Vol.11:AI 应用爆发何时到来?
⼤家好,Weekly Gradient 第 11 期内容已送达!本期介绍了 YC 投资的借助 AI 构建第二大脑类产品,如何打通个人笔记、本地文件和在线实时内容,同时还支持私有部署、保障隐私安全(产品已开源);以 YC 投资的 AI 代码助手为例,看看打造一款 AI 驱动智能开发工具应该包含哪些组件和技术细节(产品已开源);探讨一种新的 Design-to-Code 框架,将设计稿转代码的有效性大幅提高;RAG 文本分块除了语义分块、段落级、循环分块、HyDE,还有哪些高级方法;最后市场部分分享了两篇深度文章,分别从中美市场现状出发,探讨了当下的 AGI 应用还没有大爆发的原因,
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
CharXiv: Charting Gaps in Realistic Chart Understanding in Multimodal LLMs:在真实场景中,报告和各类文件中大量存在图表,对于大型模型推理和 RAG 等场景的理解至关重要。然而,在实际场景中,多模态语言模型(MLLMs)在图表理解方面的能力往往被高估。当前的评估数据集通常过于简化且同质化,侧重于模板式问题,导致了对模型能力的过于乐观的评估。研究小组发现,即使在某些基准上,开源模型似乎超越了一些强大的专有模型(如 GPT Claude Gemini 等),但稍微改变图表或问题就会导致性能下降超过 30%,揭示出模型的鲁棒性问题。为了解决这一问题,研究小组提出了 CharXiv(Chart + arXiv),这是一个包含 2323 个精心挑选、多样化且具有挑战性的图表的综合评估套件(所有图表和问题均由专家手动筛选和验证,以确保质量),来源于 arXiv 论文。
CharXiv 涉及两类问题:
- 描述性问题用于检验图表的基本元素
- 推理性问题则需要整合复杂的视觉信息
多模态语言模型的数据表现:
- 最强的专有模型 Claude 3.5 Sonnet、GPT-4o、Gemini 1.5 Pro,准确率分别为 60.2%、47.1%、43.3%
- 最强的开源模型 Phi-3 Vision、InternVL Chat V1.5 的准确率仅为 31.6%、29.2%
- 专有模型和开源模型的准确度均远低于人类达到的 80.5%
- 现有的 MLLMs 在图表理解方面的能力远低于预期,特别是在处理复杂的推理任务时
Automatically Generating UI Code from Screenshot: A Divide-and-Conquer-Based Approach:这篇讨论了一个名为 DCGen 的算法,用于从屏幕截图生成用户界面代码。DCGen 是一种新的 Design-to-Code 框架,能有效将设计稿转换为 UI 代码。通过将截图分解为小片段,然后利用 MLLM 生成描述并整合成完整的 UI 代码,DCGen 在视觉相似性上比其他方法提升了 14%。该框架采用分而治之的策略,分割和组装两个阶段。在分割阶段,DCGen 递归地将截图划分为更小的片段,然后将每个片段传递给 MLLMs 进行代码生成。在组装阶段,通过递归的组装过程持续进行,直至网站的整体结构得以重建。文中也指出了一些局限性,如上下文长度限制和对动态网站的处理挑战。
LumberChunker: Long-Form Narrative Document Segmentation:这篇论文介绍了文本分块新方法 LumberChunker ,它利用 LLM 动态地将文档分割成语义独立的块。这种方法基于一个前提:当内容块的大小可以变化时,检索效率会提高,因为这样可以更好地捕捉内容的语义独立性。LumberChunker 通过迭代地提示 LLM,在一系列连续段落中识别内容开始转变的点,从而确保每个块在上下文中是连贯的,但与相邻块有所区别。
LumberChunker 遵循一个三步流程:
- 首先,按段落对文档进行分割。
- 其次,通过追加连续的块,创建一个组 (Gi),直到超过预定义的标记计数 θ。
- 最后,将 Gi 作为上下文输入到 Gemini,Gemini 确定显著内容转变开始出现的 ID,从而定义了 Gi+1 的开始和当前块的结束。
这个过程在整个文档中循环重复。
CodeRAG-Bench: Can Retrieval Augment Code Generation?:CodeRAG-Bench 是用于研究代码生成辅助检索的评估基准,强调高质量上下文对提升代码质量的重要性。基准包含多个任务和文档资源,旨在推动高级代码生成技术发展。评估方法主要采用 NDCG、精确度和召回率,密集检索器在某些情况下优于稀疏检索器。研究探讨了 Command-R 和不同语言模型在代码库处理和程序生成任务中的效果,强调提升上下文长度和处理能力的重要性。在各任务中,模型表现有差异,且对领域陌生度和检索结果质量敏感,有改进空间。研究发现,增加文档数量可能会干扰生成结果,RACG 在提升较弱代码语言模型表现方面有一定作用,但大多数模型容易受到额外上下文的干扰,在特定任务上表现不佳,Gemini-1.5 在非标准资源上表现不佳,无法有效执行 RACG。
工程
Anthropic 的官方博客:Claude 的热度一直比 ChatGPT 低,深度使用了一周 Claude 3.5 Sonnet,在我的测试案例下整体效果比 GPT-4o 好,期待下半年的 Opus 3.5,Haiku 3.5,我系统去阅读了一遍官方博客,从提示工程,模型性能测试,模型可观测性,安全等全方位讲了 Claude 和大模型通用知识,而且国际化做的很好,直接支持中文,不需要代理也可以直接访问,强烈推荐有时间的朋友系统阅读一遍。
Character.AI 在推理基础设施优化方面的实践经验:CharacterAI 每月访问量超过 2.5 亿次,月活跃用户约 2000 万,每天处理大约 20 亿次推理,这篇文章介绍了其技术团队通过一系列的关键创新,如采用多查询注意力、混合注意力层等技术,成功减少了推理过程中的瓶颈,包括缓存大小及内存效率设计,以及状态缓存等方面;采用整数量化进行训练和推理,而非普遍采用的“后训练量化”技术,从而显著提高了训练效率,使推理过程更高效、具有成本效益并可持续弹性扩展来支持产品的快速增长。
揭秘大模型技术在快手的应用:本文揭示了快手如何通过大模型技术,特别是快意大模型,在搜索和内容生成方面实现技术的落地和商业价值的转化。快意大模型的三个不同规模版本,成功整合到了 AI 小快、智能客服等多个产品中,显示出了强大的能力。快手的解决方案包括构建图神经网络模型和强化学习模块,以及推出 GPT 卡片、AI 搜、GPT 多轮对话和角色聊天等产品,以提升搜索效率和补充搜索供给。这些产品的设计旨在以最合适的形式回答特定类型的问题,并通过不断优化用户体验,确保模型的实用性和准确性。 快手的技术探索还扩展到了视觉领域,通过 “万物皆可 token” 的理念,快手开发了 Image Tokenizer 和 Video-LaVIT 框架,实现了图像和视频的多模态理解和生成。快手的大模型技术在广告制作和视频内容生成方面也展现了巨大的应用价值,特别是在快手内部的广告生成应用中,快手的模型能够有效地生成高质量的广告内容,为企业提供了新的营销工具。
蚂蚁首个开源 Graph RAG 框架设计解读:传统的 RAG 主要依赖向量数据库进行文档检索,而改进后的 Graph RAG 则引入了知识图谱技术,使用图数据库存储知识,以提供更高质量的上下文。文章详细比较了传统 RAG 和 Graph RAG 的差异,指出传统 RAG 存在诸如知识库内容缺失、TopK 截断有用文档、上下文整合丢失等问题。为了解决这些问题,Graph RAG 通过增强知识确定性和优化上下文整合策略进行了改进。 在通用 RAG 的设计中,提出了索引存储的抽象 IndexStore,以及索引加工和存储的接口,包括 Transformer 和 IndexStoreBase。此外,文章还介绍了开源的 AI 原生数据应用开发框架 DB-GPT、知识图谱系统 OpenSPG 和图数据库 TuGraph,并展示了如何通过这些技术实现 Graph RAG,最后探讨了 Graph RAG 的未来优化方向,包括内容索引阶段的图谱元数据、知识抽取微调、图社区总结、多模态知识图谱和混合存储等方面,以及检索生成阶段的图语言微调、混合 RAG 和测试验证等,RAG 的未来可能会演进为带有记忆和规划能力的智能体架构。
产品
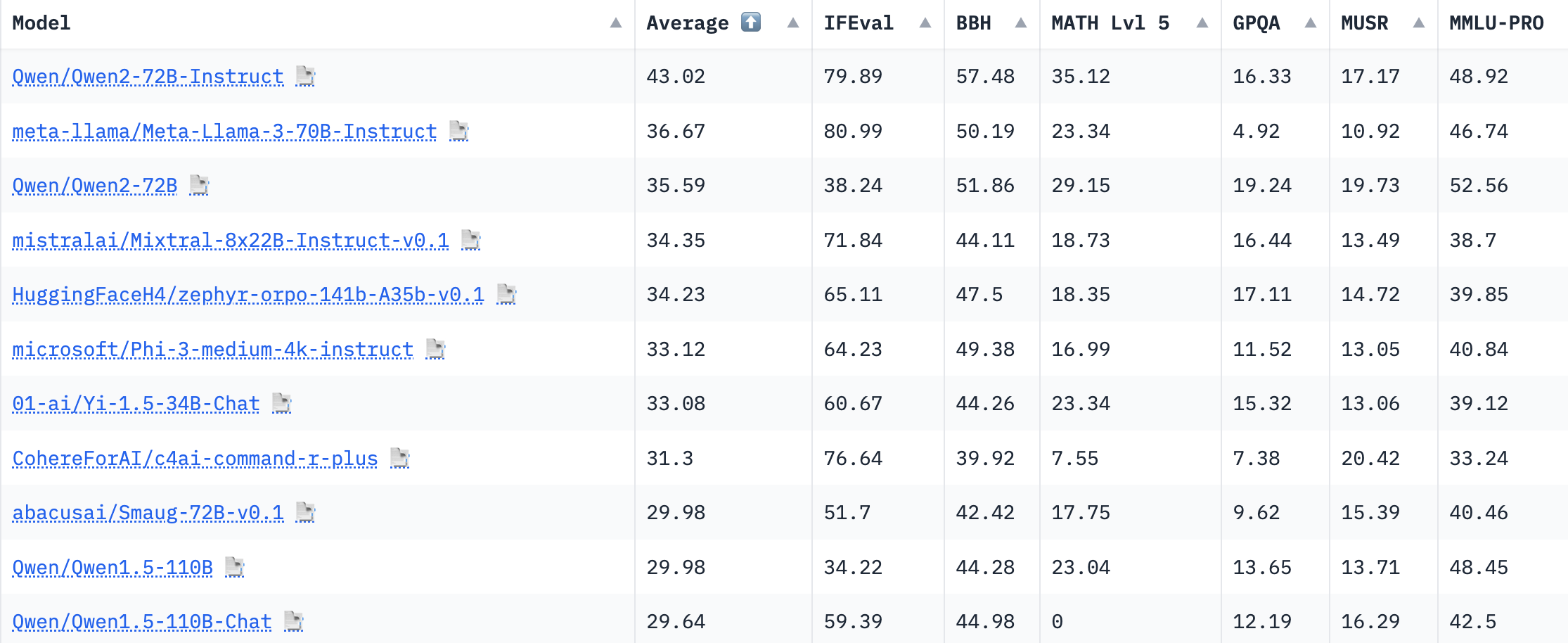
更难、更好、更快、更强:LLM Leaderboard v2 现已发布:HuggingFace 发布开源模型排行榜 2.0 版本,出品团队认为论文或营销发布中的得分缺乏可复现的代码,有时令人怀疑,大多数情况下只是通过优化的提示或评估设置来尽量提升模型表现。因此,他们决定在完全相同的设置 (同样的问题,按相同的顺序提问等) 下评估参考模型,从而收集完全可复现和可比较的结果。这篇文章分析了现有基准测试已经被过度使用和饱和的原因,介绍了如何收集未污染的高质量数据集,如何设计使用可靠指标测量模型关键能力的新基准测试,系统看下来,整个测试过程很严谨,推荐,开源模型能力榜单以后关注这个就好。
Google 开源 Gemma 2 的 9B 和 27B 版本,其中 27B 版本可以在单个 NVIDIA A100 80GB 或 NVIDIA H100 上全精度运行推理,模型下载地址:https://huggingface.co/google/gemma-2-9b
Khoj:YC 投资(YC S23)的 AI 第二大脑产品,它可以帮助用户从个人笔记或在线资源中快速准确地找到答案,并提供深入的专业主题辅助,如健康、辅导和治疗等,支持 Multi Agent 进行对话交流,支持联网搜索、语义搜索笔记等,除此之外,Khoj 还支持语音提问、在线搜索、图片生成等能力,可以接入本地模型私有化部署、与 笔记软件 Obsidian 以及本地文件等无缝整合,产品理念非常不错,项目开源地址:https://github.com/khoj-ai/khoj
内容源横跨个人笔记,本地文件和在线实时内容,同时还支持私有部署,保障隐私安全,理念不错。
Bloop:YC 投资(YC S21)的 AI 代码助手,支持 10+ 编程语言,与 Github 实现集成,能够实现对代码进行自然语言提问、搜索或生成 Patch 并应用在代码中,帮助工程师提高生产力。其功能包括解释代码、上下文编写代码、自然语言搜索代码、问题修复、支持多语言以及代码重复检测和去重。Bloop 的向量数据库使用开源的 Qdrant,是一个基于 Rust 编写的高性能的向量数据库,支持多租户,混合搜索,目前已开源;Bloop 的 Embedding/全文搜索方案使用 Tantivy,基于 Rust 实现的全文搜索引擎库,是一个 Elasticsearch 和 Apache Solr 的替代品,支持中文的全文检索、关键词检索 ;Bloop 基于 tree-sitter 进行代码的 chunking 以及语义分析,Github/VSCode 都是基于 tree-sitter 进行分块索引,是一个支持 10+ 主流编程语言的语义分析库,也是开源的。
这基本是一个 AI 代码辅助生成类产品的标准组成了,这个产品也开源了https://github.com/BloopAI/bloop、
MarsCode:字节跳动推出的“基于豆包大模型的智能开发工具”,整体有编程助手和云端集成开发环境(IDE)两个核心产品组成,功能特性方面和前面的 Bloop 大部分一致,但是产品的整体完成度更高。
市场
为什么 AGI 应用还没有大爆发?:这篇文章是拾象科技 CEO 李广密和商业作者张小珺的「全球大模型季报」第三集,也是对 2024 年上半年全球大模型发展的总结。虽然 GPT-4 已经面世一年多,但人工智能应用的爆发速度明显迟缓,直到今天,只有 Perplexity 实现了 PMF。AI-native 应用的 PMF 代表产品-模型-匹配。模型能力的解锁是逐步进行的,AI 应用的探索也经历了从组合性创新到探索性创新再到变革性创新的演变。Perplexity 的 AI 问答引擎代表了第一阶段的组合性创新,随着 GPT-4o、Claude-3.5 Sonnet 的发布,多模态、推理能力的提升,我们正处于 AI 应用爆发的前夜,也许在 GPT-5 发布半年后,我们就有很大可能迎来 AI-native 应用的大规模涌现。成本的降低也将是应用爆发的关键。如果 OpenAI 的 GPT-4o 能够大幅降低开发者的 API 成本,甚至降至可以忽略的程度,哪些应用会迎来爆发呢?
在本次讨论中,还分享了对 Nvidia、Apple、Amazon、Tesla 等科技巨头在人工智能投资方面的观察。如今,绝大多数 AI 应用都站在这些巨头的核心战场上,巨头们如何构建自己的 AI 产品组合也会影响着 AI-native 应用的发展和天花板。AI 不会颠覆这些巨头,而是会依附于它们。
AI 应用爆发何时到来?:前面那篇偏美国市场,这篇偏国内市场,AI 的投资在向应用侧迁移、大模型的推理成本会持续下降、国内还正处于 ChatGPT Moment 的第一阶段,以及 AI 应用爆发需要哪些前提、AI 应用开发需要具备的能力等等,在 AGI Playground 2024 上,创新工场管理合伙人 & Co-CEO 汪华就这些话题,进行了一场干货信息满满的 AGI 创业攻略分享,这篇文章是基于演讲内容整理的文章。
Vol.11:AI 应用爆发何时到来?
