Vol.29:可视化呈现RAG的工作过程
大家好!Weekly Gradient 第 29 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
WorkflowLLM:一个以数据为中心,提升大语言模型(LLM)在工作流编排方面的能力,从而推动流程自动化从机器人流程自动化(RPA)向代理流程自动化(APA)的转变:论文首先介绍了流程自动化的发展历程,从传统的机器人流程自动化(RPA)到当前的代理流程自动化(APA),后者利用 LLM 构建工作流,实现工作流协调过程的自动化。然而,目前的 LLM 在编排复杂工作流方面存在局限性,如动作规模受限和逻辑结构简单等问题。为了解决这些问题,作者提出了 WorkflowLLM,这是一个包含数据集构建、模型训练和评估的框架。
数据集 WorkflowBench 的构建过程包括数据收集、查询扩展和工作流生成。数据收集阶段从 Apple Shortcuts 和 RoutineHub 收集真实世界的工作流数据,并转录为 Python 风格的代码,同时使用 ChatGPT 生成分层思维。查询扩展阶段通过 ChatGPT 生成更多任务查询,以丰富工作流的多样性和复杂性。工作流生成阶段使用在收集数据上训练的注释器模型为合成查询生成工作流。最终,通过质量确认的合成样本与收集的样本合并,形成了 WorkflowBench。基于 WorkflowBench,作者对 Llama-3.1-8B 进行了微调,创建出了 WorkflowLlama。实验结果表明,WorkflowLlama 在编排复杂工作流和在未见过的 API 上的泛化性能都有显著提升。此外,WorkflowBench 在分布外任务规划数据集 T-Eval 上也展现出强大的零样本泛化能力。
RAGVIZ:可视化呈现RAG的工作过程:RAGViz 是由 CMU 开发的一个可视化工具,旨在帮助用户理解和诊断检索增强生成系统。该工具通过高亮显示生成的标记序列对输入标记的关注度,并通过颜色强度表示关注度的程度。此外,RAGViz 还展示了生成输出对每个检索段落的关注度,以及累积的文档级别的注意力分数。用户可以通过拖动选择来检查任何标记序列的累积关注度,以及通过文档切换功能来比较添加或移除特定标记和文档对生成输出的影响。RAGViz 还允许用户自定义上下文文档数量,并提供了 API 密钥认证来确保请求的安全性。RAGViz 的系统架构包括近似最近邻(ANN)索引、后端服务器、LLM 推理服务器和前端用户界面。ANN 索引用于密集检索,将查询和文档编码为高维特征向量,并通过相似性搜索找到最近邻。上下文构建器处理语言模型上下文的构建逻辑,包括加载嵌入模型、管理后端逻辑和存储语料库。生成和注意力输出组件使用 GPU 节点运行 LLM 推理任务,并使用 HuggingFace 模型库获取注意力分数。RAGViz 的演示和案例研究展示了其在识别和调试外部幻觉方面的能力,以及滑动窗口片段提取方法的应用。
Github地址:https://github.com/cxcscmu/RAGViz.
大语言模型在算法设计(AD)中的应用:一篇关于大语言模型在算法设计(AD)中应用的综述性论文。论文首先介绍了算法设计的重要性以及传统手工设计算法的繁琐和耗时。随后,论文强调了 LLMs 在语言理解、数学推理和代码生成等领域的出色表现,以及它们在算法设计中的潜力。作者提出了一个新的多维度分类法来分析 LLM4AD,包括 LLMs 的作用、搜索技术、提示策略和应用领域。论文还对 LLM4AD 的现状进行了系统的梳理和分类,包括论文收集分析的四个阶段,以及论文发表数量趋势、领先机构和国家的统计。接着,论文详细描述了 LLM4AD 的四种范式:大模型作为优化算子(LLMaO)、大模型用于结果预测(LLMaP)、大模型用以特征提取(LLMaE)和大模型用来算法设计(LLMaD)。文章进一步探讨了 LLM4AD 中的搜索方法,并对提示词设计进行了分析。最后,文章提出了 LLM4AD 的未来发展方向,包括算法设计大模型、多模态 LLM、人类 -与大模型交互、基于 LLM 的算法评估、理解 LLM 的行为、全自动算法设计以及 LLM4AD 的标准测试集和平台。
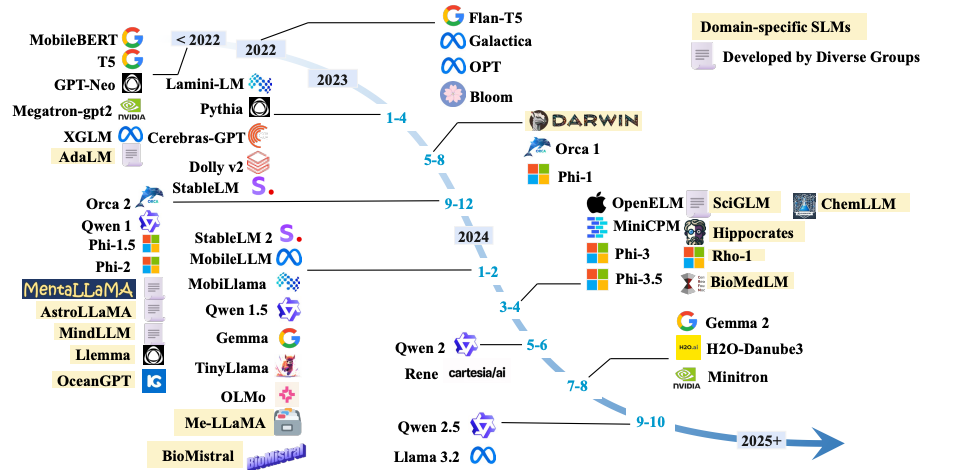
一篇小语言模型(SLMs)的综述,包括技术进展、性能提升策略、应用场景以及在移动和边缘设备上的部署情况,并对通用领域、任务特定和领域特定的小语言模型进行了深入分析:论文首先介绍了小语言模型(SLMs)的定义和它们因低延迟、成本效益、易于开发和定制而受到青睐的原因,特别适合资源受限的环境和领域知识获取。接着,文章概述了 SLMs 的发展时间线,并详细介绍了构建 SLMs 的基本概念,包括 Transformer 架构、预训练范式、从 LLMs 获取 SLMs 的方法(剪枝、知识蒸馏和量化),以及模型压缩技术的比较。论文进一步探讨了提升 SLMs 性能的高级策略,包括从零开始训练 SLMs 的创新方法、监督式微调、数据质量在知识蒸馏中的重要性、蒸馏技术、量化策略,以及 LLMs 中对 SLMs 有贡献的技术。在应用方面,文章分析了 SLMs 在问答、编程、推荐系统、网络搜索和移动设备上的应用,并讨论了在资源受限的边缘设备上部署 SLMs 的策略。文章还深入探讨了 SLM 在移动和边缘设备上的部署,包括内存效率优化和运行时效率优化的方法。最后,文章详细讨论了小语言模型在不同领域的应用,包括通用领域 SLMs 的优势、模型规格、训练数据集、训练算法,以及领域特定 SLMs 如医疗保健、科学和金融法律领域的应用实例。
工程
聊一聊做角色扮演大模型的经验:作者分享了在角色扮演大模型领域的经验,包括产品设计的重要性、角色扮演大模型的认知、消费者分析、产品设计拾遗,以及模型训练的经验分享。
- 角色扮演大模型的产品设计对技术方案和用户体验至关重要。产品的形态决定了目标用户群体的范围,并且会影响模型的输出设计和交互模式。
- 角色扮演大模型的关键在于角色一致性和 “自我意识”。模型应能够保持角色立场,甚至能够说 “不”,以及主动引导用户去演绎,为用户创造沉浸感。
- 角色扮演产品的竞争对手可能是电影、书籍、剧集、动画等产业。这些产业提供了用户逃避现实、获取精神满足的方式,角色扮演大模型需要为用户提供更加立体生动的体验。
- 角色扮演大模型产品设计中的一些碎碎念,包括产品卖点的探讨、带 os 与不带 os 的选择、单角色与多角色的优缺点,以及降低用户输入门槛的考量。
- 数据生产的核心是 “质量优于数量”。即使是不到一千条高质量数据,也能取得不错的效果。
- 人设卡在数据生产中非常关键。它们代表了多样的 prompt,有助于避免模型过拟合,并且可以帮助用户在线上构建各类人物。
- 模型微调时的数据配比、模型选择、Lora 与全参 sft 的选择都是关键技术点。全参微调可以让模型注意到长尾词的使用,而 Lora 虽然节省算力,但可能会有信息损失。
- 关于 continue pre-train 和 DPO 等其他技术的应用,需要根据具体情况权衡其在模型训练中的必要性和成本效益。
- 评估角色扮演模型的好坏不能仅凭一些指标,需要结合实际的业务指标和用户体验进行综合评估。
17 种 prompt engineering 方法大集合:文章详细列举了 17 种 prompt engineering 技术,包括 Zero-shot prompt、Few-shot prompt、链式思考(COT)prompt、自我一致性、生成知识 prompt、prompt chaining、思维树(TOT)、检索增强生成(RAG)、自动推理并使用工具(ART)、自动 prompt 工程师、Activet-prompt、方向性刺激 prompt、PAL 程序辅助语言模型、ReAct 框架、自我反思 Reflexion、多模态思维链 prompt 和基于图的 prompt。每种方法都有相应的介绍、示例和相关论文引用。这些技术涵盖了从简单的文本分类到复杂的多轮推理和工具使用的多种应用场景,旨在提高语言模型的推理能力、准确性和适应性。
- Zero-shot prompt:不需要示例或训练数据,直接利用自然语言描述任务或问题,让模型生成相应回答。
- Few-shot prompt:通过提供少量示例来引导模型生成回答,能在一定程度上提升模型的表现和适应性。
- 链式思考(COT)prompt:引导模型进行逐步推理和连续思考,以生成更深入、准确答案。
- 自我一致性:通过多样性的推理路径选择最一致的答案,提高 CoT 提示在涉及算术和常识推理的任务中的性能。
- 生成知识 prompt:先从语言模型中生成知识,然后在回答问题时作为额外的知识进行提供。60
- Prompt chaining:将一个任务分解为多个子任务,根据子任务创建一系列 prompt 操作。
- 思维树(TOT):维护一棵思维树,思维由连贯的语言序列表示,用于解决问题的中间步骤。
- 检索增强生成(RAG):接受输入并检索相关文档,结合文档和原始输入生成最终输出。
- 自动推理并使用工具(ART):从任务库中选择多步推理和使用工具的示范,引导模型生成和执行任务。
- 自动 prompt 工程师:通过生成和评估候选指令,自动寻找最适合任务的指令。
- Activet-prompt:基于不确定性的主动选择策略,挑选最有帮助和信息量大的问题进行注释,以提升模型在复杂推理任务中的性能。
- 方向性刺激 prompt:为输入实例生成辅助方向刺激提示,引导大语言模型生成符合期望输出的新框架。
- PAL 程序辅助语言模型:使用 LLMs 读取自然语言问题并生成程序作为中间推理步骤。
- ReAct 框架:结合推理和行为,使 LLMs 能够为任务生成口头推理轨迹和操作。
- 自我反思 Reflexion:通过自我反思,使智能体能够从过往失败中学习,优化自身行为。
- 多模态思维链 prompt:将文本和视觉融入到一个两阶段框架中,实现推理生成和答案推断。
- 基于图的 prompt:通过子图相似性的模板,实现预训练和下游任务的有效结合。
Marco-o1:Marco-o1 是由阿里国际 AI 团队开发的一个大语言模型,它不仅关注数学、物理和编程等有标准答案的学科,更注重开放性问题的解决。该模型通过链条思维(CoT)微调、蒙特卡洛树搜索(MCTS)、反思机制和创新的推理策略进行了优化,以适应复杂的现实世界问题解决。Marco-o1 的研究工作受到 OpenAI 的 o1 模型启发,目前还在持续优化和改进中。Marco-o1 模型的亮点包括使用开源 CoT 数据集和自研合成数据进行 CoT 微调,通过 MCTS 扩展解决方案空间,实施新颖的推理行动策略和反思机制,以及在多语言和机器翻译任务中的应用。该模型在英语和中文版的 MGSM 数据集上的准确率分别提升了 +6.17% 和 +5.60%,并在翻译任务中展现了对俚语细微差别的理解能力。
开源健康追踪项目 Halo:Halo 项目旨在推动健康追踪领域的开源发展,提供一种动手实践的方式来理解健康追踪设备背后的技术,项目代码已经在 GitHub 上开源。通过 AccessorySetupKit 框架,Halo 应用能够简化设备连接管理流程,并提高用户隐私。文章详细介绍了如何使用 CoreBluetooth 框架和 AccessorySetupKit 框架来管理与戒指的通信,包括扫描、连接、发现服务和特征,以及数据读写操作。最后,提供了一个示例代码,展示了如何将这些功能集成到应用程序的主界面中。未来,项目计划探索如何与戒指交互,包括读取电池电量、获取传感器数据等功能。
LLM tool功能横向测试:作者对多个 LLM 进行了测试,评估了它们在复杂指令理解、长文本处理、tool 调用和生成 json 等方面的能力。测试任务基于真实业务场景,虽然难度较大,但能够更好地反映模型的实际应用能力。测试结果显示,尽管有些模型在某些方面表现良好,但在整体 tool 调用能力上,大多数模型都有不同程度的问题。例如,Claude 在国内可用性较差,而 Gemini 在 tool 能力上不如其他方面表现出色。Qwen 在国内的表现较为亮眼,但受限于速率限制。GLM、Step、Moonshot 等其他模型在测试中也显示出了不同程度的问题。作者对测试结果进行了详细的说明,并强调了在选择 LLM 时需要考虑到 tool 调用能力的重要性。最终,作者对 国内LLM 的 tool 调用能力表示不容乐观,并呼吁各家模型厂商加快改进。
产品
Mistral AI 开源多模态模型 Pixtral Large ,它拥有 124B 的开放权重,能够理解复杂的图像、文档和图表,并在多个多模态基准测试中表现出色 :这是一款基于 Mistral Large 2 的 124B 开放权重多模态模型。该模型在 MathVista、DocVQA 和 VQAv2 等基准测试上表现出色,能够理解图像、文档和图表,同时保持了 Mistral Large 2 在文本理解方面的领先水平。Pixtral Large 配备了一个 123B 参数的多模态解码器和一个 1B 参数的视觉编码器,以及一个 128K 上下文窗口,可以容纳至少 30 张高分辨率图像。用户可以通过 Le Chat、API(
pixtral-large-latest)或直接下载来使用该模型。该模型在 MM-MT-Bench 评估中显示出与 Claude-3.5 Sonnet、Gemini-1.5 Pro 和 GPT-4o 相比的竞争力。此外,Mistral AI 还更新了 Mistral Large 模型,发布了 Mistral Large 24.11 版本,提供了更好的长上下文理解和功能调用准确性。Mistral AI 推出了 Le Chat 的重大更新,增加了网页搜索、创意画布、文档和图像理解、图像生成等功能
网页搜索功能,支持引用,旨在帮助学生和专业人士进行学习、研究和工作。
提供了一个名为 Canvas 的新界面,用于创意和思维导图,支持与大语言模型(LLMs)共同创作和编辑内容,并且可以导出成果。
利用新的 Pixtral Large 多模态模型,Le Chat 现在能够更快速准确地理解和总结大型复杂的 PDF 文档和图像。
与 Black Forest Labs 合作,集成了 Flux Pro 图像生成模型,用户可以直接在 Le Chat 中生成高质量的图像。
引入了 Le Chat Agents,用于自动化重复性工作流程,如收据扫描、会议记录摘要和发票处理。
所有新功能目前作为免费测试版提供。在线体验:http://chat.mistral.ai/
阿里推出Qwen2.5-Turbo ,支持 1M tokens 的长序列处理,提升了推理速度和成本效率,并在长文本任务中表现出色:Qwen2.5-Turbo 是针对长序列处理能力和推理效率进行优化的最新模型版本,它将模型的上下文长度从 128k 扩展到 1M,这意味着能够处理大约 100 万个英文单词或 150 万个汉字的数据,等同于 10 本长篇小说的文本量。该模型在长序列任务中的性能得到显著提升,在大海捞针任务上实现了 100% 的准确率,并在长文本评测集 RULER 上获得了 93.1 分。同时,该模型在短序列能力上也保持了强劲的竞争力。此外,Qwen2.5-Turbo 通过稀疏注意力机制实现了推理速度的 4.3 倍加速,并保持了价格稳定,仍为 0.3 元 / 1M tokens,使得在相同成本下能够处理的 Token 数量增加到之前的 3.6 倍。用户可以通过阿里云大模型服务平台的 API 服务,或者通过 HuggingFace Demo 或者 ModelScope Demo 进行体验。
DeepSeek 全新研发的推理模型 DeepSeek-R1-Lite 预览版正式上线
- DeepSeek-R1-Lite 预览版模型的推理过程包含大量反思和验证,思维链长度可达数万字,展现出在数学、代码以及各种复杂逻辑推理任务上的高效推理效果。
- 在权威评测中,DeepSeek-R1-Lite 取得了卓越的成绩,显著超越了 GPT-4o 等知名模型,尤其在美国数学竞赛(AMC)的 AIME 难度等级以及全球顶级编程竞赛(codeforces)中的表现。
- DeepSeek-R1-Lite 的推理性能提升了,其准确率与所给定的推理长度呈正相关,且相比传统的多次采样 + 投票方法,模型的思维链长度增加后更高效。
- DeepSeek-R1-Lite 预览版目前仅支持网页使用,不支持 API 调用,且所使用的基座模型较小,无法完全释放长思维链的潜力。
其他
Perplexity 推出一键购物功能,通过整合产品比较、在线评论摘要和一键购买功能,帮助用户高效地从搜索到购买。
市场
- 海外风险投资机构Menlo Ventures最新发布的《2024年企业生成式AI现状》:企业在 AI 应用层的投资增长迅速,特别是在人工智能开发助手、支持聊天机器人、企业搜索与检索、数据提取与转换以及会议总结等领域。企业正在思考如何构建和购买 AI 工具,目前内部开发和第三方购买的比例接近 1:1。企业在选择 AI 应用时更注重投资回报和行业特定定制,而不是价格。大型企业正面临着新兴创业公司的挑战,尤其是在法律、金融服务和媒体娱乐等行业。现代 AI 技术栈已经稳定,企业正在采用多模型策略,其中 RAG(Retrieval-Augmented Generation)设计模式的使用增加,而精细调优的实例相对较少。企业正在寻找能够高效存储和检索知识的数据库和数据管道解决方案,以支持 RAG。此外,AI 代理的出现正在推动 AI 的下一次转型。预计 AI 将继续侵蚀传统服务提供商的市场份额,并导致 AI 技能人才的短缺和工资溢价。
- 大模型+知识库厂商全景报告:描述了大模型与知识库结合的市场定义,即如何通过这种结合改善企业的知识检索和应用,以及如何支持企业管理层和全体员工。它强调了大模型技术的成熟和应用场景的快速实现,以及知识库作为数据资产对大模型落地的重要性。报告进一步阐述了企业对大模型和知识库的核心需求,包括智能化知识管理全流程、快速实现场景化知识搜索智能应用以及实现精准、安全的知识赋能。讨论了供应商在知识库全流程智能化管理、支持企业自建场景化智能应用、具备丰富的 RAG 工程化经验以及提供数据安全管理等方面的能力要求。入选供应商符合所有厂商能力要求,并在过去一年内至少服务了两家企业。
观点
-
• Scaling law 目前尚未见顶, 合成数据和 reasoning models 可能是解决数据限制的方案
• 未来 post-training 环节的成本可能会超过 pre-training,只靠人类很难提高模型质量,需要更 scalable 的监督方法
• Anthropic 的优势之一就是 RL,并且可能是做 RL 做得最好的
• Anthropic 内部的工程师认为 Sonnet 3.5 是第一个能帮他们节省时间的模型,但团队目前并不打算开发自己的IDE
• 出于安全性的考虑,Computer Use 目前不会直接面向 to C 开放,而是以 API 的形式发布
• “Compressed 21st Century” 的愿景下,AGI 可以在生物学和医学领域推动突破性进展,因为监管、伦理以及生物系统本身的复杂性,AI 建模生物系统的难度很高,但 AI 系统至少可以帮助改进临床试验系统,提高临床试验的效率和成功率
• 今天科学家带领科研团队的模式在未来会变成科学家和 AI 系统一起工作,这些 AI 系统可以像研究助理一样被分配到具体研究任务中
• LLMs 领域还有很多问题值得研究,比如机制可解释性和 Long Horizon 是很值得关注的领域
Vol.29:可视化呈现RAG的工作过程
