Vol.1:你支持AI“复活”逝者吗
大家好,Weekly Gradient 第1期内容已送达!前段时间,音乐人包小柏用 AI 重现女儿的声音和形象,商汤科技创始人汤晓鸥被公司以数字人的形式现身年会,“AI 复活”走入现实。然而“AI 复活”展现出来的科技人文关怀,没几天就变味了。多位已故明星李玟、乔任梁、高以翔被“复活”,登上微博热搜,但这些网友擅自的复活遭到了明星亲属的极力反对,关于AI“复活”逝者,你怎么看?
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
ARAGOG: Advanced RAG Output Grading:这篇论文测试了多种RAG算法的效果,使用检索精度和答案相似性这两个指标。这些方法包括句子窗口检索(通过优化文本块大小来提高检索和生成过程的性能)、文档摘要索引(通过索引文档摘要来提高检索效率,并使用全文文档生成响应)、假设文档嵌入(HyDE)(利用LLMs生成假设性答案,以增强文档检索的准确性)、多查询(将单个用户查询扩展为多个相似查询,以捕获更广泛的潜在答案)、最大边际相关性(MMR)(在检索的文档中平衡相关性和多样性)、Cohere重排序器和LLM重排序器(对检索到的文档进行重排序,以优先选择最相关和上下文适当的信息), 根据测试,HyDE和LLM重排序器显著提高了检索精度,但MMR和Cohere重排序器并未显示出比基线Naive RAG系统更明显的优势,多查询方法的表现不如预期,句子窗口检索在检索精度方面表现最佳,尽管其在答案相似性方面的表现不稳定,文档摘要索引被证实是一种有效的检索方法,但需要进一步的改进才能超越传统的向量数据库。
这个测试存在的一些问题: 1、首先是测试数据的设计全是论文,真实场景哪有天天看论文的; 2、其次,如果RAG用在对话问答场景,以大模型(GPT-4、智谱等)的响应速度是无法接受HyDE以及LLM 重排序器的,一般首Token容忍度应该在3-5秒内,多访问一次LLM早超时了。
Understanding the planning of LLM agents: A survey:这篇论文对LLM-Agent规划进行系统性的分类和分析,将现有的工作分为五个主要类别:任务分解、多规划选择、外部规划器辅助规划、反思与改进以及记忆增强规划。这些类别涵盖了不同的研究方向和方法,旨在从不同角度提升LLMs的规划能力。
五个主要类别包括:
- 任务分解:将复杂任务分解为多个子任务,然后依次为每个子任务制定规划。
- 多规划选择:生成多个备选规划,并通过搜索算法选择最优规划。
- 外部规划器辅助规划:结合LLM和外部规划器,利用外部规划器的效率和可行性来提升规划过程。
- 反思与改进:通过反思失败的经历来改进规划,鼓励LLM对失败进行反思并据此调整规划。
- 记忆增强规划:使用额外的记忆模块来存储有价值的信息,如常识知识、过去经验等,并在规划时检索这些信息作为辅助信号。
有什么限制条件?
计算成本:任务分解和多规划选择等方法可能会增加计算成本和时间。
上下文长度限制:对于高度复杂的任务,分解成数十个子任务可能会超出LLM的上下文长度限制,导致规划轨迹的遗忘。
幻觉问题:LLM在规划过程中可能会产生幻觉,导致不切实际的规划。
规划可行性:由于LLM基于统计学习,可能难以遵守复杂约束,导致生成的规划缺乏可行性。
多模态反馈处理:LLM主要设计用于处理文本输入,而现实世界中的环境反馈通常是多模态的,这对于LLM来说是一个挑战。
评估方法的局限性:现有的评估方法大多依赖于任务的最终完成状态,缺乏对中间步骤的细粒度评估。
结论:尽管LLMs在规划能力上取得了显著进展,但仍面临一些挑战,如幻觉问题、生成规划的可行性、规划效率以及多模态环境反馈的处理。此外,现有的评估方法大多缺乏细粒度的评估,且环境反馈通常过于简化。未来的研究方向可能包括利用LLMs设计更真实的评估环境,以及进一步探索如何将LLMs与符号规划模型相结合。
工程
OpenAI一年前声称要投入 20 % 的算力来实现超级对齐,本周宣布了官方资助的研究领域:从弱到强的泛化(Weak-to-strong generalization)、可扩展监督(Scalable oversight)、自上而下的可解释性(Top-down interpretability)、机制可解释性(Mechanistic interpretability)、思想链忠诚度(Chain-of-thought faithfulness)、对抗鲁棒性(Adversarial robustness)、数据归属(Data attribution)、评估/预测(Evals/prediction)。
我们一直谈AI 安全,AI安全到底是指什么,我想大家应该可以从这些领域关键字获得一些具体的认识,如果对其中某个点感兴趣,可以持续跟踪对应的研究团队进展。大语言模型在安全这块目前还是粗放式发展,优先级不高,但我觉得越是深入研究大语言模型的实用性时,越应该关注其长期影响和可持续性,重视人类的反馈(RLHF)、模型的可解释性,确保技术的发展符合人的价值观和伦理标准。
AI 编程:Devin强势发布以后, Devika、OpenDevin、SWE-Agent等开源竞品陆续推出,每个都收获了巨大热度,可笑的是Devin演示视频被油管博主曝出演示视频造假,社区有人戏称Devin的唯一贡献就是催生了一堆开源竞品,接下来的剧本是开源项目开始稳扎稳打,逐渐成熟,最后推出SaaS版本和自托管版本,一步步产品化起来,想做国内对标产品的朋友,可以去翻翻源码,时间有限的情况下看SWE-Agent,结合了前两者的优点。
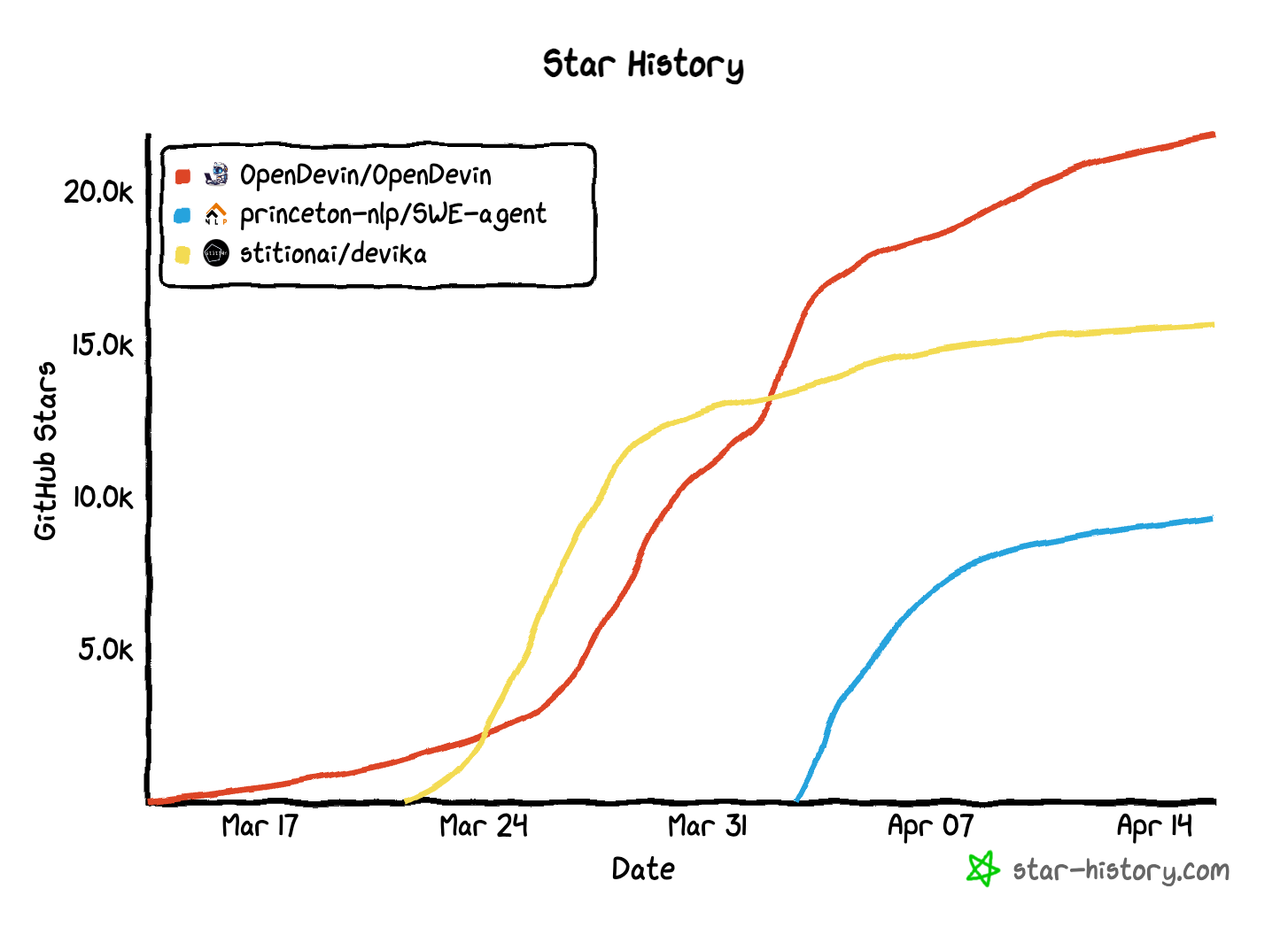
为什么编程领域的AI发展较快一些?我觉得大概有下面几方面原因:
- 明确的问题定义:编程问题通常具有明确的定义和目标,例如解决特定的算法问题或修复代码中的错误。这种明确性使得AI系统更容易理解所需完成的任务,并能够通过学习和实践来提高性能。
- 结构化数据:编程涉及的数据通常是结构化的,例如代码库、文档和错误日志。AI系统能够有效地处理和分析这些数据,从而在代码生成、缺陷检测和优化等方面取得进展。
- 可度量的结果:编程任务的成果可以通过各种指标进行量化,如代码质量、执行效率、错误率等。这为AI提供了明确的反馈信号,有助于训练和优化模型。
- 自动化潜力:编程自动化具有更显著的商业价值,企业和研究机构愿意投入大量资源来开发。
产品
- Devin演示视频造假:1. Devin 声称能够解决任意Upwork 任务,但在视频演示中,解决的问题与客户规定的要求不符;2. Devin 修复 GitHub 仓库中的错误,但它所编辑的文件实际上并不存在于该仓库中,而且它修复的一些错误是无意义的,属于人永远不会犯的类型;3. 视频中说Devin大约30 分钟内完成所请求的任务,但视频中聊天界面的时间戳任务持续了多个小时;4. 执行无意义的 shell 命令。#toC #AI编程
前面已经讲了这个事件,这里再具体谈一下,这种事其实蛮恶劣的:
- 自媒体们是一鱼两吃,赚两波流量,从一个极端到另一个极端,让非从业者只会加深对AI的误解
- 前有谷歌,现有 Devin,靠编造假的技术演示内容博出圈,这种方式竞争,只会加速AI泡沫化
- 开了坏头,在露馅之前,带着这波流量,可以高额融资,后面的初创公司有样学样,给投资人吹泡泡,这种事多了,那真正做事的人拿投资难度更大了
当然视频造假的点主要是过度夸张和实际能力不符的部分,但是其中一些Agent能力也是可圈可点的,包括长期推理与规划、使用开发者工具、主动协作、学习新技术、端到端应用构建和部署、自主查找和修复代码库中的Bug、训练和微调AI模型、处理开源仓库的问题、对成熟生产仓库做出贡献等,Devin 在SWE-bench基准测试中正确解决了13.86%的问题,这一比例远远超过了之前的技术水平,也超过了Claude 2、Llama、GPT-4等一众大模型。
SWE-bench基准测试: 一个包含 2294 个问题和从 GitHub 上流行的开源 Python 存储库中抓取请求的数据集,其目标是测试系统编写真实代码的能力。每个 SWE-bench 实例都包含一个 GitHub 问题和解决该问题的拉取请求,拉取请求必须包含一个单元测试,该测试在代码更改之前失败并在代码更改之后通过。diff 分为两部分,patch 和 test_patch,分别包含代码更改和测试更改,然后,要求正在评估的系统根据 GitHub 问题描述和存储库(问题发生时)生成差异,如果在修补编辑后所有单元测试都通过,则该示例被认为是成功的。

- AI在投标书行业的应用:这个是我在实际聊天中收获的,根据评标规则(提示词)让AI生成长文本(几百页标书),这是一个非常适合大模型改造的场景,价值高且需求很大,国外的 AutogenAI 就是聚集这个点,拿到2230万美元融资。国内的文兜智写家的产品完成度还不错,依靠背后强大的文档库,其他家的水平确实都一般,但是标书撰写有一个特殊的点,就是不同的行业差别巨大,所以聚焦一个细分行业肯定活得很滋润,而且招投标是商业世界永远都存在的需求场景。(2023年中国招投标行业研究报告)
- 一个顶级 AI 产品经理的自我修养 | 对谈光年之外产品负责人 Hidecloud:本文介绍了AI产品负责人张涛的经历和在AI领域的思考。他强调了产品经理应该关注技术与产品的结合,利用开源社区的能力来满足需求。讨论了AI产品经理面临的挑战以及可能的解决方案,包括技术进展与产品需求的连接、团队协作中的问题、产品形态的演变以及市场教育的影响。此外,还讨论了AI生成图标的交互体验和消费场景,以及AI产品在普通用户中的推广和运营仍然是一个挑战。最后总结了AI行业近十年来的变化和进步,以及对未来的展望。整体来看,AI行业在不断发展和进步,给参与者带来了更多的信心和兴奋感。
市场
- 红杉美国每年更新的AI50初创公司榜单更新了,入选公司和23年相比变化不大,但是调整了分类。

2024年的AI 50名单展示了Gen AI如何开始改变企业生产力。去年,生成式人工智能从AI 50名单的边缘转移到了核心地位。今年,它成为了焦点,因为我们看到了针对企业客户和消费者的主要AI生产力增益的起步。尽管2023年美国AI风险投资的大部分资金流向了基础设施领域——其中60%流向最大的大型语言模型(LLM)提供商——应用公司仍然在AI 50名单中占据主导地位。
与此同时,我们开始看到注入AI的公司将会是什么样子。如今,许多公司正在将AI融入其流程中,以加速关键绩效指标。我们看到大公司通过将AI整合到其产品中受益。工作流自动化平台ServiceNow通过其AI驱动的Now Assist实现了近20%的案例避免率。Palo Alto Networks通过AI降低了处理费用。Hubspot通过AI扩展了客户支持。瑞典金融科技公司Klarna最近宣布通过将AI融入其客户支持中实现了超过4000万美元的年度节省。成千上万家公司现在正在将AI整合到其工作流程中,以实现增长和降低成本。AI 50名单上的公司正在实现这些快速改进。
未来,我们预计将看到围绕AI的用户体验(UX)和用户界面(UI)的能力重新构想。复制现有功能并使其更好更便宜的时代将被全新的用户界面所取代,为用户提供有价值的新体验。
今年有哪些新趋势?
今年AI 50名单中的重大变化突显了生成式AI如何增加企业和行业生产力。企业一般生产力类别从去年的四家公司增加到了八家,因为它们扩展了产品线以满足客户不断增长的需求。之前在我们的企业营销类别中的Writer公司,扩展了他们的产品线,适用于所有公司部门。新上榜的Notion公司在其生产力平台中整合了AI助手,并增加了像日历等新功能。五款生产力应用程序,包括OpenAI的ChatGPT、Anthropic的Claude、DeepL、Notion和Tome,现在面向消费者、专业消费者和企业用户。图像编辑器Photoroom、视频生成应用Pika和游戏构建工具Rosebud显示出消费者和专业消费者之间的界限正在变得模糊。总的来说,该类别中的公司数量也增加了一倍,从三家增至六家。
今年,行业垂直类别减少了,但新的工业部门出现了。机器人公司Figure、工业维护公司Tractian和自动驾驶公司Waabi开始展示AI软件与硬件的整合将如何改变物理世界的工作。
2023年在基础设施方面是强劲的一年,包括一些强大的新参与者,例如Mistral,一个基础模型的主要竞争者。在云数据平台类别中,Pinecone和Weaviate展示了向量数据库的重要性。与此同时,通过去年收购MosaicML,Databricks也加入了Anyscale、Baseten、Replicate和Together等推理提供商类别。LangChain已经建立了自己的类别,作为一个通用的应用程序开发框架,用于与LLMs合作。
未来的公司
过去的技术创新浪潮——网络、互联网和移动——在很大程度上是通信革命。人工智能则承诺带来不同的东西——一场生产力革命,更类似于个人电脑那样塑造商业和工业的未来。随着更多的AI被开发出来,它们将开始共同运作作为一个AI网络。在过去的一年里,我们看到生成式AI不仅限于简单的文本或代码生成,还扩展到了主动互动。正如个人电脑和智能手机的崛起推动了对于传输数据的互联网带宽的需求,AI代理的演进将推动对新基础设施的需求,以支持越来越强大的计算和交流。
我们正在进入一个世界,在这个世界中,正如英伟达首席执行官黄仁勋所说,“每个像素都将被生成”。在这个生成式的未来中,公司构建本身可能会成为AI代理的工作;并且有一天整个公司可能会像神经网络一样运作。
现在应用景观中我们看到的是下一代公司将使用的工具的第一次迭代。我们可能预计这些公司规模会更小,但公司构建变得更加便捷意味着会有更多这样的公司出现。公司组建将变得更快速和更灵活,拥有新的所有权和管理结构。未来,可能会有由单个AI工程师运营的大型公司。
未来大多数公司不会是一人公司,但它们将有与今天公司不同的需求和痛点。它们将需要能够解决知识管理和内容生成、信任、安全和身份验证等挑战的企业产品。这些公司运行的软件量将扩大和改变,代码生成和软件代理将实现更多定制和快速迭代。
要赢得未来企业的心和头脑,创始人们需要回答一些关键问题。这些公司将制造什么样的产品?他们将需要什么样的基础设施和应用程序?员工将如何变化?分配和价值捕获模式将如何改变?他们在总地址市场中所占份额由人类还是自主AI代理组成?
接下来
像AI革命这样的生产力革命会降低成本。本世纪的技术进步已经从根本上降低了硬件成本,但由人类提供的服务成本,从医疗保健到教育,却飙升了。人工智能有潜力在这些关键领域降低成本,使其更易获得和负担得起。这些变化需要负责任地进行,以减少人员流失并推动创造就业机会。人工智能将使我们能够用更少的资源做更多的事情,但我们将需要政府和私人部门共同努力,对所有人进行再培训和赋权。人工智能定位于改变我们社会中一些最关键领域的成本结构并提高生产力。它有潜力带来更好的教育、更健康的人口以及更多具有生产力的人,通过将单调的工作抽象化,使我们能够将注意力集中在更重要的问题上,并为未来提供更好的工具。它可以释放出更多的人来解决更多的问题,创造一个更好的社会。

观点
你支持AI“复活”逝者吗?#AI合规 #伦理
我的态度是坚定抵制,逝者无同意权,AI“复活”逝者就是霸凌一个无法反抗的人,控制死者做些违背意愿的事和发布一些服务于“活人”利益的言论。
168.AI复活明星:感动背后,是伦理与侵权难题 :在这期播客中,社会学教授沈奕斐老师和AI领域的法律专家商老师,一起讨论了AI复活背后的知识产权与伦理的问题。
EP281-清明特辑:AI时代的死后复活与数字遗产,逝者有没有选择被遗忘的权利:前段时间,音乐人包小柏用 AI 重现女儿的声音和形象,商汤科技创始人汤晓鸥被公司以数字人的形式现身年会,“AI 复活”走入现实。然而“AI 复活”展现出来的科技人文关怀,没几天就变味了。多位已故明星李玟、乔任梁、高以翔被“复活”,登上微博热搜,但这些网友擅自的复活遭到了明星亲属的极力反对。
Vol.1:你支持AI“复活”逝者吗
