Vol.39:从 DeepSeek R1 看 Scaling Law 的未来
大家好!Weekly Gradient 第 39 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
Hugging Face 主导的开源社区复现 DeepSeek R1 工作最新进展:
GRPO 的应用与效果
- 实验成果:nrehiew 将 GRPO 应用于 Qwen2.5-0.5B 基础模型,在 GSM8k 基准测试中获得了约 51% 的准确率,比未优化的模型提高了 10 个百分点。这表明 GRPO 在某些模型上具有显著的优化效果。
- 模型限制:尽管在 Qwen2.5-0.5B 上取得了成功,但在其他基础模型(如 Llama 3)上尚未复现类似效果。Sea AI Lab 的研究指出,基础模型的自我反思能力可能更多是其固有特性,而非 GRPO 优化的结果。
- 资源优化:Unsloth 团队通过优化,仅使用 15GB 的显存即可训练多达 150 亿参数的模型,这意味着 GRPO 可以在 Google Colab 等免费平台上使用,大大降低了实验门槛。
数据集与推理能力
- 小数据集的潜力:研究表明,复杂的推理能力可能不需要大规模数据训练,而是可以通过少量精心挑选的样本实现。例如:
- LIMO 数据集:仅使用 817 个训练样本,在 AIME 和 MATH 基准上取得了出色表现。这表明高质量的小数据集可能比大规模数据更有效。
- s1K 数据集:包含 1000 个精心挑选的数学问题,微调后的 Qwen2.5-32B-Instruct 模型在竞赛数学基准上超越了 OpenAI 的 o1-preview 模型 27%。
- 推理深度与性能:通过预算强制技术(如添加“等待”标记或结束标记)延长或截断模型的推理时间,可以显著提升模型在不同数学基准上的性能。
奖励函数与优化
- 奖励函数设计:Alexander Doria 提出了为诗歌生成设计奖励函数的方法,这是 GRPO 在非传统“可验证”领域应用的首批公开示例之一。
- 余弦奖励函数:Yeo 等人提出了一种新的奖励函数,通过激励正确生成的思维链(CoT)更短,错误生成的 CoT 更长,从而稳定强化学习训练,特别是在模型上下文大小有限的情况下。
PIKE-RAG:解锁领域私有数据价值,推动 LLMs 工业应用落地:PIKE-RAG 旨在解决以下问题:
知识来源的多样性:现有 RAG 方法在从多样化的数据源中高效提取私有知识和揭示潜在思考逻辑方面存在困难,尤其是在复杂的工业场景中。PIKE-RAG 通过构建多层异构图,能够表示不同层次的信息和知识,从而更好地解决这一问题。
多样的能力与统一方法的矛盾:现有 RAG 方法未能充分考虑不同应用场景中的复杂性和特定需求。通过任务分类和系统能力分级,PIKE-RAG 提供了一种能力需求驱动的方案搭建策略,显著提高了系统在不同复杂性问题上的适应能力。
LLMs 的领域专业知识不足:在工业应用中,RAG 需要利用专业领域的私有知识和逻辑,但现有方法在应用于专业领域时表现不佳,尤其是在 LLMs 不擅长的领域。PIKE-RAG 通过知识原子化和任务动态分解,增强了对领域特定知识的提取和组织能力。此外,该系统能够自动从系统交互日志中提取领域知识,通过 LLMs 微调将学习到的知识固化下来,以更好地应用于未来的问答任务中。
论文链接:https://arxiv.org/abs/2501.11551
GitHub 链接:https://github.com/microsoft/PIKE-RAG
R1-Zero 或许并不存在 “顿悟时刻”:来自新加坡 Sea AI Lab 等机构的研究者再次梳理了类 R1-Zero 的训练过程,并在一篇博客中分享了三项重要发现:
在类似 R1-Zero 的训练中,可能并不存在「顿悟时刻」。相反,我们发现「顿悟时刻」(如自我反思模式)出现在 epoch 0,即基础模型中。
他们从基础模型的响应中发现了肤浅的自我反思(SSR),在这种情况下,自我反思并不一定会导致正确的最终答案。
仔细研究通过 RL 进行的类 R1-Zero 的训练,发现响应长度增加的现象并不是因为出现了自我反思,而是 RL 优化设计良好的基于规则的奖励函数的结果。
验证了我看完报告后的疑惑点,这个所谓“顿悟时刻”比较容易引起误解,这其实是一个渐进的过程,从预训练的基础模型就出现了反思(比如 Claude3.5 就有,对标 GPT-4 的这一代 pre-train model 基本都配了 COT 数据),也能解释 RL 直接在小模型没效果,但是蒸馏(增加 COT 数据配比)有效果,R1-Zero 响应长度的不断增加不是由于自我反思的出现,而是 RL 优化基于规则的奖励功能的结果。
代理推理:使用工具进行深度研究的推理 LLMs:牛津大学提出了 Agentic Reasoning 框架,通过整合外部工具使用代理(Agents),增强 LLM 的推理能力。该框架引入了三种关键代理:Mind Map 代理(用于构建知识图谱以跟踪逻辑关系)、Web-search 代理(用于实时检索信息)和 Coding 代理(用于执行代码分析),这些代理与 LLM 动态交互,使其能够在推理过程中实时获取和处理外部信息,从而更高效地解决复杂问题。
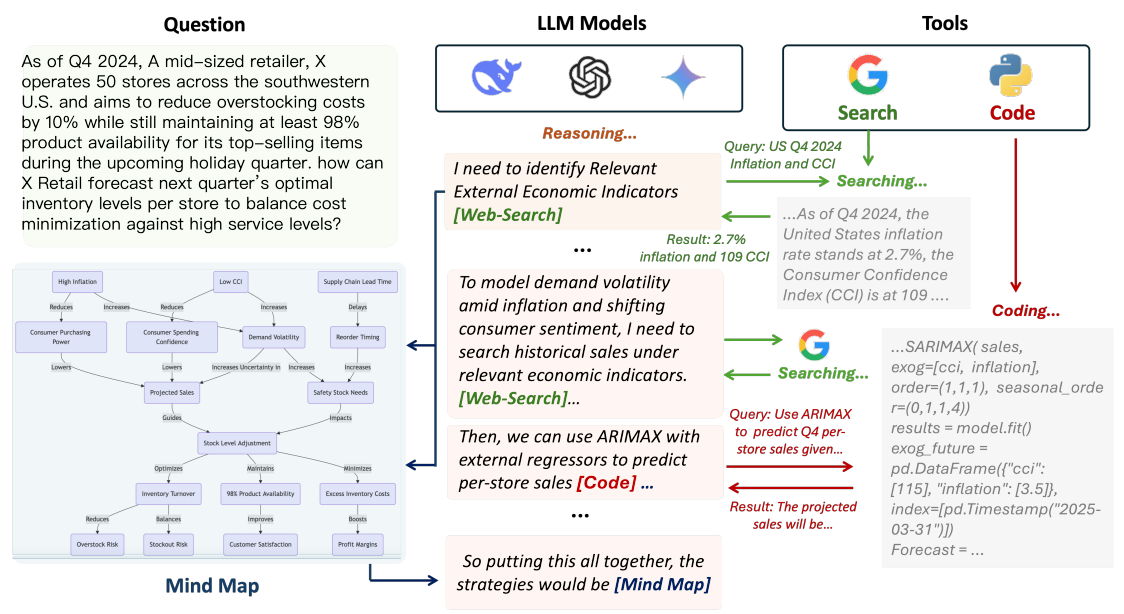
R1 开源后(特别是支持显示思考过程),AI 搜索类产品突然就都支持了深度推理 AI 搜索功能(但实际上因为 R1 模型还不支持 Function Call,这类功能实际上依托 RAG,让推理过程收敛在检索的这些信息上下文内),当然之前 Kimi 探索版的「深度推理」则主要围绕在识别用户查询意图方面的「深度拆解」,这篇论文思路是将外部工具使用动态的融入到推理轨迹中,OpenAI Deep research 的路子类似。
DeepRAG 是一个带推理的 RAG 框架(思路同上),旨在解决大语言模型(LLMs)在推理过程中存在的事实幻觉问题。该框架将推理过程建模为马尔可夫决策过程(MDP),使 AI 能够按需思考,动态决定是否需要外部检索。DeepRAG 通过检索叙事和原子决策两个组件实现智能检索。检索叙事通过构建推理链条,确保每个子问题的提出都基于前序检索结果。原子决策则通过 MDP 在每个推理节点上决定是否启动检索,减少了 47% 的不必要检索,将答案准确率提高了 21.99%。
工程
Canva 如何使用图像相似性搜索来替换设计中的图片?:Canva 使用图像搜索来替换设计中的图片的过程主要包括以下几个步骤:
定义图像相似性层次:首先,明确了图像相似性的层级,包括主体、颜色、背景和情感等因素。
确定系统要求:确立了一系列要求,包括能够推荐最相似的图片、处理超过 1500 万张图片、与媒体库同步更新、过滤特定元数据字段(如纵横比),以及确保系统的可重用性和可扩展性。
评估现有解决方案:评估了现有的内部解决方案,如推荐引擎、周期性哈希系统、文本到图像搜索,以及人工智能生成的图像替换,最终确定需要构建一个基于图像相似性的图像到图像搜索系统。-
选择和实验图像嵌入模型:选择了五种高性能的机器学习模型(DINOv2、CLIP、ViTMAE、DreamSim 和 CaiT)进行实验,通过提取图像嵌入向量并使用 Faiss 库构建内存中的向量数据库,对模型性能进行了比较。最终选择了 DINOv2 作为最适合的模型。
选择向量数据库方法:选择了外部向量数据库而不是内存方法,以便更经济地处理大量图片和实时更新。-
实施和集成:将图像相似性搜索系统集成到 Canva 的模板助手中,使得设计师可以快速替换图片。
评估和未来改进:系统在照片搜索上表现良好,但在图形替换上仍有改进空间。未来的工作将集中在对包含文本、符号或非现实主义图像的处理上。
通过这些步骤,Canva 能够自动化地替换设计中的图片,提升设计质量和工作效率。
DeepSeek 火爆现象背后企业可以得到什么实质提升?文章探讨了 DeepSeek 为企业带来的好处。首先是信息获取方式的大提升,通过 DeepSeek-R1 的 “深度思考” 和 “联网搜索” 能力,可以将传统的 “检索 — 阅读 — 摘要 — 汇总” 过程简化为 “提问 — 获得答案”。其次,DeepSeek 的蒸馏模型提升了性能,使得企业在私有化部署时可以选择更小、更强的模型。数据安全是企业部署私有化模型的主要原因之一。文章强调了 AI 应用的构成,即 “能力 + 数据 + 逻辑”,以及企业如何更进一步拥抱 AI。企业需要从业务逻辑出发,鼓励员工使用 AI,注重数据积累和知识管理,以促进 AI 转型升级。
前 Facebook CTO 对智能体通信协议的看法:Bret Taylor 认为,尽管有一些尝试,但目前设计一个成熟的 AI 代理(Agent)通信协议还为时尚早。他认为,由于大语言模型能够使用人类设计的接口,因此 AI 代理可能会继续使用英语等人类语言作为通信手段。这种方法有其优势,因为它允许人类和 AI 代理之间的无缝交流。这种方法可能会延续一段时间,直到出现特定的机器协议需求。
教你本地复现 Deep Research:DeepSeek R1+ LangChain+Milvus:OpenAI 新推出的 Deep Research 功能,它能够自动查找并分析优质在线资源,为用户生成专业级别的综合报告,节省大量时间。作为替代方案,本文提出了使用 DeepSeek R1、LangChain 和 Milvus 的本地部署解决方案,并详细介绍了其四个步骤:定义 / 优化问题、搜索、分析和生成。这个方案的优势在于成本低、灵活性高、安全性强,并且可以适应中文任务。最后,文章展示了使用这个方案生成的关于《辛普森一家》变化的报告示例。
Zyphra 开源 Zonos-v0.1:Zyphra 发布的 Zonos-v0.1 是领先的开放权重文本到语音模型,提供与顶级 TTS 提供商相当甚至更出色的表现力和质量。它能够在给定说话人嵌入或音频前缀的情况下,从文本提示生成高度自然化的语音。只需 5 到 30 秒的语音,Zonos 就能实现高保真度的声音克隆。它还允许根据说话速度、音调变化、音频质量和悲伤、恐惧、愤怒、快乐和喜悦等情绪进行条件化。该模型以 44kHz 的采样率原生输出语音。
产品
- 硅基流动上线 DeepSeek R1 & V3 企业级服务,同时也上线了针对个人开发者更稳定 Pro 版 DeepSeek R1 & V3。
- 智谱和三星基于 Agentic GLM 展开合作,将 Agent 体验带到三星最新手 Galaxy S25 系列上
- Codeium Team 发布了 Windsurf Wave 3:旨在提升 Windsurf 编辑器的整体体验,包括对 Model Context Protocol (MCP) 的支持、增强的文本编辑器预测功能、自动化终端命令执行、图片拖放功能以及为付费用户提供的自定义应用图标等新特性。
市场
- 2024 中国开源开发者报告:这份报告由开源中国 OSCHINA、Gitee 与 Gitee AI 联合出品,聚焦 AI 大模型领域,对过去一年的技术演进动态、技术趋势、以及开源开发者生态数据进行多方位的总结和梳理。
- Apple 智能或即将在国内上线,苹果举行开发者活动:苹果公司于 2025 年 1 月 10 日在中国成立了名为苹果技术开发(上海)有限公司的新公司,注册资本 3500 万美元,这一布局让人联想到苹果可能通过这家公司加速推动 AI 服务在国内的落地。此外,苹果计划于 3 月 25 日在上海举行「深入探索 Apple 智能和机器学习」开发者线上活动,这可能暗示了 Apple Intelligence 也会在 3 月 25 日左右正式上线国内。
- Anthropic 发布了 AI 经济指数报告:Anthropic 公布了一份报告,该报告基于与其 AI 模型 Claude 的 400 万次对话,总结了自动化工作的未来趋势。
- OpenAI 宣布将 o3 统一合入 GPT-5:OpenAI 取消了其下一主要 AI 模型 o3 的发布计划,转而推出一个被称为 GPT-5 的统一新一代模型,会整合进 o3 。
- Claude 混合推理模型可能在未来几周内发布:The Information 报道 Anthropic 将在未来几周内发布 Claude 混合推理模型,提供滑动缩放功能,当设置为 0 时,该功能将恢复为非推理模式。据说该模型在某些编程基准测试中优于 o3-mini,并且在典型的编程任务中表现出色。
观点
S 型智能增长曲线:从 DeepSeek R1 看 Scaling Law 的未来:Scaling Law 是推动大模型快速发展的关键因素,并且只要 Scaling Law 成立,大模型的未来发展前景乐观。Deepseek R1 因复现并开源了大模型 Post-Training 和 Inference 两个阶段的 Scaling Law 而受到关注。文章讨论了关于 Scaling Law 曲线是否可以无限增长以及三种 Scaling Law(Pre-train、RL、Test Time)组合后的形态等问题。
解构 DeepSeek-R1:一场 AI 效率革命背后的技术突破:这篇关于 DeepSeek-R1 的解读,全面准确,质量特别高。
DeepSeek 选择了开源的道路,这一决定具有深远的战略意义,使得全球的研究者能够快速建立起相关能力,与 OpenAI 的闭源策略形成对比。
从强化学习的视角(四个核心要素,策略初始化、奖励函数设计、搜索策略、学习过程)解读 DeepSeek-R1 的推理模型架构技术创新,特别是指出 R1 仍然存在一些需要改进的地方,在通用任务上的推理效果还不够理想,强化学习的泛化能力仍需进一步研究。此外,推理时间扩展性与训练规模、数据规模密切相关,需要确保足够的训练步骤和数据来保证模型性能。
DeepSeek-R1 的系统软件优化,特别是在负载均衡、通信优化、内存管理和计算优化方面的创新,使得庞大模型的训练成本大幅降低。
DeepSeek 在软件硬件协同的基础上绕过了 CUDA,直接深入到 PTX 层面,这种底层优化策略为提升硬件效率和降低成本提供了新的思路。
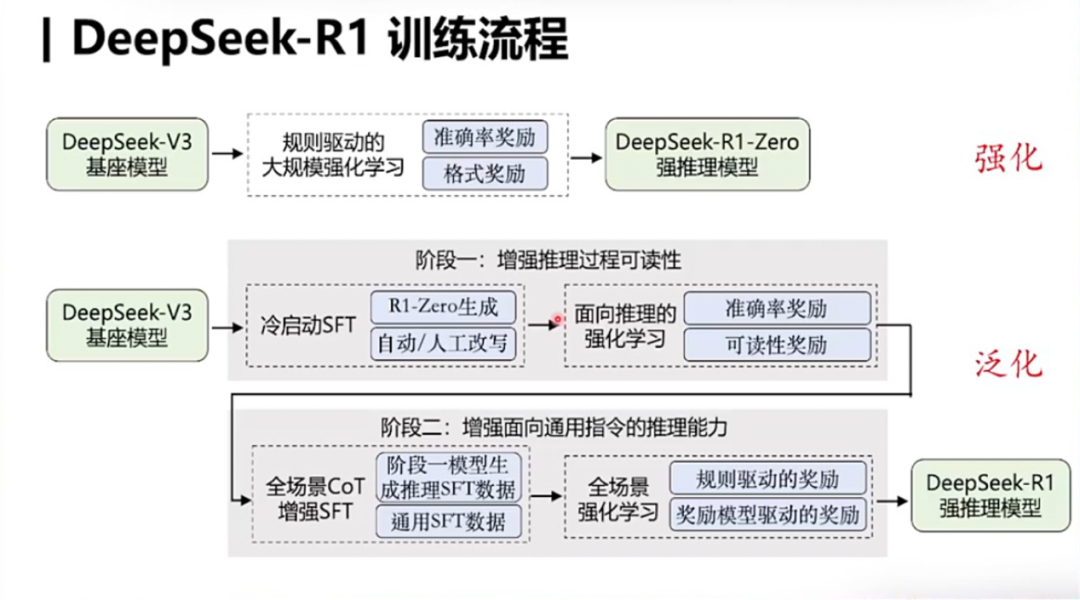
Vol.39:从 DeepSeek R1 看 Scaling Law 的未来
