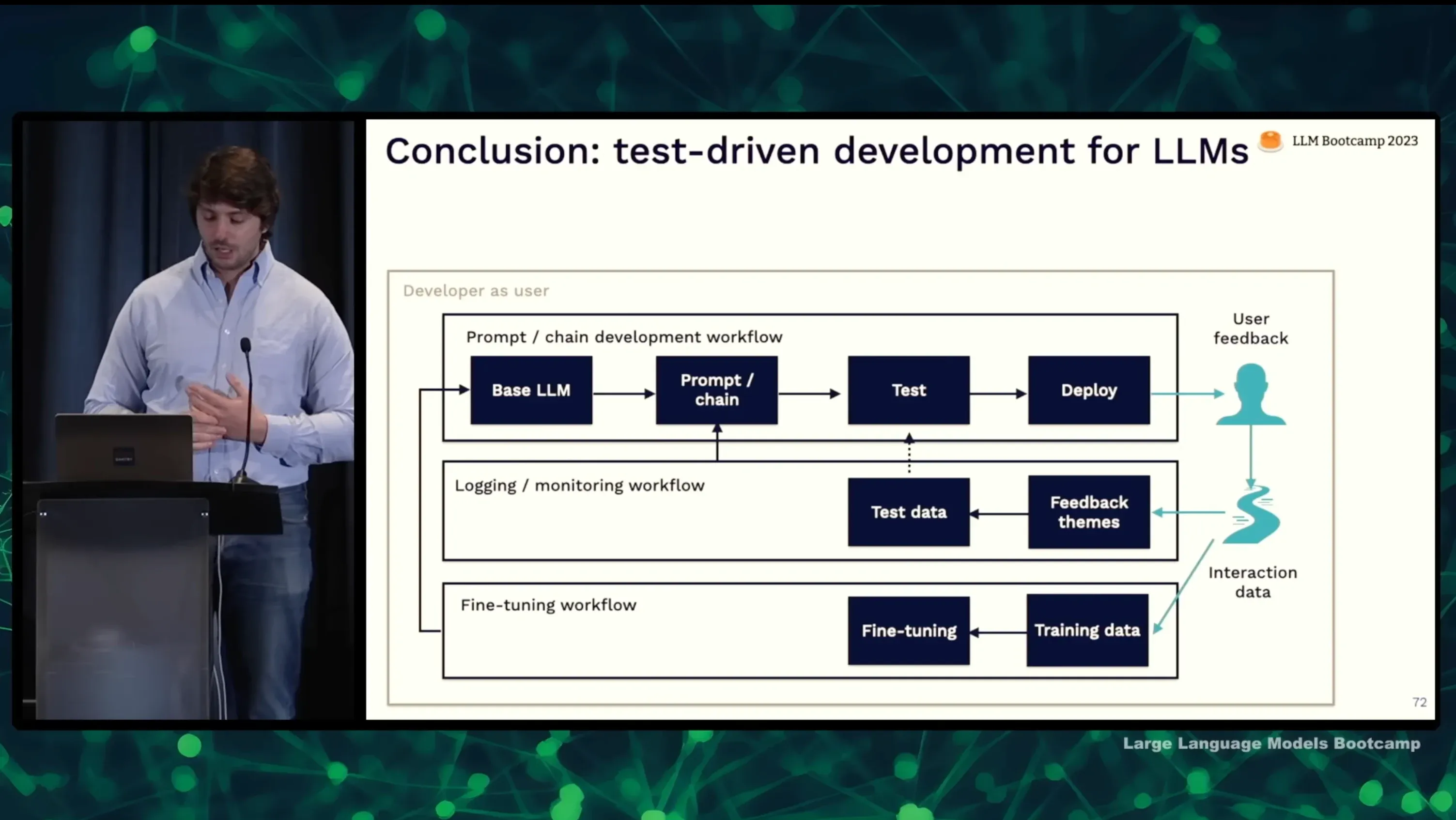
- Prompt 设计:根据要解决的问题,设计初版 Prompt
- 部署试用:将 Prompt 部署,开发者自己或者少量用户试用
- 收集用户反馈:收集用户使用过程中的反馈意见
- 日志分析:分析用户反馈,总结出主要问题类型
- 提取测试数据:从用户反馈中提取出相关的测试样本
- 测试评估:使用新的测试数据重新评估模型,找到不足
- Prompt 优化:针对发现的问题,优化 Prompt 设计
- 微调模型(可选):使用反馈数据微调模型
- 重复上述流程:不断迭代优化 Prompt 设计和模型