Vol.40:Grok3 是否意味着预训练阶段 Scaling Law 已失效?
大家好!Weekly Gradient 第 40 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
多样性增强了 LLM 在 RAG 和长上下文任务中的表现:大语言模型(LLMs)的快速发展凸显了上下文窗口限制的挑战,这主要是由于自注意力机制的二次时间复杂度((O(N^2)),其中 (N) 表示上下文窗口长度)。这一限制影响了问答(Q&A)中的检索增强生成(RAG)和长上下文摘要等任务。一种常见的方法是选择与查询最相似的内容;然而,这通常会导致冗余,并排除多样化的相关信息。基于最大边缘相关性(MMR)和最远点采样(FPS)的原则,本论文在内容选择过程中引入了多样性。研究发现,在基于 LLM 的问答和摘要之前,将多样性融入内容选择,可以显著提高相关句子或块的召回率。这些结果强调了在未来的 LLM 应用中保持多样性的重要性,以进一步提升摘要和问答的效果。
KET-RAG:一个基于 Graph-RAG 的高效多粒度索引框架:Graph-RAG 通过构建知识图谱提升 LLM 问答系统检索效果,尤其适用于需要多跳推理的生物医学、法律和政治科学领域。现有 Graph-RAG 系统基于文本块相关性构建 KNN 图,但无法捕捉实体关系,导致质量不佳。本文提出 KET-RAG 多粒度索引框架。它首先识别关键文本块并构建知识图谱骨架,然后构建文本-关键词二分图作为轻量替代。检索时,它结合骨架的局部搜索和二分图的模拟搜索提升质量。在两个真实数据集上,KET-RAG 在索引成本、检索效果和生成质量上均优于其他方案。与 Graph-RAG 相比,它检索质量相当或更优,索引成本降低超一个数量级,生成质量提升最高 32.4%,索引成本降低约 20%。
KET-RAG 相比 GraphRAG 的改进点:
- 首先是 KNN(K-nearest-neighbor) 图谱的”近视眼“:基于 KNN 图谱的 RAG 通过构建一个 K-最近邻(KNN)图谱来增强文本检索能力,从而提高生成答案的质量。基于文本块相似度构建的最近邻图谱,就像近视患者只能看清眼前物体,虽然构建成本低(与普通文本检索相当),但无法捕捉文本内部的实体关系。当用户查询”阿司匹林与布洛芬的相互作用机制”时,相关知识点可能分散在不同研究报告中,简单的文本块检索难以实现有效关联。
- 其次是知识图谱的”富贵病“。微软等公司采用的三元组知识图谱(KG-RAG)虽然效果优异,但需要调用大模型逐条提取实体关系。以处理 5GB 法律案例为例,仅 API 调用费用就高达 3.3 万美元,这还没有算上工程师调试 prompt 的人力成本。这种”土豪玩法”让中小型企业望而却步。
如何让大语言模型在连续的潜在空间中进行推理?:这篇论文提出了一种名为 Coconut(Chain of Continuous Thought)的新范式,旨在让大语言模型(LLMs)在连续的潜在空间而非语言空间中进行推理,以突破传统链式思维(CoT)的局限性。
语言空间的局限性
- 现有 LLMs(如 CoT)通过自然语言生成中间推理步骤,但语言空间的 token 生成存在两个问题:
- 冗余性:多数 token 仅用于文本连贯性,而非核心推理;
- 计算资源分配不均:关键推理步骤(如复杂规划)需要更多计算,但模型对所有 token 分配相同计算量。
- 神经科学研究表明,人类推理时语言网络并不活跃,暗示语言可能并非最优推理载体。
- 现有 LLMs(如 CoT)通过自然语言生成中间推理步骤,但语言空间的 token 生成存在两个问题:
潜在空间推理的优势
- 通过将模型的最后一个隐藏状态(称为“连续思维”)直接作为下一阶段的输入嵌入,模型可在连续空间中自由推理,无需受限于语言 token 的生成。
- 连续思维支持并行探索多条推理路径(类似广度优先搜索),而非 CoT 的单一确定性路径,从而提升复杂规划任务的性能。
方法:Coconut 的核心设计
架构与流程
- 模式切换:模型在“语言模式”和“潜在模式”间切换。潜在模式下,隐藏状态直接作为输入嵌入,无需解码为语言 token。
- 特殊标记:使用
<bot>和<eot>标记潜在推理的起始与终止。 - 训练策略:多阶段课程学习(Multi-stage Curriculum)逐步用连续思维替换语言推理步骤(例如,第一阶段训练完整 CoT,后续阶段逐步移除语言步骤并插入连续思维)。
关键技术细节
- 梯度传播:连续思维完全可微分,支持端到端优化。
- 推理控制:通过固定潜在思维长度或训练终止分类器,简化推理过程。
实验结果与发现
- 任务与数据集
- 数学推理(GSM8k):验证连续思维的链式推理能力。
- 逻辑推理(ProntoQA、ProsQA):测试复杂规划与回溯能力,其中 ProsQA 通过随机生成 DAG 结构增加推理难度。
- 主要结果
- 性能提升:Coconut 在逻辑推理任务(ProntoQA、ProsQA)上显著优于 CoT,数学推理(GSM8k)表现接近或超过现有方法(如 iCoT)。
- 效率优势:生成 token 数大幅减少(例如,ProsQA 任务中 CoT 生成 49.4 token,Coconut 仅需 14.2 token)。
- 关键对比:
- Coconut vs. CoT:在需要复杂规划的 ProsQA 任务中,Coconut 准确率 97.0% vs. CoT 的 77.5%。
- Coconut vs. 填充 token 方法:连续思维优于单纯插入
<pause>等标记,因其支持依赖前序步骤的链式推理。
QA-Expand:多问题问答生成,用于增强信息检索中的查询扩展:查询扩展在信息检索领域被广泛应用,通过为查询添加额外的上下文信息来提升搜索效果。尽管基于 LLM 的方法能够通过多个提示生成伪相关内容和扩展项,但这些方法往往产生重复且范围狭窄的扩展,缺乏多样化的背景信息,难以检索到所有相关结果。本文提出了一种新颖且有效的查询扩展框架——QA-Expand。该框架首先从初始查询生成多个相关问题,随后为这些问题生成对应的伪答案作为替代文档。通过反馈模型进一步优化和筛选这些答案,确保仅保留最有价值的补充信息。在 BEIR 和 TREC 等基准测试中的大量实验证明,与现有最优方法相比,QA-Expand 将检索性能提升了高达 13%,为应对现代检索挑战提供了有力的解决方案。
工程
DeepSeek 官方发布 R1 模型推荐设置,以及联网搜索和文件上传功能的提示词
# 以下内容是基于用户发送的消息的搜索结果:
{search_results}
在我给你的搜索结果中,每个结果都是[webpage X begin]…[webpage X end]格式的,X 代表每篇文章的数字索引。请在适当的情况下在句子末尾引用上下文。请按照引用编号[citation:X]的格式在答案中对应部分引用上下文。如果一句话源自多个上下文,请列出所有相关的引用编号,例如[citation:3][citation:5],切记不要将引用集中在最后返回引用编号,而是在答案对应部分列出。
在回答时,请注意以下几点:- 今天是{cur_date}。
- 并非搜索结果的所有内容都与用户的问题密切相关,你需要结合问题,对搜索结果进行甄别、筛选。
- 对于列举类的问题(如列举所有航班信息),尽量将答案控制在 10 个要点以内,并告诉用户可以查看搜索来源、获得完整信息。优先提供信息完整、最相关的列举项;如非必要,不要主动告诉用户搜索结果未提供的内容。
- 对于创作类的问题(如写论文),请务必在正文的段落中引用对应的参考编号,例如[citation:3][citation:5],不能只在文章末尾引用。你需要解读并概括用户的题目要求,选择合适的格式,充分利用搜索结果并抽取重要信息,生成符合用户要求、极具思想深度、富有创造力与专业性的答案。你的创作篇幅需要尽可能延长,对于每一个要点的论述要推测用户的意图,给出尽可能多角度的回答要点,且务必信息量大、论述详尽。
- 如果回答很长,请尽量结构化、分段落总结。如果需要分点作答,尽量控制在 5 个点以内,并合并相关的内容。
- 对于客观类的问答,如果问题的答案非常简短,可以适当补充一到两句相关信息,以丰富内容。
- 你需要根据用户要求和回答内容选择合适、美观的回答格式,确保可读性强。
- 你的回答应该综合多个相关网页来回答,不能重复引用一个网页。
- 除非用户要求,否则你回答的语言需要和用户提问的语言保持一致。
# 用户消息为:
{question}
阶跃星辰发布两款开源多模态模型:Step-Video-T2V 和 Step-Audio:Step-Video-T2V 和 Step-Audio:Step-Video-T2V 模型具有 300 亿参数量,能生成高质量的 540P 分辨率视频,采用了 DiT 模型和 Flow Matching 训练方法,实现了高效的视频 VAE 压缩和文本编码器处理,以及级联训练策略,包括 T2I、T2VI 预训练、SFT 和 DPO,在视频生成质量评测方面表现出色。Step-Audio 模型则是行业内首款产品级的开源语音交互模型,能够生成多样化的语音表达,具备高效合成数据链路、精细语音控制和扩展工具调用等特点,通过大规模合成数据训练,支持 RAP 和哼唱等多种语音生成方式。
相关模型部署链接、体验入口、技术报告链接
PURE-RL 在法律任务上面的实践:本文介绍了 PURE-RL (即在完全不需要做 supervised fine-tuning(SFT)微调的情况下,验证了在法律领域上是否能带来提升)在法律任务上的实践,通过强化学习算法提升了模型在法律领域的推理能力,特别是在罪名预测、相关条款预测、刑期预测和判决结果评估等任务上的表现。
这篇实践文章很不错,推理模型在更多领域的应用探索,在实际业务落地中,如外呼实时润色场景,需要考虑模型响应时间和思维链长度,可能需要通过 RL 算法引入长度惩罚的权重去学习更精简的思维链。
Scale AI 出品的 EnigmaEval(非常难的多模态谜题)和 Cambridge 的 ZeroBench(100 个手动策划的多步骤视觉推理问题)两个评估测试集,当前最好的模型得分也为 0。
如何使用 DeepSeek R1 和 Firecrawl 构建 RAG 增强的智能代码文档助手:本文详细介绍如何使用 DeepSeek R1 模型和 RAG 技术构建智能代码文档助手。该助手利用 Firecrawl 爬取文档网站内容,Nomic Embeddings 实现语义搜索,DeepSeek R1 生成准确回答。重点介绍了包括 Firecrawl、DeepSeek R1、Nomic Embeddings、ChromaDB、Streamlit 和 LangChain 在内的技术栈,并详细阐述了各组件的实现和作用。该方法使用户能够更高效地浏览技术文档并解决问题。本地执行还带来了保护隐私、减少延迟的额外优势。
FoloUp:一个开源平台,公司可以使用它进行基于 AI 的招聘面试,关键特性:
- 面试创建:从任何职位描述中即时生成定制化面试问题。
- 一键分享:几秒钟内生成并分享独特的面试链接给候选人。
- AI 语音面试:让 AI 进行自然、对话式的面试,适应候选人的回答。
- 智能分析:为每个面试回答提供详细见解和评分。
- 综合仪表盘:跟踪所有候选人的表现和整体统计数据。
产品
Resend 团队宣布推出 new.email:它允许用户使用自然语言创建美观、响应式且跨平台的电子邮件。
- 自然语言生成:用户无需编写代码,只需使用自然语言描述,即可生成电子邮件模板。
- 面向所有人:不仅仅是开发人员,市场营销、产品或设计团队也能轻松使用。
- 一致性与美观:确保电子邮件在外观和风格上与产品保持一致,提升品牌形象。
- 响应式和跨平台:自动适配不同设备和邮件客户端,提供最佳阅读体验。
- 基于 LLM:利用大型语言模型技术,结合 Resend 在邮件发送方面的经验,实现智能化生成。
- 高质量组件库:训练 LLM 生成基于包含 54 个高质量电子邮件组件的库。
知乎直答接入 DeepSeek-R1 模型:知乎宣布旗下 AI 搜索产品知乎直答接入“满血版”DeepSeek-R1,在社区优质语料、专业知识库基础之上,全面升级推理能力,带来全新 AI 搜索体验。此外,知乎直答还同步上线了“知识库”功能,助力知识工作者效率提升。
AI 搜索问答(即使现在接入了推理模型)的幻觉包括:
- 大模型自己胡说八道
- 搜索出来的内容胡说八道但无法判定而直接引用
- 模型的知识和搜索到的信息冲突时无法判断谁正确,随机抽卡到胡说八道的内容
知乎虽然越来越烂,但它的内容质量依然是中文互联网最高的,可以有效降低幻觉 2 和 3,提升体验。
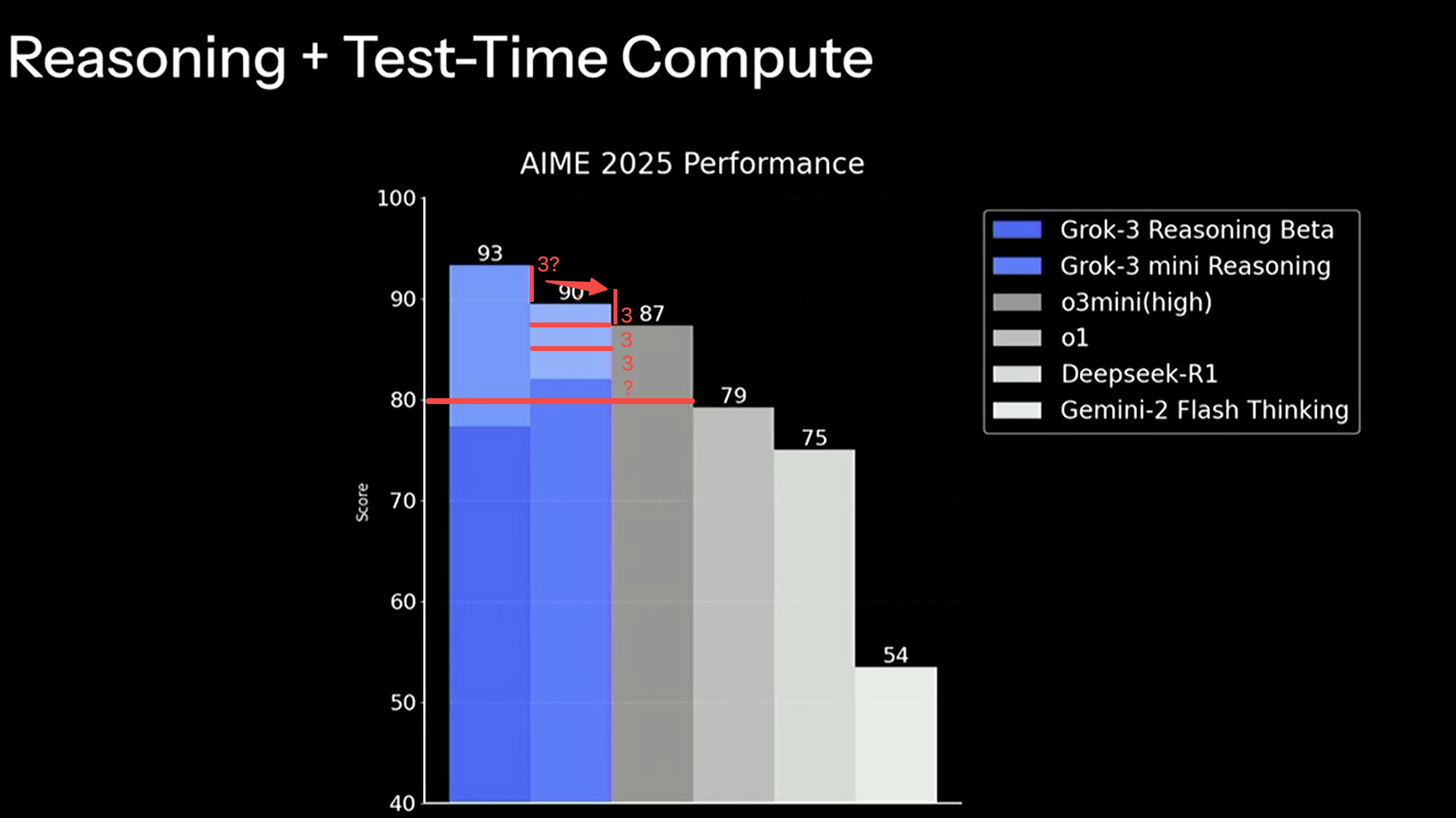
xAI 正式发布 Grok 3 模型:吹了半年的 10w 卡集群训练出这坨东西结果还不是 SOTA,好消息是验证了堆算力和数据做更大 size 基础模型这条路真是走到头了,发布会上还做了一张带有欺骗性的图进行宣传误导(1. 纵坐标作假 2. 柱状图的配色毫无辨识度,深蓝色是真实实际能力,浅蓝色是增加了比其他模型更多思考时间后的结果 3.纵坐标不是从 0 开始,显得优势明显),就是 o1 到 o3-mini(high)之间的水平。当然测评结果只代表一部分,实际使用体验反正 Grok 2 其实很一般,Grok 3 真实能力如何,擅长哪些任务需要一段时间才能确定。
Jina AI 推出 DeepSearch API 服务:它通过搜索、阅读和多轮推理来解答问题,尤其适合处理需要迭代推理、世界知识或最新信息的复杂问题。
Perplexity 推出了 Deep Research 功能,旨在通过自动化深度研究和分析,节省用户时间,并提供全面报告,适用于多种复杂领域,包括金融、市场营销、技术、时事事件、健康、传记和旅行规划。专业版订阅用户可以无限制使用,非订阅用户每天可以使用有限的次数。
市场
-

微信搜索接入 DeepSeek-R1 目前处于灰度测试阶段:微信搜一搜目前正在灰度测试“AI 搜索”功能,部分用户进入微信搜索页面后,可点击由 DeepSeek-R1 提供的“深度思考”选项。
硅基流动完成新一轮亿元人民币融资:针对企业客户,硅基流动提供了以下四种服务模式
专属实例:为企业客户提供专属的计算资源实例,确保他们在使用 AI 模型时能够获得稳定且高效的性能。
算力纳管:提供算力管理服务,帮助企业高效管理和调度其在硅基流动平台上的算力资源,以优化成本和性能。
私有版 MaaS(Model as a Service):为企业客户提供私有化的模型服务,确保数据安全和隐私保护,同时允许客户根据自己的需求定制和部署 AI 模型。
基于华为昇腾 910 系列 NPU 的一体机:提供集成了华为昇腾 910 系列 NPU 的一体机解决方案,这种解决方案能够提供高性能的 AI 推理能力,适用于需要在本地环境中进行大规模 AI 推理处理的企业客户。
YC 通过精选创始人、数据驱动决策和独特培育体系成功孵化了众多企业,并转向 B2B 和 AI 领域以追求更高回报。:Y Combinator (YC) 作为全球领先的创业加速器,本文通过对 4939 家公司的数据分析,揭示了其高成功率的核心因素:严格的创始人筛选机制、数据驱动的决策方式以及独特的创业培育体系。YC 已经从消费级市场转向 B2B 投资,并重点关注 AI 领域,尤其是在工程、产品、设计工具、基础设施和销售自动化等子赛道。
数据显示,YC 支持的公司中约有 4.5% 成为了独角兽(与其他风险投资支持的种子阶段初创企业的 2.5% 成功率相比),约有 45% 的公司进一步筹集了系列 A 轮资金(比平均水平的 33% 要高)。YC 已经资助了超过 90 家亿美元级别的公司,包括 Stripe、Airbnb、Coinbase 和 Reddit 等。
分析结果揭示了 YC 的几个关键趋势和成功因素:
- YC 从主要投资消费类公司转向了以 B2B 公司为主的投资策略。
- 创始人预计人工智能(尤其是 B2B AI)将是下一个大趋势。
- 单创办人在 YC 中的比例正在下降,显示出他们在竞争中的劣势。
- 迄今为止,成功主要来自美国创立的公司,美国公司占到了超过 70%,并且几乎所有的回报都来自美国。
- YC 公司的持续性明显高于平均水平,超过 50% 的公司在 10 年后仍在运营。
- YC 公司的成功率高于平均水平,约 45% 的公司能够筹集到系列 A 轮资金,4% 到 5% 的公司成为独角兽,10% 的公司实现了退出。
- YC 的回报也遵循 VC 的幂律分布,前四家公司(Airbnb、Coinbase、Reddit 和 Instacart)占到了超过 85% 的回报。
- YC 公司的投资者包括顶尖的风险投资,其中一些投资者已经对数百家 YC 公司进行了投资。
Product Hunt 2024 年的金喵奖榜单:Product Hunt 的 Golden Kitty Awards(金喵奖)是全球新产品评选的盛典,旨在表彰当年最具创新性、影响力和用户欢迎度的产品。2024 年的奖项涵盖了开发者工具、设计工具、无代码产品、数据产品、AI 模型、AI 硬件、音频、AI copilot 等多个领域,展现了全领域 AI 化和用户体验革新的两大核心趋势。
在开发者工具类别中,TOP1 的 Supabase 是一个开源后端平台,提供实时数据库和完整后端服务,解决了传统后端开发的痛点。TOP2 的 Cursor 是一个集成 AI 功能的代码编辑器,通过 AI 技术提高编码效率。TOP3 的 bolt.new 提供了 AI 驱动的全栈 Web 应用开发和部署平台,简化了开发和部署流程。
设计工具类别中,TOP1 的 Figma 是一个协作式界面设计工具,提供了实时多人协作解决方案。TOP2 的 Mobbin 是一个 UI & UX 设计参考库,提供了大量的设计模式和案例研究。TOP3 的 Layers 是一个面向设计师的社区平台,为设计师提供了分享作品和建立联系的空间。
在无代码产品类别中,TOP1 的 Notion Sites 提供了一个一体化的工作空间,整合了多种工具。TOP2 的 HeyForm 3.0 是一个开源表单构建器。TOP3 的 Wegic 是一个基于 AI 的网站设计、开发和管理平台。
数据与数据安全类别中,TOP1 的 Supabase AI Assistant 是一个集成在 Supabase 平台中的 AI 驱动工具,简化了数据库管理和开发流程。TOP2 的 Hex 是一个数据科学和分析工作空间,支持协作式数据分析。TOP3 的 Equals 是一个为现代团队打造的电子表格工具,提供了更强大的协作和数据分析能力。
开源类别中,TOP1 的 postgres.new 提供了智能数据库管理工具。TOP2 的 Meta Llama 3 。TOP3 的 Helicone AI 是一个为开发者提供的开源 LLM 可观测性平台。
AI 硬件类别中,TOP1 的 Oura Ring 4 是一款健康追踪智能戒指,提供精确的睡眠和活动数据。TOP2 的 Limitless AI 是一款创新的 AI 可穿戴设备和软件平台,旨在增强人类记忆和智能。TOP3 的 Friend 是一个 AI 穿戴设备,旨在通过技术手段缓解孤独感。
AI 音频类别中,TOP1 的 ElevenLabs 提供了先进的文本转语音和语音克隆 AI 平台。TOP2 的 Voicenotes 是一款智能 AI 笔记应用。TOP3 的 Vapi 提供了简化的语音机器人开发流程。
AI 模型类别中,TOP1 的 Claude 3 是一款注重可靠性、可解释性和可控性的 AI 助手。TOP2 的 GPT-4o 是 OpenAI 推出的多模态 AI 模型。TOP3 的 Llama 3 是 Meta 开源的大语言模型系列。
AI 视频类别中,TOP1 的 Sora 是 OpenAI 的文本转视频 AI 模型。TOP2 的 RunwayML 是一款 AI 驱动的创意工具,支持视频编辑和生成。TOP3 的 Google Veo 2 是一款视频生成模型,能够根据文本或图像创建逼真的视频片段。
AI Copilot 类别中,TOP1 的 Cursor 是一个集成 AI 功能的代码编辑器。TOP2 的 Replit Agent 是一个在线 IDE,提供了 AI 助手。TOP3 的 Supabase AI Assistant 是一个简化数据库管理和开发流程的工具。
金融科技类别中,TOP1 的 Mercury Personal 是一款为初创企业打造的在线银行平台。TOP2 的 Central 是一款为初创企业提供自动化薪资和合规服务的 HR 平台。TOP3 的 Gilion 是一款利用数据预测未来并提供融资的增长平台。
移动应用类别中,TOP1 的 Remy AI 是一款 AI 驱动的睡眠健康助手。TOP2 的 Earth.fm App 是一款提供自然声景的非营利应用。TOP3 的 Arc Search 是一款快速、无广告的移动浏览器。
Web3 & Crypto 类别中,TOP1 的 Burner 是一款低成本的加密货币硬件钱包。TOP2 的 DeFi Lens 利用生成式 AI 提供高级交易体验。TOP3 的 Sharpe Labs 是一款 AI 驱动的加密货币超级应用。
个人生产力类别中,TOP1 的 Raycast Notes 是一款强大的 macOS 效率启动器。TOP2 的 Notion Calendar 提供了笔记、文档、项目管理和数据库等功能。TOP3 的 Findr 是一款旨在简化招聘流程的 AI 驱动平台。
社区与社交类别中,TOP1 的 Unicorns Club 连接初创企业和投资者。TOP2 的 Airchat 是一款社交语音对讲应用。TOP3 的 Mozi 是一款私密社交应用。
Bootstrapped & Small Teams 类别中,TOP1 的 Voicenotes 是一款智能 AI 笔记应用。TOP2 的 Horse 是一款通过侧边栏组织网页、任务和项目的浏览器扩展工具。TOP3 的 WrapFast 提供了 SwiftUI 样板代码,帮助开发者快速构建 iOS 应用。
观点
W3C WebAgents 社区邀请智能体通信协议 ANP 创始人分享的演讲
W3C WebAgents 社区专注于设计基于 Web 的多智能体系统(MAS),旨在构建一种与 Web 架构相一致的新型 MAS,继承 Web 的全球性、开放性和持久性等特性,同时确保系统的透明性和可追溯性,以便获得人们的广泛接受。该社区特别关注使用链接数据和语义 Web 标准,打造能够促进人、人工智能、设备、数字服务等异构实体统一互动的超媒体结构(hMAS)。社区地址:https://www.w3.org/community/webagents/
-
- 推理模型的演进:DeepSeek R1-zero 模型展示了不需要监督微调的可能性,推理可能不需要依赖人类可理解的文本,而是可以在潜空间中进行,以提高效率和鲁棒性。
- Test-Time 记忆范式与外部知识增强:未来模型需要更高效的推理方式,包括引入遗忘与压缩机制以及增强外部知识检索,以提高推理效率和定制化能力。
- 推理模型与基础模型的融合:未来模型将深度融合推理模块与基础语言模型,实现动态路由机制和算力异构分配,以在准确性和效率之间实现最佳平衡。
Grok 3 是否意味着大力出奇迹的大模型法则仍然成立?:作者分析了 Scaling Law 的天花板问题,Test Time Scaling 的天花板可能依赖于 RL 阶段的 Scaling 能力,而 RL 阶段的天花板可能依赖于预训练阶段的 Scaling,现阶段提升模型效果性价比从高到低的 Scaling 方法排序:Test time Scaling Law > RL Scaling Law > 预训练阶段 Scaling Law(数据不足时)。
Vol.40:Grok3 是否意味着预训练阶段 Scaling Law 已失效?
