Vol.9:构建 AI 产品过程的踩坑经验总结
⼤家好,Weekly Gradient 第 9 期内容已送达!本期内容信息量较大,毕竟 2024 年即将过半,包括一份 OpenAI、微软、 马里兰大学和learnprompting社区联合发布的提示词技术调研报告,一篇总结大语言模型在信息抽取上的各方面应用的综述,看看一线工程师从过去一年构建基于大模型的产品中总结到哪些经验,大模型开源生态中国力量的现状分析, 过去一年的硅谷顶级 AI 初创公司和产品盘点,从字节的 Dreamina、腾讯的 VideoCrafter2 到右脑科技的 Vega AI、爱诗科技的 PixVerse,还有最近大热的快手可灵和 Luma 的 Dream Machine,看看文生视频/图生视频模型的发展现状。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
The Prompt Report: A Systematic Survey of Prompting Techniques:OpenAI、微软、 马里兰大学和learnprompting社区联合发布的提示词调研报告,报告调研了 1500 多篇和提示词研究相关的论文,分析了多种 Prompt Engineering 技术,涵盖多语言、多模态、Agent、模型评估、安全、对齐等主题。

下面是不同提示词技术的论文引用数排名前:
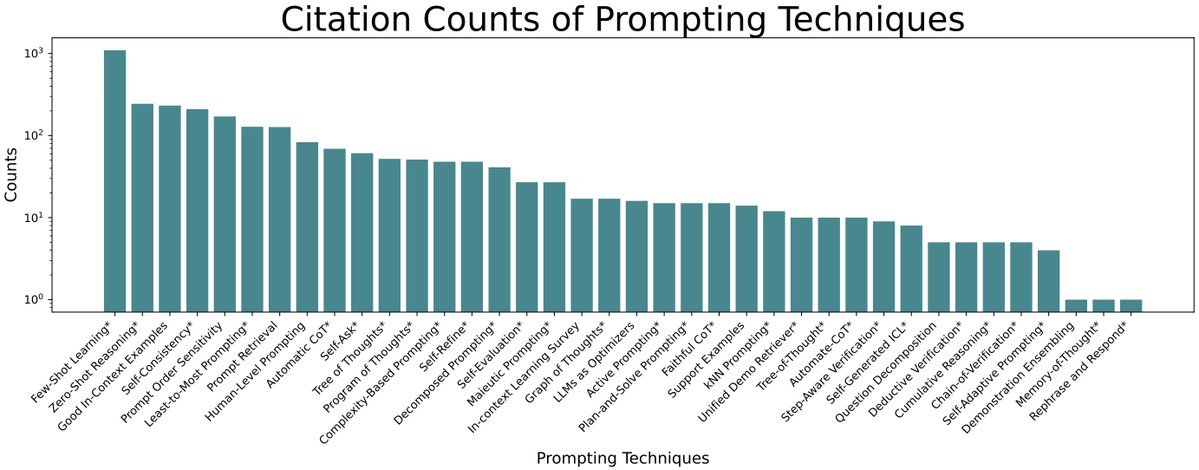
评估了专家级 Prompt Engineering 为实现最佳结果而采取的不同优化步骤。
完整报告地址:https://trigaten.github.io/Prompt_Survey_Site/
Large Language Models for Generative Information Extraction: A Survey:又是一篇综述性质的论文,总结了大语言模型在信息抽取上的各方面应用。信息抽取(Information Extraction, IE)是自然语言处理领域的核心,也是构建知识图谱、知识推理和知识问答等众多下游任务的基础。信息抽取一般包括:命名实体识别(Named Entity Recognition, NER)、关系抽取(Relation Extraction,RE )和事件抽取(Event Extraction)。大语言模型(LLMs)在文本理解和生成领域表现突出,展示出跨领域的泛化能力。因此,许多研究都开始利用 LLMs 的潜力,为 IE 任务提供基于生成范式的创新解决方案。这项研究旨在对 LLMs 在 IE 领域的应用进行深入的系统回顾。论文首先根据 IE 子任务和学习范式对相关工作进行分类概述,然后通过实证分析了前沿技术,揭示了 LLMs 与 IE 任务结合的新趋势。通过全面的回顾,作者指出了技术方面的见解和未来研究的方向,并维护一个持续更新相关资料的公共资源库,地址为:https://github.com/quqxui/Awesome-LLM4IE-Papers
Financial Statement Analysis with Large Language Models:本研究探讨了大语言模型(LLM)在财务报表分析任务中的表现,并与专业人类分析师进行了比较。研究发现,在没有任何叙述性或行业信息的情况下,GPT-4 在预测未来收益变化方面的表现优于人类金融分析师,并且在分析师可能遇到困难的情况下展现出了相对优势。此外,LLM 的预测准确性与传统机器学习模型相当,表明了 LLM 在财务分析领域的潜力。
Enhancing Anomaly Detection in Financial Markets with an LLM-based Multi-Agent Framework:该论文提出了一个基于语言模型的多 Agent 框架,旨在提升金融市场数据中异常检测的能力,解决手动验证系统生成异常警报的长期挑战。该框架由一个协作网络构成,每个 Agent 专注于不同的功能,包括数据转换、依据专家分析的网络研究、利用机构知识或交叉核查,以及报告整合和管理。通过协调这些 Agent 共同推进,该框架提供了一种全面且自动化的方法来验证和阐释财务数据异常。
工程
Challenges in red teaming AI systems:Anthropic 安全团队分享了他们在测试 AI 系统时所采用的红队方法,并希望这些经验对其他公司红队测试他们的 AI 系统、对红队工作机制有兴趣的决策者以及希望对抗 AI 技术的组织有所帮助。文章探讨了红队测试的定义、优缺点以及缺乏标准化实践的问题,并呼吁 AI 领域建立系统性的红队测试标准和实践。各种红队测试方法涵盖了特定领域的专家合作、政策漏洞测试、国家安全风险测试、多语言多元文化测试等多个领域。文章还讨论了如何从定性的红队测试过渡到定量的评估方法,并提出了一些政策建议来支持红队测试的进一步采纳和标准化。
Hugging Face 中文社区:在上一期还谈到国内大模型影响力和贡献度不匹配问题,本周 Hugging Face 团队就宣布专门开设一个中文大语言模型社区,这是一个很好的窗口,Hugging Face 中文社区专门分享来自中文社区的热门模型、数据集、论文、工具及相关项目,以帮助国内外社区开发者发现并利用这些宝贵资源。
DSPy:Declarative Self-improving Language Programs, pythonically(声明式自我改进语言程序),DSPy 是一款 prompt 自动优化相关的工具和框架,在 LLM 应用的开发流程中,通常包括明确需求、准备测试用例、编写 prompt、观察结果并做误差分析、修改 prompt 并重复实验等步骤。随着 pipeline 复杂度增加,可能会面临维护工作量和复杂度上升的挑战,需要拆分子任务、尝试新技术、优化 Pipeline 逻辑、切换模型版本等。DSPy 提出的解决思路是基于训练数据来自动优化整个 pipeline,类似机器学习中的参数优化。这篇文章对这个框架进行了详细分析,还在用手工作坊的方式管理 Prompt 的朋友可以用起来。
从过去一年构建大语言模型中学到的东西(二):本文总结了在产品开发中有效利用大语言模型的关键做法:
定期评估模型性能变化,做好测试和应对准备。
选择满足需求的最小模型规模,通过优化 prompt 等方式提升性能。
将产品设计和用户体验融入到大语言模型应用的开发流程中。
通过提示工程培养全员的 AI 使用能力,鼓励每个人尝试和实验。
在产品规划时留出充足时间进行实验和迭代优化,而非急于向生产环境推进。
实现 AI 驱动产品需要跨职能团队协作,不应过于依赖”AI 工程师”。
重视提升全体员工对 AI 技术的了解和应用能力,让每个人都成为创新的参与者。
产品
Cloudflare 正式发布 AI Gateway:支持 AI 应用的性能、安全、可靠性和可观测性分析。该平台支持多 LLM 负载均衡,可运行 OpenAI、Amazon 等各种模型,并未来计划支持构建数据集和微调模型。此外,AI Gateway 与 Workers AI 整合,提供无缝体验,Cloudflare 推出的 类 LangSmith 产品。
苹果在 WWDC 全球开发者大会上推出 Apple Intelligence,这是深度集成到iOS 18、iPadOS 18 和 macOS Sequoia 中的个人智能系统,Apple Intelligence 由多个功能强大的生成模型组成,既有苹果自研的端侧模型也有和 OpenAI 合作的云端大模型,这些模型专门用于用户的日常任务,并可以根据用户的当前活动进行动态调整。
Chrome 127 版本内置 Gemini Nano 端侧模型:上周只是作为新闻提了下,这周仔细看了一下延伸内容,发现这只是谷歌端侧大模型生态计划的一个开始,我试着完整梳理下。
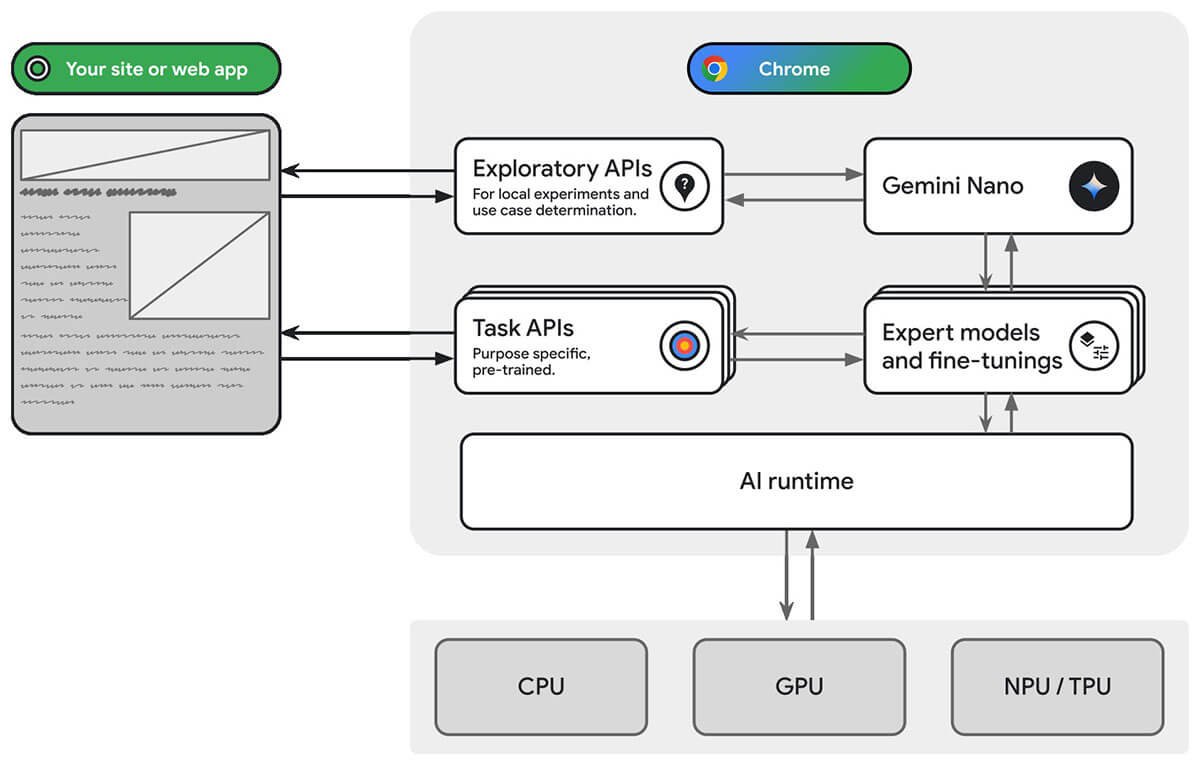
Chrome 本身已经支持通过 Tensorflow.js 或 OMNX WebRuntime 调用 Web API 来跑其他 ML 模型(Expert models),其核心架构如下(文章参考:https://developer.chrome.com/blog/io24-webassembly-webgpu-1?hl=zh-cn):
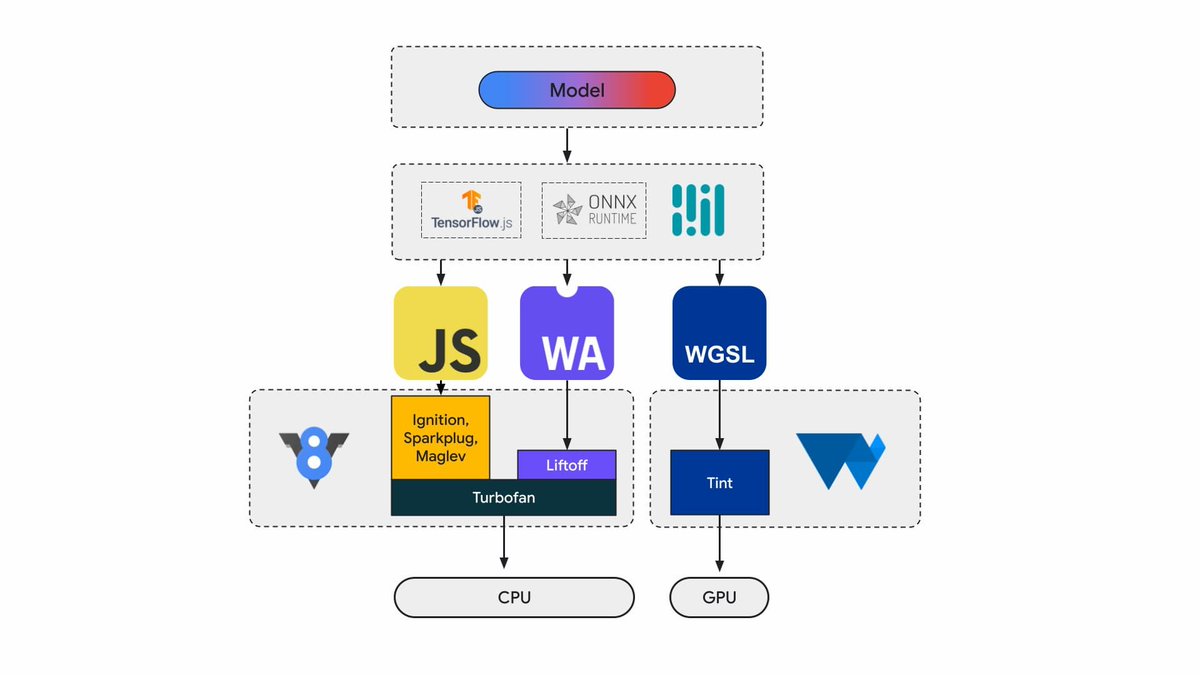
到这里,在 Chrome 上运行各种端侧专门模型的条件已经具备。另一个就是 Visual Blocks ,谷歌也计划不久后推出能够在端侧运行的 Visual Blocks(https://visualblocks.withgoogle.com/#/),这是一个可视化编排工具,比如这个融合 Huggingface 生态的例子(https://huggingface.co/hf-vb),可以在本地提供图片分割、翻译、文本分类、背景移除等原子服务,最后是现有浏览器层面的APIs,这就是释放威力的地方,拥有API就可以操作一切,嵌在浏览器中的模型+编排工具+API,构建Agentic Workflow 的条件都具备了,可以预见首先在浏览器插件这个生态,现有插件都会接入端侧模型能力的,一切提供 Web 形态的产品可以都+AI,而且是免费的 AI,因为端侧模型的推理成本由用户承担,AI 化的成本会极大降低,这个过程是由一个个社区 Web 开发者主导自发进行的。
端侧 Web AI 的 API 设计基于会话式设计,挂在在
window.ai命名空间下:- 创建会话:window.ai.canCreateTextSession
- 流式发送 Prompt API:session.promptStreaming(“你好”) ,异步 API 访问流式请求下的 chunk 消息
- Gemini Nano 的输出速度达到 70+ token/s 远超 GPT-4
最后推荐一篇文章 2024 年 I/O 大会 Web AI 总结:为您的下一个 Web 应用打造的新模型、工具和 API
Luma 发布视频生成模型 Dream Machine:自从 OpenAI 春节期间发布 Sora,就引发了新一波文生视频热潮,从字节的 Dreamina、腾讯的 VideoCrafter2 到右脑科技的 Vega AI、爱诗科技的 PixVerse,还有最近的的快手可灵,动作更逼真、连贯,角色一致性也越来越强,但是最大的痛点是现阶段还无法产出和视频画面匹配的的声音,当然这也是模型结构决定了的,最近我在试着用 Gemini 的多模态 API 为视频生成脚本,然后根据脚本内容生成音乐,最后将音乐与视频合并,工程手段做点探索。

市场
12 位开源老兵跟你聊聊开源和大语言模型的商业化路径选择:探索开源与商业化路径的深度对话,本文汇聚了 12 位行业专家针对开源软件的商业模式、企业选择开源策略的考量、以及大型语言模型(LLM)对开源领域的影响等话题,提供了独到的分析和预测。这些讨论包括了企业服务开源的商业模式,企业是否应采用开源路线,LLM 对开源的影响,开源大模型商业化的可能性和路径,以及应用层对开源软件、基础设施服务和大模型的理解和期望。
总结 Y Combinator 近一年投资的 260 家 AI 公司:Y Combinator 是硅谷的创业孵化器,过去一年投资了 260 多家 AI 初创公司,它们可以说是硅谷乃至全世界 AI 创业趋势的缩影,通过这些 AI 公司的产品和官网,借此了解 AI 的顶尖创业者们究竟在做什么。
深度对谈顶尖 AI 开源项目:大模型开源生态, Agent 与中国力量:在大约一年多的时间里,生成式 AI 的迅速发展中,开源话题毫无疑问是一个引人注目的议题。从 Meta 的 Llama 3 到 Mistral 最新的模型,开源模型的快速发展不仅令人印象深刻,而且推动了 AI 应用在产品中的实际应用。围绕大型模型的生态系统,从推理加速到开发工具,再到智能代理,技术栈的丰富程度虽已孕育出像 Langchain 这样的领军企业,但这仅仅是冰山一角。尤其值得一提的是,随着阿里千问系列、Deepseek 以及中国团队主导的 Yi 在国际舞台上崭露头角,我们不禁思考,除了模仿和追赶,中国在大型模型领域的发展是否还有更多值得我们关注和自豪的成就。最新一期的 Onboard!节目 邀请到了几位高度代表性的重要嘉宾,其中包括来自 Huggingface 的开源老将,通义千问 Qwen 的开源负责人(同时也是 Agent 领域最受关注的项目 OpenDevin 的核心成员),以及最具国际影响力的开源项目 vLLM 的主要负责人,深入探讨了:
- 底层基础大模型的开源与封闭生态,未来可能的发展方向是什么?
- 开源模型的商业化与过去我们在大数据时代看到的 Databricks 等开源商业模式有何异同之处?
- 如何打造一个具有国际影响力的开源项目?
- 还有关于数据、评估等大型模型领域的核心议题等。
Vol.9:构建 AI 产品过程的踩坑经验总结
