Vol.43 什么样的 Agent 会在 2025 年脱颖而出?
大家好!Weekly Gradient 第 43 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
LaRA: RAG与长上下文LLM到底哪个效果更好:LaRA 基准测试是为了系统地评估 RAG 技术与长文本语言模型(LC LLMs)的效果而设计。研究团队通过对七种开源和四种闭源大型语言模型(LLMs)进行系统性评估,发现 RAG 与 LC 之间的最优选择取决于多重因素,包括模型参数规模、长文本处理能力、上下文长度、任务类型及检索片段特征等。研究者出,尽管 LLMs 在长文本处理能力上取得了进展,但仍存在计算开销大、事实准确性降低、幻觉产生概率增加等问题。LaRA 基准测试选取了三类代表性文本作为上下文材料,并设计了四种核心任务来评估 RAG 和 LC LLMs 在不同能力维度上的表现。实验结果显示,RAG 对能力较弱的模型提供了更显著的性能提升,尤其是在长上下文长度条件下。此外,研究还分析了不同文本类型对模型性能的影响,以及检索信息长度对 RAG 性能的影响。最终得出结论,当前 LC LLMs 在处理超长文本时并未展现出对 RAG 的全面碾压性优势,两者在不同应用场景中呈现出显著的互补性特征。
CodeAct:可执行代码操作激发更好的 LLM 代理:CodeAct 通过将代码执行能力集成到 LLM 中,使得模型能够在理解和生成自然语言的同时,执行相应的代码动作,这种集成不仅提高了任务的执行效率,还扩展了 LLM 的应用范围。此外,实验可能还展示了 CodeAct 在安全性方面的考量和解决方案,如何通过沙盒环境或代码审查机制来防止恶意代码的执行。(这篇论文是 Manus 的技术实现灵感来源之一,全是安全业务机会。一方面通过提示词注入可以带来常规的代码安全问题;一方面执行过程中代理自动下载依赖软件,也可以针对性做软件供应链投毒。)
代码生成能力:CodeAct利用LLM的自然语言理解和生成能力,进一步训练模型学会生成可执行的Python代码。这意味着LLM不仅能够理解和回答问题,还能够生成实际执行任务的代码。
任务执行:生成的Python代码可以直接执行,这使得LLM能够实际执行任务,而不仅仅是提供解务的解决方案。例如,LLM可以编写脚本来自动化数据处理、执行数学计算或者与外部API进行交互。
环境交互:通过执行代码,LLM能够与计算机环境进行交互,如读写文件、操作数据库或者控制外部程序。这种交互能力大大扩展了LLM的应用范围。
复杂问题解决:CodeAct使得LLM能够处理更复杂的问题,这些问题可能需要多步骤的逻辑和理和数据操作。通过代码执行,LLM可以更有效地解决这些问题。
学习和适应:CodeAct可以让LLM通过编写和执行代码来学习新的任务和概念,从而提高其适应新环境和问题的能力。
安全性和控制:虽然CodeAct提供了强大的功能,但也引入了安全性问题。因此,需要实施适当的安全措施来确保代码的执行是安全的,并且在预定的范围内。
ViDoRAG:通过动态迭代推理 Agent 进行可视化文档检索增强生成:ViDoRAG 是一个专为视觉文档复杂推理设计的多智能体检索增强生成(RAG)框架。它采用基于高斯混合模型(GMM)的混合策略,通过动态调整检索结果分布,实现高效多模态检索。ViDoRAG 的代码和数据集已在 GitHub 上开源,地址为:https://github.com/Alibaba-NLP/ViDoRAG。
ViDoRAG通过利用动态迭代推理代理提升视觉文档检索增强生成性能:
多智能体框架:ViDoRAG引入了三种智能体:搜索智能体(Seeker Agent)、审查智能体(Inspector Agent)和回答智能体(Answer Agent)。这些智能体分别负责快速扫描文档并选择相关图像、对选中的图像进行详细审查并提供反馈、以及整合反馈生成最终答案。
迭代推理过程:智能体通过迭代的方式工作,逐步优化答案的生成过程。搜索智能体根据查询和审查代理的反馈缩小检索范围,审查智能体提供初步答案或反馈,回答智能体则生成最终答案。这种迭代方式减少了无关信息的干扰,提升了推理的鲁棒性。
动态调整检索结果:ViDoRAG采用基于高斯混合模型(GMM)的混合策略,动态调整检索结果分布。这种方法能够根据查询与文档集合的相似度分布自动确定最佳的检索数量,从而提高了检索的准确性和效率。
自适应学习:通过期望最大化(EM)算法,GMM模型能够估计每个模态的先验概率,动态调整K值,即检索结果的数量。这种自适应学习机制确保了检索过程的高效性,尤其是在处理大规模文档集合时。
时间效率与性能平衡:ViDoRAG的动态检索策略减少了不必要的计算开销,加速了生成过程。尽管多智能体系统的迭代性质可能会增加延迟,但生成答案的质量提升使得这种权衡非常有益。
Visual-RFT:视觉强化微调:一种有趣的尝试,对 DeepSeek-R1 模型在多模态领域应用的扩展。Visual-RFT 的核心在于利用 LVLMs 生成包含推理过程和最终答案的多个响应,并通过特定的可验证奖励函数进行策略优化。具体步骤包括任务输入、响应生成、奖励计算和策略优化。奖励函数的设计针对不同的视觉任务,如 IoU 奖励用于目标检测,分类准确率奖励用于分类任务。实验结果显示,Visual-RFT 在细粒度图像分类、少样本目标检测、推理定位以及开放词汇目标检测基准测试中表现出竞争力的性能和先进的泛化能力,比如在单样本细粒度图像分类中,准确率比基线提高了 24.3%,在少样本目标检测中,在 COCO 的两样本设置中超过了基线 21.9,在 LVIS 上超过了 15.4。Visual-RFT 代表了对 LVLMs 微调范式的一种转变,提供了一种数据高效、由奖励驱动的方法,增强了对特定领域任务的推理能力和适应性。开源地址:https://github.com/Liuziyu77/Visual-RFT
工程
如何使用 Cursor 和 Claude AI 工具高效地管理和维护大型项目:
设置Agent模式:启用Cursor的Agent模式(通常通过快捷键如
cmd + I),并选择Claude 3.7 sonnet或其他适合的AI模型。Agent模式允许Cursor持续调用AI以完成目标,包括搜索文件、查找上下文、运行测试和安装包等。编写AI文档:创建一个文档库,为AI详细说明最佳实践和常见任务,如编写测试、设置新的数据库模型和迁移、创建新的控制器等。这有助于AI更好地理解和遵循项目的特定要求。
启用Yolo模式:在Cursor的设置中启用Yolo模式,以便AI可以在不经常确认的情况下运行测试。这样可以加快开发速度,同时确保代码的质量。
让AI运行测试:指示Cursor运行测试,以便AI可以检测并修正在生成代码过程中可能出现的错误。虽然AI不是完美无误的,但通过这种测试循环,生成的代码质量会显著提高。
创建项目文件:为特定的项目任务创建详细的项目文件,这些文件应该引用相关的文档和最佳实践。项目文件有助于AI更准确地执行任务,并且可以用来检查项目规格的完整性。
使用Git作为检查点:利用Git的版本控制能力来管理代码变更,而不是依赖Cursor的内置检查点系统。这样可以更容易地重置工作空间并从不同的文档或最佳实践重新开始。
代码标准化:确保代码库遵循一致的编码标准和命名约定,以减少AI可能出现的混淆和错误。标准化代码有助于提高AI的成功率。
审查AI生成的代码:与对待初级工程师的工作一样,对AI生成的代码进行仔细审查,确保理解每一部分代码的作用。
使用Cursor规则和工具:在Cursor设置中添加规则,以便自动包含必要的文档。利用Cursor Tools等工具来提高AI的性能和效率。
重构、文档和搜索:除了代码生成,还可以利用Cursor和Claude进行代码重构、编写文档以及搜索复杂的代码库部分,以提高代码的可维护性和可知性。
谷歌发布新的文本嵌入模型 gemini-embedding-exp-03-07:新模型在 Massive Text Embedding Benchmark (MTEB) 多语言排行榜上取得了最高的排名,超越了之前的最先进的模型(text-embedding-004),并且带来了新特性,如更长的输入token长度。该模型在多个领域展现出了卓越的泛化能力,包括金融、科学、法律、搜索等,无需对特定任务进行微调。Gemini 嵌入模型支持高达 8K 的输入令牌限制,输出维度为 3K 维,并且支持 Matryoshka Representation Learning (MRL),允许根据存储成本的需求调整维度。此外,该模型扩展了语言支持,支持超过 100 种语言,并且是一个统一的模型,超越了之前的多语言、英语 Only 以及专门针对代码的模型。
《MCP:昙花一现还是未来标准?》:Harrison Chase(LangChain CEO)和 Nuno Campos(LangGraph Lead),就 MCP 的实用性和潜力进行了激烈讨论。
- Harrison 认为 MCP 对于给不可控代理提供工具访问是有用的,尤其是对于非开发者来说。
- Harrison 用 Claude Desktop、Cursor 和 Windsurf 为例,说明了如果想给这些代理增加不同的工具访问权限,就需要一个标准协议,即 MCP。
- Harrison 强调 MCP 的价值在于使非开发者能够构建和定制代理,创建适合专家的工作流程,而不必深入代理逻辑。
- Nuno 认为 MCP 的实用性被过度评价(overrated),因为大多数情况下代理需要根据工具进行定制,而不是简单地插入一个 “神奇的工具”。
- Harrison 指出,尽管当前代理的可靠性和成功率可能不是 100%,但随着模型的改进,这些指标将会提高。
- Nuno 提到,即使是个性化的代理,如果半数时间都失败,那它的实用性就不大。
- Harrison 对 MCP 的未来持乐观态度,他看到了 MCP 与 Zapier 类似的连接能力,可以创建无数的工作流程。
- Nuno 认为 MCP 需要变得更像 OpenAI 的 Custom GPTs,并且需要解决复杂性、实现难度、服务器端使用以及随机工具插件带来的质量问题。
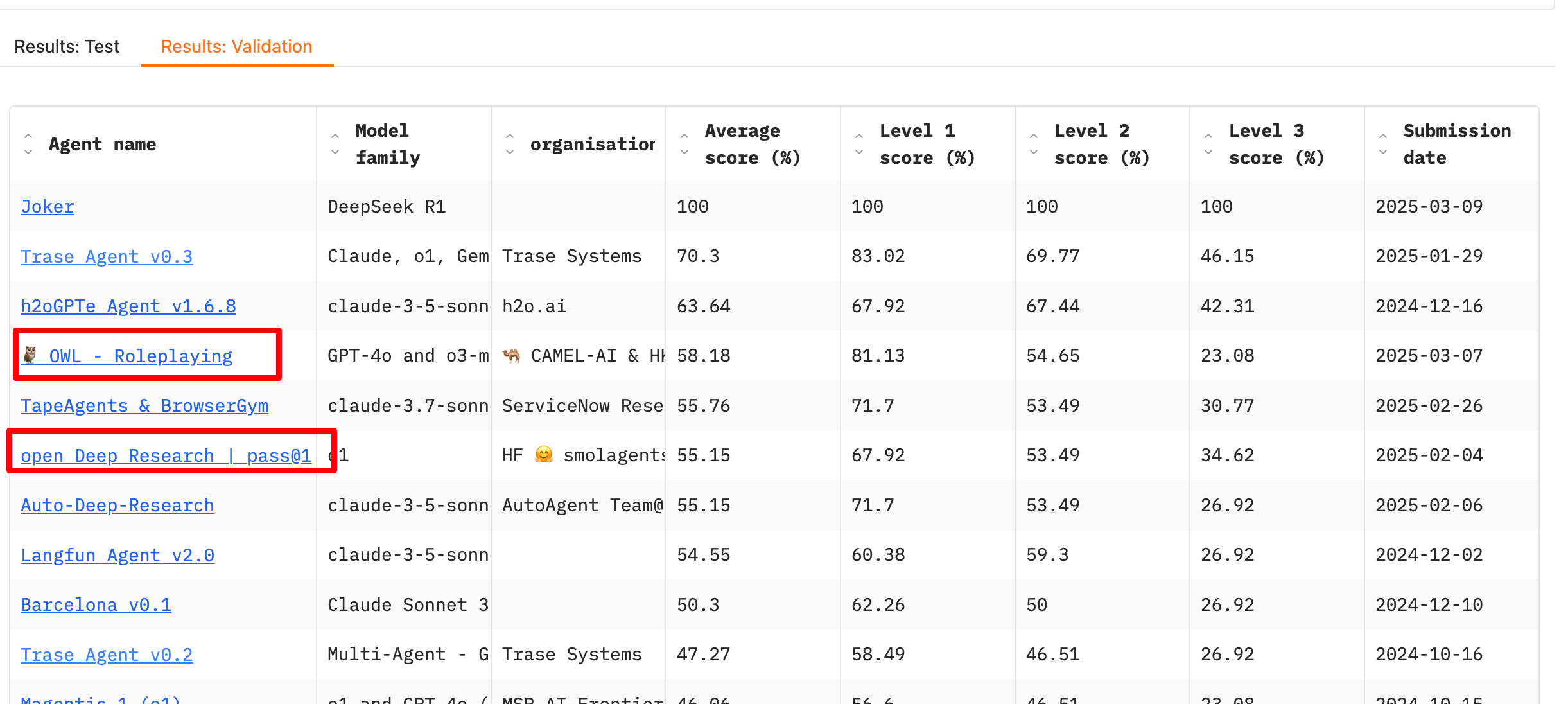
Manus(本来不想提的)延伸的开源项目 OpenManus 解读 和 OWL 技术实现,大家可以侧面看看 Manus 的技术实现,这种所谓的 Agent 产出的结果多么的不稳定,(以及声称通用 Agent 的营销噱头有多大)。此外,下面是一个 GAIA Leaderboard,Manus 声称超过 OpenAI Deep Research,但是看不到。
OpenAI 发布 Agents SDK:OpenAI 炒冷饭的姿势太差了,在 Swarm (5个月前发布的)基础上加了工具“又赢“了一次,而且很封闭,使用trace,内置的search 、computer use、browser use能力,用openai自己的模型才行。
聊聊RFT:作者认为 RFT 并不是一个全新的技术范式,而是在 PPO 技术范式下的一个新应用范式,其创新之处在于使用了 rule-based reward_model。RFT 的工作原理是通过 verifier 判断给定 prompt 下产生的包含 cot(Chain of Thought)的 response 是否正确,并以此作为信号指导模型参数的更新。这个过程在去除 cot 的情况下,与传统的基于 PPO 的 RLHF 非常相似,不同之处在于 reward 信号是由 verifier 算出的,而不是 reward_model。作者认为 RFT 的核心技术难点在于高质量的 cot 生产和高准确率的 verifier 获取,并且指出 RFT 站在了 o1 的肩膀上。RFT 的价值在于能够通过定制化 verifier 在特定领域任务上,以较少的数据量超过 SFT(Supervised Fine-Tuning)的效果。
这篇文章值得反复读,指出了在实践中构建企业 Agent 时需要面对的核心问题。
产品
推荐两个 Lab,用于展示一些 AI 可以做的一些有趣应用,一个是 Meta FAIR AI Demos,一个是 Google Labs。
Google 最近发布其最新的开源模型 Gemma 3系列:Gemma 3 是 Google 推出的一系列开源模型,旨在在单个 GPU 或 TPU 上运行。它包括不同大小的模型(1B、4B、12B 和 27B),适用于各种硬件和性能需求。Gemma 3 在其尺寸类别中表现出色,支持超过 140 种语言,并具备高级文本和视觉推理能力。此外,Gemma 3 提供了一个 128k-token 的上下文窗口,支持复杂任务的函数调用,并提供了量化版本以提高性能并降低计算要求。与此同时,Google 还发布了基于 Gemma 3 的 ShieldGemma 2,这是一个用于图像安全检查的 4B 模型,可以输出三种安全类别的标签,为开发者提供了一种检测危险内容、色情和暴力内容的工具。
模型下载:https://huggingface.co/collections/google/gemma-3-release-67c6c6f89c4f76621268bb6d
在线体验:https://huggingface.co/spaces/huggingface-projects/gemma-3-12b-it
技术报告:https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf
Google 宣布在 Google AI Studio 和 Gemini API 上推出了 Gemini 2.0 Flash,这是一款具备原生图像生成功能的 AI 模型,能够通过多模态输入、增强推理能力和自然语言理解来生成高质量图像,并支持文本与图像结合、对话式图像编辑、真实感图片创作和高质量文本渲染等功能。在线体验:https://aistudio.google.com/
创建角色一致性的 AI 互动故事、制作 AI 插图方便多了。
Cloudflare 推出了 Cloudflare Media Transformations 功能:允许用户在不迁移存储的情况下,通过修改 URL 参数对视频进行在线优化、裁剪、尺寸调整、缩略图截取和音频去除,以提高视频加载速度、节省带宽成本并自动化内容优化。
这对于短视频、电商和社交媒体等应用场景特别有用。
-
MGX:一款多智能体AI开发团队,能够完成创建网站、博客、商城、数据分析、游戏等各类需求。MGX模拟软件开发团队的协作流程,将自然语言需求转化为可执行的代码和文档,提高开发效率和可追溯性。
Teamble AI:提供简单、持续、可行的员工反馈工具,帮助企业提高员工绩效和沟通效果。集成在Slack和Teams上,使团队成员能够在日常工作中提供及时的建设性反馈。
Supergrid by Depict:一款AI工具,帮助Shopify店铺提升购物者转化率,通过动态排序和编辑级视觉效果设计出吸引人的产品展示网格。
OpusClip ReframeAnything:利用AI技术快速优化视频尺寸,适用于任何社交平台,帮助内容创作者和营销人员根据不同平台的要求调整视频尺寸。
Fynix:一款AI驱动的代码助手,提供实时代码建议、流程图生成和AI驱动的代码审查服务,提高开发者的代码质量和开发效率。
Pieces Long-Term Memory Agent:帮助开发者记录和回忆工作历史细节,快速恢复工作进度,提高工作连续性和团队协作效率。
ResumeUp 2.0:一款AI驱动的简历构建工具,通过与AI聊天生成简历,帮助求职者快速制作出ATS友好的简历,提高面试成功率。
Lanceboard:一款AI驱动的自由职业平台,通过发布任务“票据”并利用AI匹配合适的自由职业者,帮助用户高效完成任务。
Venice:提供私密、无审查的AI平台,结合区块链技术和生成式AI确保数据隐私和信息自由,为用户提供安全的AI服务。
Quadratic AI:一款现代化的电子表格工具,提供一个集AI、代码和数据连接于一体的平台,帮助用户快速获得数据洞察和创建交互式图表。
市场
- OpenAI 与拥有丰富 GPU 资源的云服务提供商 CoreWeave 签订了一项为期五年、价值 119 亿美元的协议。这笔交易包括 OpenAI 获得 CoreWeave 价值 3.5 亿美元的股权。此前,微软是 CoreWeave 的最大客户,在 2024 年占其收入的 62%,而 OpenAI 与微软在企业客户方面展开竞争,并且 OpenAI 正在寻找更多的计算资源。微软正在开发自己的 AI 模型,与 OpenAI 的产品竞争。
- Ilya 团队通过再融资 20 亿美元,使得 SSI 估值达到 300 亿美元:并曝光了其以色列特拉维夫办公室的顶级研究团队成员。该团队成员包括特拉维夫大学的 Yair Carmon 博士、前谷歌研究员 Yaron Brodsky、数学竞赛获奖者 Nitzan Tor 等。这支研究团队聚焦于计算机科学和数学领域,致力于打造 SSI 的首个 AI 模型,目标是开发能力超强的 AI,并确保其安全。
- No one knows what the hell an AI agent is:AI 代理这一术语在科技界和商业领域被广泛使用,但人们对其具体含义的理解各不相同。AI 代理的定义因应用场景和公司的不同而有所差异,从简单的自动化工具到具有高级决策能力的复杂系统,都被归类为 AI 代理。这种模糊性导致了行业内对于 AI 代理能力和局限的误解,也影响了对 AI 未来发展的预测。为了更好地理解和规范 AI 代理的发展,需要更业内部的共识和清晰的定义。此外,还提到了 AI 代理在不同领域的应用,如客户服务、个性化推荐和自动化决策过程中的作用,以及它们如何影响人类的工作方式和生活。
观点
Cartesia 创始人访谈:Cartesia 是一家专注于重构 AI 语音交互的公司,近期完成了由 Index Ventures 领投的 2,700 万美元种子轮融资。该公司由 Mamba 神经网络架构的作者及其斯坦福同学和导师共同创立,创始人包括 Karan Goel 和 Albert Gu。Cartesia 的核心产品 Sonic 是一款高性能的文本转语音(TTS)引擎,旨在通过低延迟和高交互性改善游戏和 Voice Agents 的体验。
- Cartesia 的技术创新和商业潜力在于其能够提供毫秒级响应的 TTS 引擎,以及在边缘计算上的优势,这将极大提升用户体验。
- 随着行业对 “小而精” 模型的重视,Cartesia 提出的边缘计算方案,即利用本地算力而非完全依赖云端资源,为模型的实时处理能力提供了新的可能。
- SSM 和 Transformer 结合的混合模型能够在效率和性能之间取得平衡,这一比例可能是 SSM 层与注意力层的 10:1。
- 文本转语音技术虽然取得了进步,但仍需在自然度和情感性方面进行深入研究,以便通过 “30 秒交互测试”,让用户感受到与真人对话般的自然度。
- 音频和语音相关功能正逐渐成为多模态 AI 的重要实验场,Cartesia 的 Sonic 引擎通过在 “语音–文本–语音” 闭环内统一语言理解、语音合成、语音识别等环节,降低了延迟瓶颈和工程复杂度。
- Cartesia 的 SSM 技术在处理长序列和感知数据时表现出色,且其效率远高于 Transformer,这为 AI 语音交互领域带来了新的技术突破。
- 从文本转语音作为商业化的切入口,Cartesia 的目标是通过构建通用型高效模型框架,优化语音和音频生成的实时性与成本效益。
- 端侧小模型的趋势揭示了如何在资源受限的设备上实现高效、低成本的智能计算的关键问题,Cartesia 的技术方向不仅降低了智能语音应用的成本,还将催生全新的场景和商业模式。
- Cartesia 在多模态领域的野心包括实现语音到文本再到语音的无缝转换,以及通过多模态模型的统一化设计,简化现有技术栈中的多模型协作带来的延迟和复杂性问题。
25年什么样的 Agent 会脱颖而出:简单胜于复杂:本文深入探讨了 AI Agent 的发展趋势,分析了 OpenAI 发布的两款 Agent 产品:Operator 和 Deep Research,并基于 Anthropic 的研究,探讨了 Agent 的本质与定义、核心竞争力以及对算法工程师的启示。文章强调简单胜于复杂的设计理念,并预测了 AI Agent 未来的发展方向。
- AI Agent 的未来发展将倾向于简单胜于复杂的设计理念,端到端训练的单个模型能够提供更高的整体成功率。
- 尽管 OpenAI 的 Deep Research 在深度研究方面表现出色,但仍存在幻觉现象和信息源准确性问题,目前还不适合直接用于生产环境。
- Anthropic 的研究指出,最成功的 AI Agent 应该采用简单、可组合的构建模式,而非依赖复杂的框架或专用库。
- 在选择 workflows 还是 agents 时,应该从简单的解决方案开始,并且只在必要时增加复杂性,避免过度设计。
- 长期来看,端到端训练的 Agent 将逐渐崛起,成为主流,而顶级的 Agent 可能工程代码及其简洁,所谓模型即服务。
- 应用型算法工程师应该积累场景测试集、学会微调、避免过度设计、选择与大模型协同发展的方向以及灵活运用 workflow 与端到端优化,以适应 AI Agent 的发展。
Vol.43 什么样的 Agent 会在 2025 年脱颖而出?
