Vol.8:如何针对 GPT-4o 语音模式进行越狱攻击?
本期分享的内容包括:如何利用这些多模态模型实现企业工作流程的端到端自动化;英伟达研究团队通过严谨的测试发现大多数商业模型的上下文长度虚标严重,甚至达到 32K 上下文长度的都不多;如何针对 GPT-4o 语音模式的进行越狱攻击;产品方面剖析了 Meta、Slack、Spotify 等 20+顶级科技公司如何将 AI 融入其产品中;a16z 盘点了 AIGC 如何推动营销和销售领域的发展,包括产品及项目调研;OpenAI 分享他们在 RAG 技术的最佳实践;开源社区最流行的 RAG 构建框架 LlamaIndex 团队对 RAG 技术现状总结;以及王铁震老师对中文 LLM 开源生态的观察分享,最后在观点部分分享了人工智能时代如何助推全球新产业革命,以及为什么在大模型开源社区国内贡献度和影响力极不匹配。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
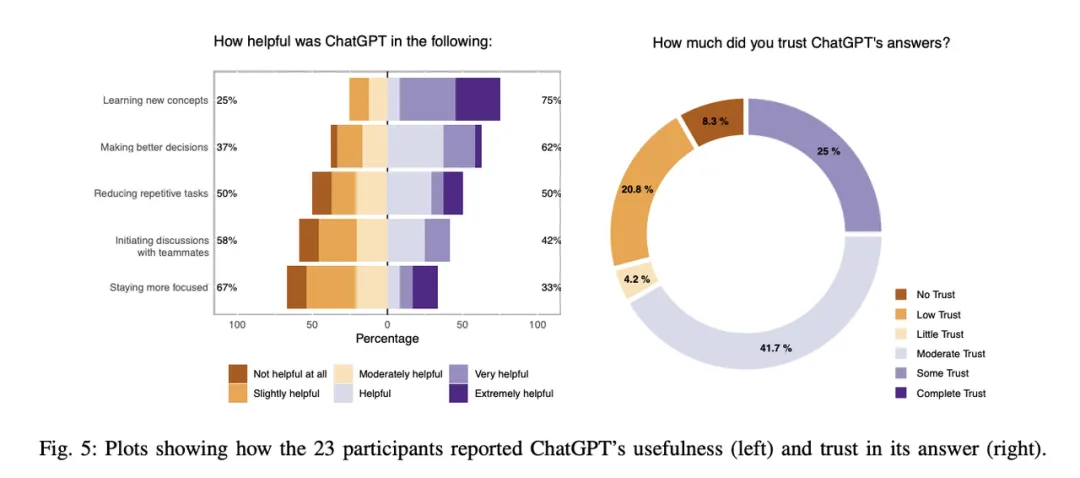
超越代码生成:ChatGPT 在软件工程实践中的观察性研究:来自瑞典哥德堡查尔姆斯理工大学和瑞典 RISE 研究机构的研究人员对 10 家公司的 24 名软件工程师展开了定性分析。这些工程师在日常工作中使用 ChatGPT 超过一周。研究发现,这些从业者更多地使用 ChatGPT 寻求任务解决方法或对主题进行抽象理解的指导,而非期望 ChatGPT 生成可用的软件工件(如代码)。该研究提出了一个理论框架,解释了交互目的、内部因素(如用户个性)和外部因素(如公司政策)如何共同塑造用户体验(包括感知有用性和信任度)。研究指出,即使是前沿模型也无法解决企业应用中的某些问题,特别是上下文理解方面。为了提升用户体验,聊天界面需能够自动提供上下文信息给模型。一种方法是利用检索增强生成(RAG),自动将上下文信息添加到用户提示中。隐私和数据共享限制也是一个需要解决的问题。使用开源模型 Llama 3 可以确保数据永远不会离开用户组织。此外,用户在提示模型时的方式会对模型性能造成重大影响,减少提示工程的障碍可以改善用户体验。一些技术,如 Anthropic 公司的提示生成器和 DeepMind 的自动优化提示技术 OPRO,可以帮助解决这一挑战。最后,研究提到使用 ChatGPT 可能导致注意力分散。通过将模型融入团队合作,可以在一定程度上缓解这一问题。
如何利用这些多模态模型实现企业工作流程的端到端自动化:自动化工作流程虽然已有数十年研究实践,但实现全自动化仍有挑战。机器人流程自动化(RPA)是目前先进解决方案,通过硬编码规则执行工作流程,但受高成本、执行效果不稳定和维护需求繁重等限制。本文介绍了 ECLAIR 系统,该系统利用多模态基础模型学习人类工作流程专业知识,提高了识别工作流程步骤的准确率,并提高了完成任务的成功率。ECLAIR 还通过自我监控和纠错减少了对人工监督的需求,在验证过程中取得了很高的精确度和召回率。
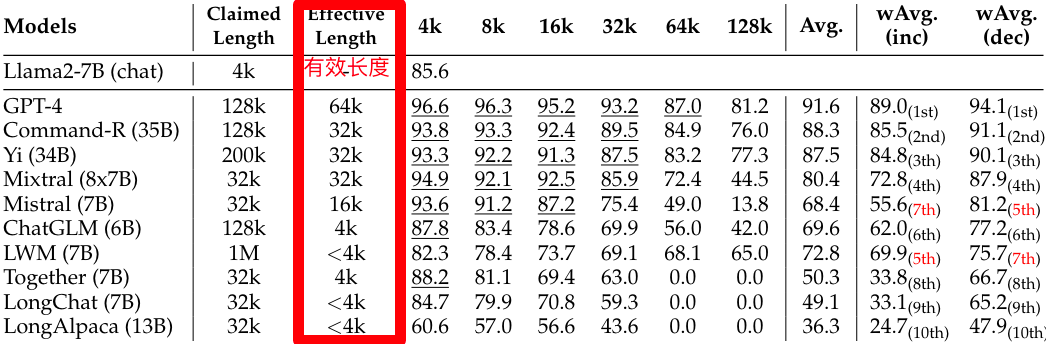
RULER: What’s the Real Context Size of Your Long-Context Language Models?:不知道大家在平常使用中是否会明显感知到大模型厂商声称的上下文长度和实际体验到的并不匹配,英伟达这篇论文从更科学的角度对大模型的上下文长度进行测试,发现大多数模型(不论开源闭源,国内外模型)上下文长度虚标严重,32K 性能合格的都不多。
Voice Jailbreak Attacks Against GPT-4o:本研究首次系统评估了针对 GPT-4o 语音模式的越狱攻击,发现 GPT-4o 对直接转换的禁止问题和文本越狱提示具有较强的抵抗力。这得益于其内部安全机制及语音模式下适应文本提示的难度,受 GPT-4o 人类化行为的启发,论文提出了 VoiceJailbreak,一种通过虚构故事(设定、角色和情节)说服 GPT-4o 的新型语音越狱攻击,该攻击能生成简单而有效的越狱提示,将六种禁止场景下的平均攻击成功率从 0.033 大幅提升至 0.778。作者团队还还通过实验探讨了交互步骤、虚构写作要素及语言差异对 VoiceJailbreak 的影响,并运用高级虚构写作技巧提升攻击效果。
工程
[使用大语言模型 (LLMs) 构建产品一年后的经验总结](https://www.oreilly.com/radar/what-we-learned-from-a-year-of-building-with-llms-part-i/ “使用大语言模型 (LLMs “使用大语言模型 (LLMs) 构建产品一年后的经验总结”) 构建产品一年后的经验总结”):在使用大语言模型(LLMs)构建产品方面,LLMs 的表现已经达到可以应用于现实世界的水平,推动预计到 2025 年 AI 投资达到 2000 亿美元。构建 AI 产品的门槛降低,但要创建高质量产品仍充满挑战。作者总结了一些关键经验和方法,对于基于 LLMs 的产品开发至关重要。这些经验包括提示设计、检索增强生成等方面的最佳实践和常见陷阱。这项工作分为战术、运作和战略三个部分,第一部分重点探讨使用 LLM 的战术细节。可以在此处阅读中文译文 [使用大语言模型 (LLMs) 构建产品一年后的经验总结 (第一部分) [译]](https://baoyu.io/translations/llm/what-we-learned-from-a-year-of-building-with-llms-part-1 “使用大语言模型 (LLMs “使用大语言模型 (LLMs) 构建产品一年后的经验总结 (第一部分) [译]”) 构建产品一年后的经验总结 (第一部分) [译]”)
构建 AI SaaS 应该用 RAG 还是微调?:如何将上下文数据合并到 LLM 中是一个关键问题。有两种主要方法:RAG 和微调。文章详细比较了这两种方法,以确定哪种方法最适合 AI SaaS 产品。
OpenAI 分享他们在 RAG 技术的最佳实践:OpenAI 分享了技术团队的 RAG 最佳实践,当客户有大量文档(例如 10 万份),希望模型仅基于这些文档进行知识检索,下面是一个大概的方案分级过程:
直接嵌入 PDF 和 docx 文件,初始准确率为 45%。
经过 20 次调优迭代,解决了一些小 Bug,准确率提高到 65%。
通过基于规则的优化,例如首先识别问题所属领域(逐步考虑),然后给出答案,效果提高至 85%。
发现数据中包含一些结构化数据(例如表格),定制提取方法后,准确率提高至 98%。
Beyond RAG: Building Advanced Context-Augmented LLM Applications:开源社区最流行的 RAG 构建框架 LlamaIndex 团队对 RAG 技术的总结,讨论如何构建一个一般的上下文增强研究助手,并强调了构建研究类 Agent 的优势,包括多跳问答、查询理解和任务规划、与各种外部工具交互的界面、反思以纠正行为、以及用于个性化的记忆。
产品
深入探讨 20+顶级科技公司如何将 AI 融入其产品中:本系列文章分析了海外科技公司将 AI 集成到产品中的新方法和功能,包括嵌入式助手、新的独立产品、用户体验增强器、生产力助推器和 ML 智能/数据分析五种类别。这些功能旨在提升产品价值、用户体验和生产力,并帮助 AI 团队设计产品时获得参考。

基于 AI 的软件如何推动营销和销售:营销因其依赖文本、图像、视频等媒体类型而特别适合采用生产式 AI,这也是许多首个 B2B GenAI 用例是用于营销的原因之一。采用 GenAI 在营销中的演进分为三个阶段:开发营销副驾驶员、建立营销代理人以及转变为自动化营销团队。目前我们处在第一个阶段,营销人员可以利用 GenAI 作为其营销副驾驶员,这有助于开发与传播品牌相关资产。下一个阶段是建立营销代理人,自动化营销工作,实现个性化营销活动,提高效果。最终目标是 AI 代理人承担 CMO 职责,操作作为完整营销计划的自动化营销团队,这将大幅提高市场团队的效能,并可能引领市场技术领域的新机遇。
GLM-4-9B 开源:GLM-4-9B 与 GLM-3-6B 模型结构一致,主要改变为模型层数、词表大小、更长的上下文。
- 词表由 65024 增加到 151552;
- 模型层数由 28 增加到 40;
- 上下文长度支持从 32K、128K 到 128K、1M
开源 License 说明:学术研究免费,商业用途需要登记,且必须遵守相关条款和条件,Github 地址:https://github.com/THUDM/GLM-4
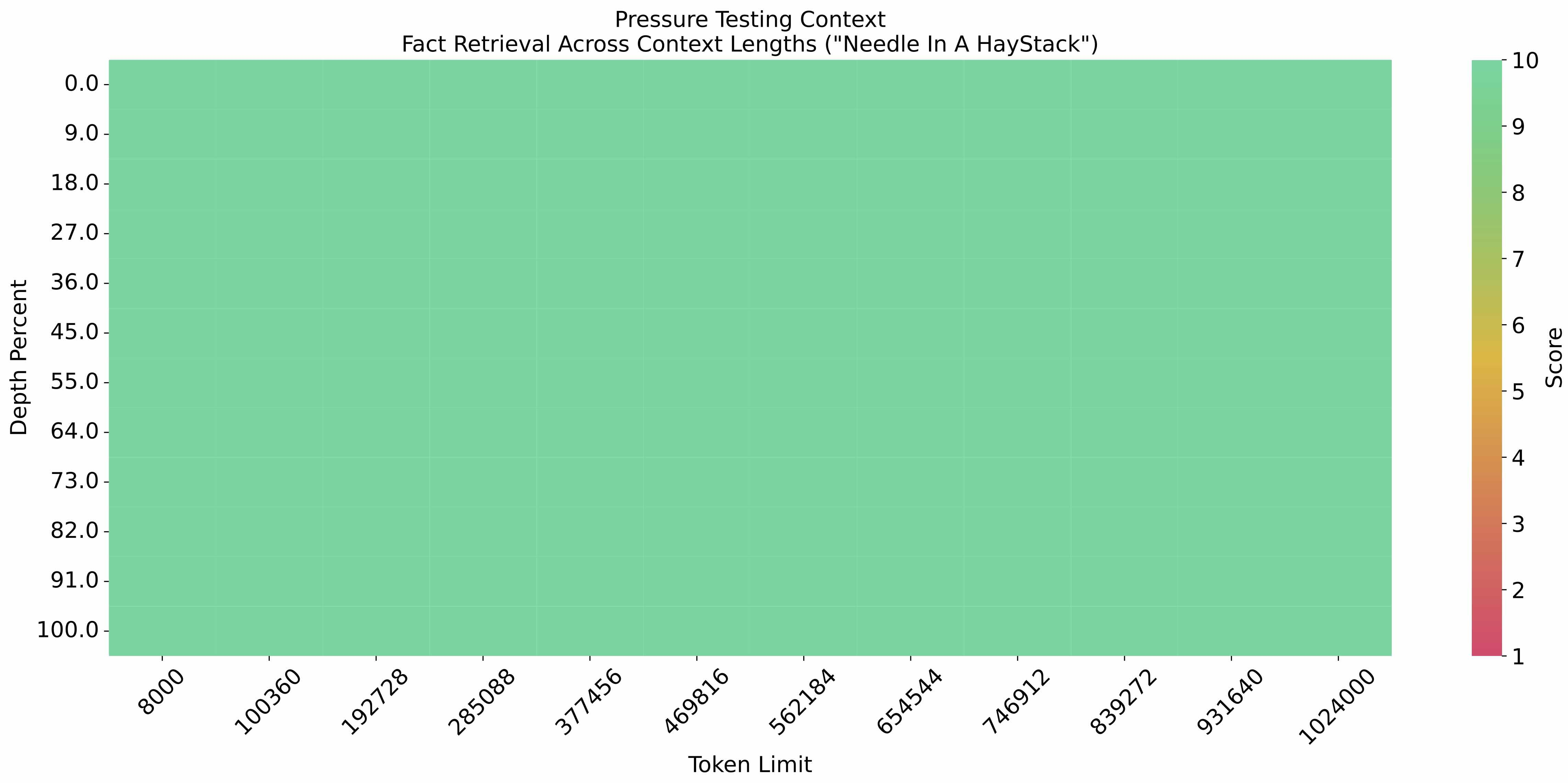
能力方面,1M 上下文长度方面,在大海捞针测试中全绿
工具调用 Function Call 能力也属于 gpt-4-turbo 级别
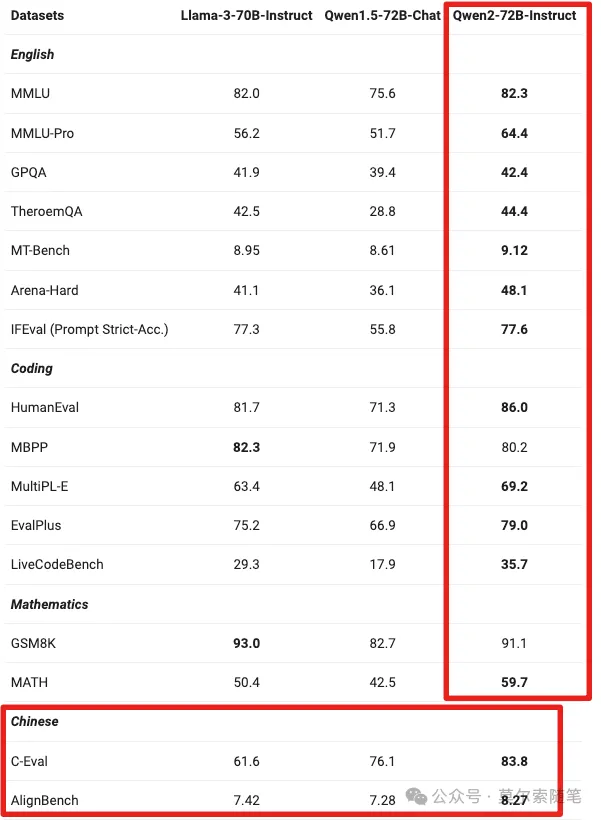
Model Overall Acc. AST Summary Exec Summary Relevance Llama-3-8B-Instruct 58.88 59.25 70.01 45.83 gpt-4-turbo-2024-04-09 81.24 82.14 78.61 88.75 ChatGLM3-6B 57.88 62.18 69.78 5.42 GLM-4-9B-Chat 81.00 80.26 84.40 87.92 Qwen2 开源:阿里 Qwen2 模型开源,本次开源的 Qwen2 模型包括 5 个尺寸,分别是 0.5B、1.5B、7B、72B、57B,其中 57B 的属于 MoE 模型(激活参数 14B),其余为 Dense 模型。Qwen2 和 Qwen1.5 的模型结构基本一致,主要是模型预训练数据有所增加(大约在 7T 以上),Qwen2-0.5B、Qwen2-1.5B 模型支持最大上下文长度为 32K;Qwen2-57B-A14B MoE 模型支持最大上下文为 64K;Qwen2-7B、Qwen2-72B 模型支持最大上下文为 128K,代码和数学能力显著提升。在 Qwen1.5 系列中,只有 32B 和 110B 的模型使用了 GQA,Qwen2 所有尺寸的模型都使用了 GQA,GQA 可以显著加速推理,降低显存占用。Qwen2-72B-Instruct 在多项指标超过 Llama-3-70B-Instruct,特别是中文领域,大幅领先。更多详细内容,请前往官网博客查看 https://qwenlm.github.io/zh/blog/qwen2/。
Chrome 内置 Gemini Nano:谷歌浏览器从 Chrome 126 开始, Gemini Nano 端侧小模型将内置到浏览器中,使用本地模型的好处也无需多言:1. 本地处理敏感数据,提高隐私保护;2. 提供流畅的用户体验,可实现近乎即时结果;3. 设备端 AI 提供更高的 AI 访问权限,用户设备可承担一部分负载;4. 可以离线使用 AI 功能,无需互联网连接。当前只是开发者版本可用,希望体验的朋友可以参考这篇文章进行配置手把手教你使用 Chrome 内置 Gemini Nano。
市场
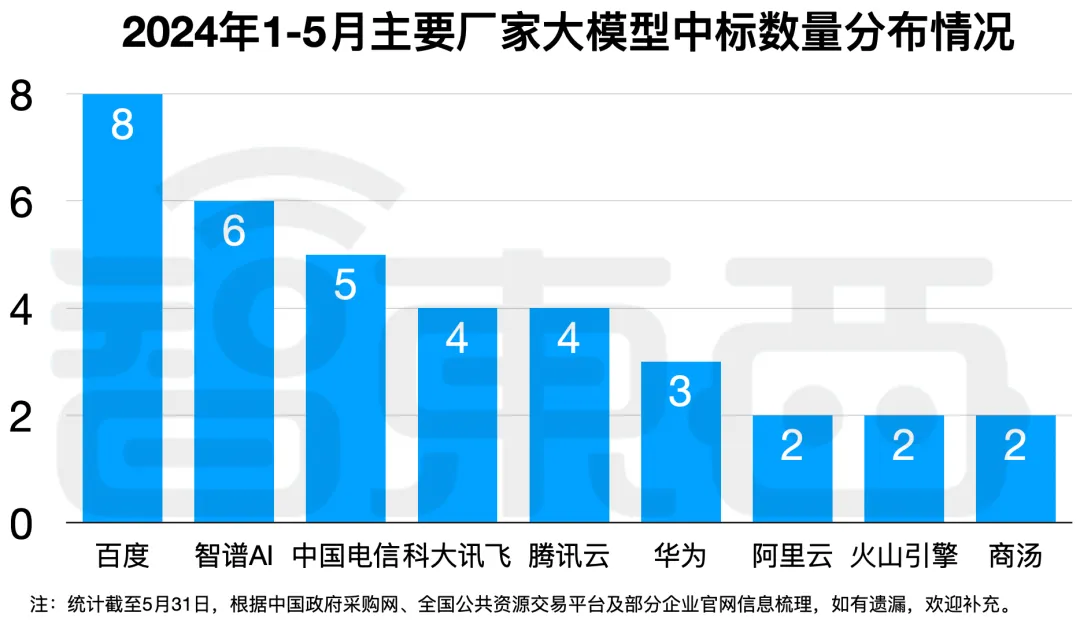
拆解 50 个大模型大单:0 元中标,头破血流!华为成隐形赢家:百模大战中,大模型企业开始盈利,50 个大模型大单中,百度获得 8 个,金额前十的大单有 3 个,成为最大赢家。智谱 AI、中国电信分别获得 6 个、5 个大单,位居第二、第三。
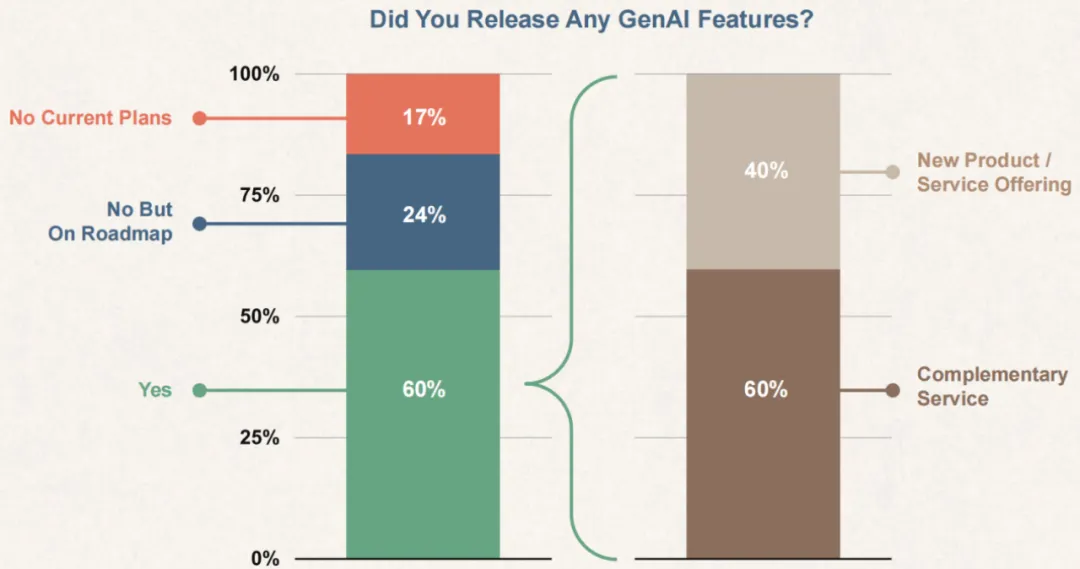
从美国 B2B 软件企业的统计视角看 AI 的真实发展情况:Emergence Capital 是美国知名的 SaaS 风险投资基金,他们 2024 年 4 月最新发布的《Beyond Benchmarks》报告收集了 600 多家 B2B SaaS 企业的数据,在此基础上得出的当下 AI 在美国软件类企业真实的发展情况具有比较强的参考意义。
观点
人工智能时代如何助推全球新产业革命:6 月 2 日,英伟达联合创始人兼首席执行官黄仁勋在 Computex 2024(2024 台北国际电脑展)上发表主题演讲,分享了人工智能时代如何助推全球新产业革命,本文是是腾讯科技整理的两小时演讲全文实录。
中文 LLM 开原生态蓬勃发展:近距离观察:来自 Hugging Face 的工程师王铁震老师的文章,总结了过去一年来,国内开源社区取得的重要进展,发布了许多新模型,一些模型不仅包括中文和英文,还支持多种语言,这些模型在性能方面表现出色,中国模型在一些排行榜上表现优异,最后总结了国内研究人员对整个开源社区的贡献,同时,还回答了一些有关开源模型、不同地区模型之间的差异以及政府在该领域所扮演的角色等问题。想起斯坦福 Llama3-V 套壳面清华系和面壁智能团队联合开发的 MiniCPM-Llama3-V 2.5 的事情和美国拟限制开源 AI 大模型出口的风波,大模型开源社区的国内贡献度和影响力极不匹配,看好 GLM 和 Qwen、Yi 系列等继续扩大自己的开源影响力,延伸阅读材料。
Vol.8:如何针对 GPT-4o 语音模式进行越狱攻击?
