Vol.45:Anthropic MCP 当前还有哪些不足?
大家好!Weekly Gradient 第 45 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
MCP 专题
模型上下文协议(Model Context Protocol, MCP)是一种正在迅速普及的协议,它允许AI客户端与外部服务和工具服务器进行交互。MCP让AI客户端不再局限于对话和信息检索,而是能够采取实际行动,比如发送电子邮件、部署代码更改、或发布博客文章等。我在周刊的30、35、43、44期都有介绍。
-
- 基于 OAuth 2.1 的身份验证框架
- 将之前的 HTTP+SSE 传输方式替换为流式 HTTP 传输
- 支持 JSON-RPC 批处理
- 工具注解,用于更好地描述工具行为
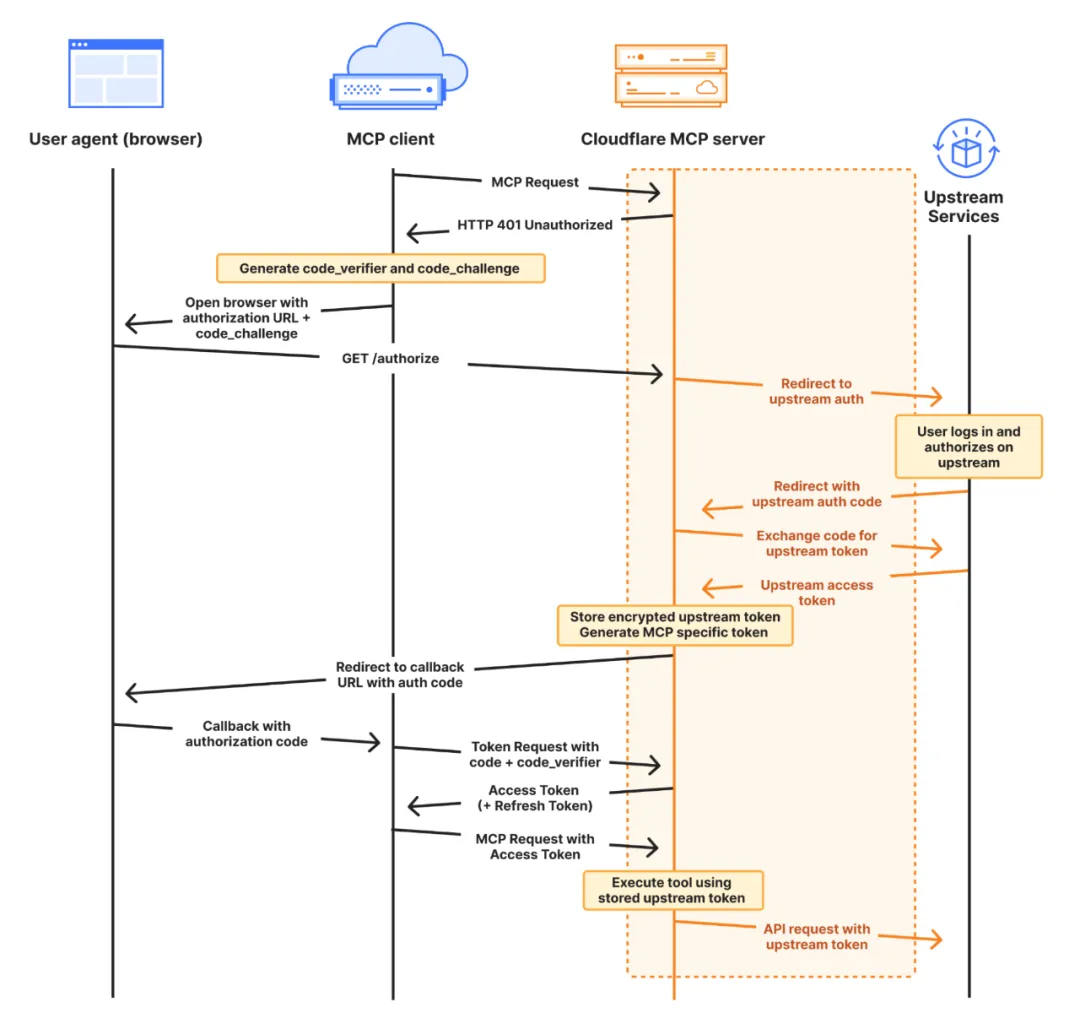
Cloudflare 推出远程 MCP Server部署功能:Cloudflare 提供了四个核心组件来简化远程 MCP Server 的构建过程,它们共同简化了远程 MCP Server的构建和部署过程。首先,workers-oauth-provider 作为一个 OAuth 2.1 库,简化了用户认证和授权流程,使得开发者无需自行实现复杂的 OAuth 认证。McpAgent 类集成在 Cloudflare Agents SDK 中,负责处理远程传输,使得 MCP 服务器能够接收和处理来自 MCP 客户端的消息mcp-remote 是一个适配器,它允许本地 MCP 客户端使用远程 MCP 服务器,让这些客户端能够连接和使用远程服务器。AI playground 作为一个远程 MCP 客户端,提供了一个在线聊天界面,允许用户通过 Internet 连接到远程 MCP 服务器,并进行必要的认证检查,从而使得用户可以直接在网页上与远程 MCP 服务器交互和测试。
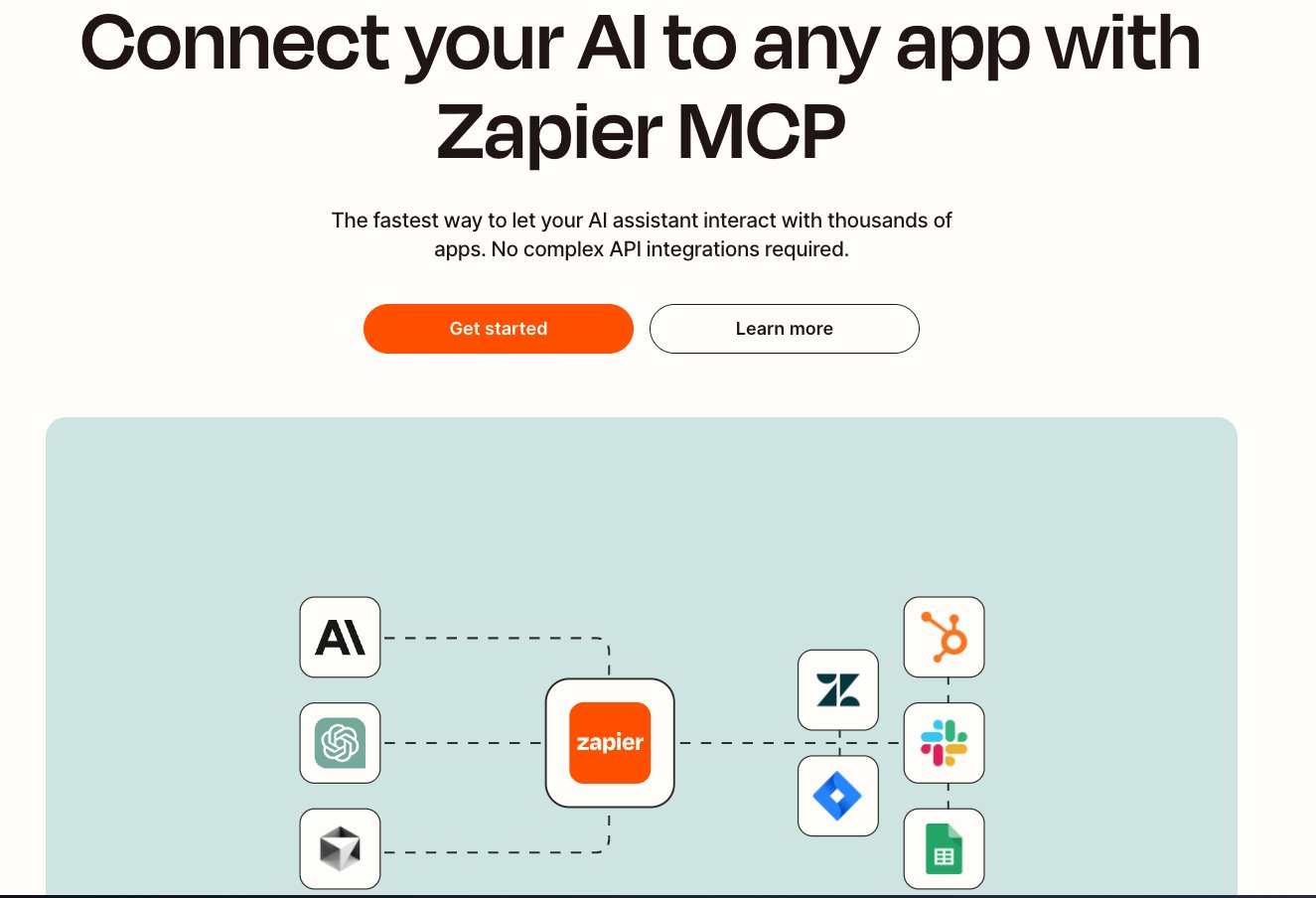
Zapier 推出MCP全流程方案:Zapier MCP 通过一个动态的 MCP 端点将 AI 助手与 Zapier 的广泛集成网络连接起来,实现了对超过 8000 个应用的直接访问。它允许 AI 执行真实动作,如发送 Slack 消息或管理 Google Calendar 事件,从而将 AI 从简单的对话工具转变为应用程序的功能性扩展。提供了一个安全和可靠的平台,让开发者能够专注于编码,同时由 Zapier 管理身份验证、API 限制和安全性。
OpenAI 的 Agents SDK 支持 MCP,允许使用各种 MCP 服务器为 Agent 提供工具。MCP 服务器分为两种:基于标准输入输出(stdio)的服务器和基于 HTTP 超文本传输协议(HTTP over SSE)的服务器。使用 MCPServerStdio 和 MCPServerSse 类可以连接到这些服务器。
通义千问网页端有 MCP 调用入口,高德地图提供 MCP Server,百度地图核心API现已全面兼容MCP协议。
详解 MCP:Agentic AI 中间层最优解,AI 应用的标准化革命:文章认为MCP 生态下创业公司的三个主要机会
Agent OS:在 MCP 生态系统中,Agent OS 是一个重要的创业机会。随涉及到为 Agentic AI 构建操作系统,使得 AI 能够更有效地管理和执行任务。
MCP Infra:MCP Infra 提供了基础设施支持,允许创业公司构建和维护 MCP 相关的基础设施,为 AI 应用提供支持和资源。
MCP Marketplace:MCP Marketplace 是一个平台,它允许用户发现、共享和贡献 MCP Server,为创业公司提供了一个展示和分销产品的渠道。
a16z 探讨了 MCP 的发展前景、使用案例、挑战以及对 AI 工具链和基础设施的潜在影响。

论文
-
BizGen 视觉文本渲染流程:
- 信息提取:BizGen 首先从文本中提取关键信息,这是生成准确信息图表的基础。
- 智能匹配:根据提取的信息,模型通过智能算法匹配最合适的视觉元素和图表类型。
- 视觉元素生成:利用计算机视觉技术,将提取的信息转换为视觉元素,如图表、图形等。
- 自适应图表选择:自动选择与文本内容相匹配的图表类型,如柱状图、线图、饼图等。
- 视觉布局优化:通过视觉布局优化,确保信息图表的美观性和视觉效果,同时保证信息的准确性和清晰性。
推理模型在Agents场景的能力分析:结论是将LLMs的执行效率与LRMs的推理深度相结合,可以实现更优的Agent性能,DeepClaude从一开始就这么做的。
LRMs 在推理密集型任务中优于 LLMs。
LLMs 在执行驱动任务中表现更好。
混合配置:LLMs 执行 + LRMs 推理优化性能
LRMs 在推理密集型任务中成本高、时间长
混合架构:结合 LLMs 执行效率和 LRMs 推理深度
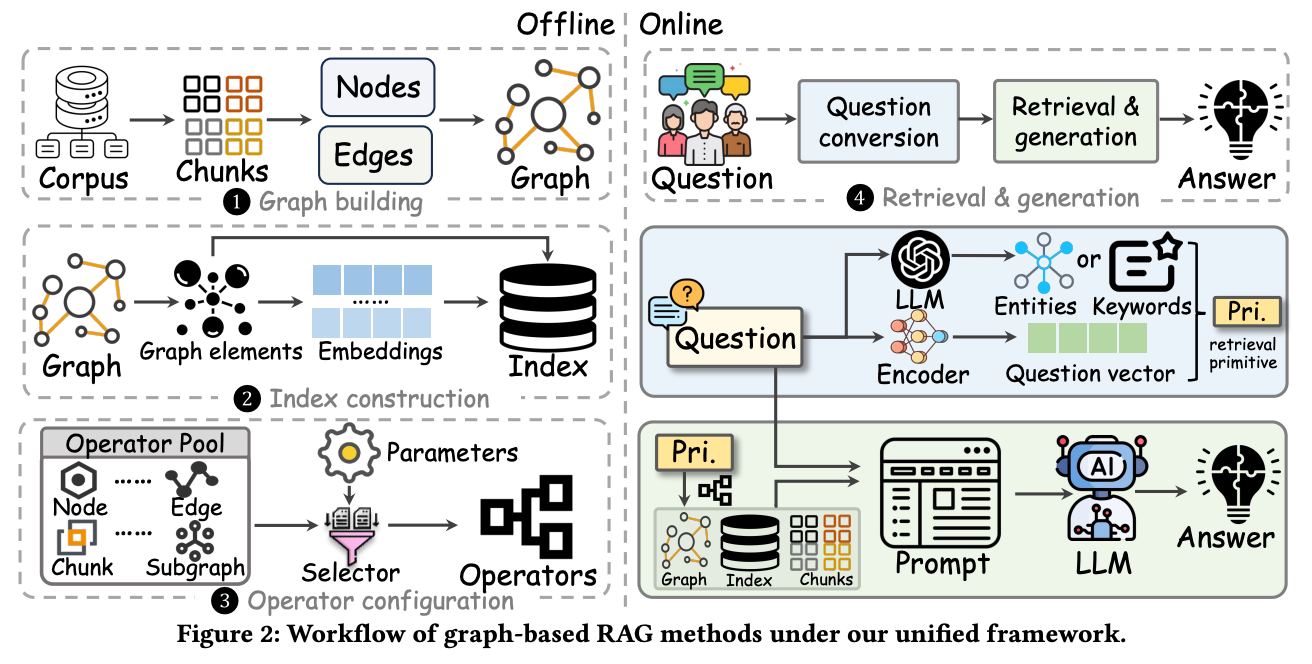
全面系统的分析 9 个GraphRAG 方法后提炼的统一框架:该框架分为四个阶段:图构建、索引构建、算子配置和检索与生成。这个框架能够覆盖现有基于图的RAG方法,具体如下图所示。
图构建:将外部知识库分割为文本块,利用语言模型(LLM)等工具提取实体和关系,构建图。常见图类型包括段落图、树结构和知识图谱等。段落图示例:每个文本块作为节点,若两节包含相同实体超过阈值,则两节点之间建立边。知识图谱通过提取实体与关系构建,实体代表对象,关系表示对象间的语义联系。例如,美国总统选举知识图谱中,“拜登”和“特朗普”等候选人为节点,相关关系如“竞选对手”或“获胜者”。
索引构建:为高效在线查询设计索引。索引分为节点索引、关系索引和社区索引,存储节点、关系或社区信息。节点索引通过文本编码模型(如 BERT)生成节点嵌入向量,存储于向量数据库中以便快速检索。例如,用户查询“ย登的竞选对手是谁?”系统通过节点索引快速检索到“拜登”和“特朗普”。
算子配置:配置操作符以灵活检索与用户查询相关信息。常见操作符包括节点类型、关系类型、块类型和子图类型操作符。例如,用户查询“拜登和特朗普的竞选关系”时,系统检索到“拜登”和“特朗普”,并确定它们之间的关系。
检索与生成:在图RAG(Graph-based RAG)方法中,这个阶段分为问题转换和信息检索与生成。问题转换:用户输入的问题转化为检索系统理解的格式。策略包括实体提取、向量编码或直接使用原始问题。信息检索与生成:根据检索原语从图中检索相关信息,并输入大语言模型生成答案。生成方式包括直接生成和分步聚合。直接生成将检索到的信息与问题拼接后直接生成答案;分步聚合则是先生成部分答案,再汇总成最终结果,适用于复杂问题。
τ-bench:现实领域工具-Agent-用户交互基准:这个基准测试是我目前见过设计最合理的,特别是对于垂直领域 Agent 要在对话交互过程中动态调用工具的情况,像Berkeley函数调用排行榜(BFCL)、ToolBench和MetaTool等,仅包含单步用户交互,实际情况中 Agent 需要在长时间范围内与人和API进行无缝交互以收集信息和授权,准确遵循复杂的领域规则和策略,并在大规模交互中保持一致性和可靠性。用户状态包括初始系统提示和任务指令以及用户和Agent之间的整个对话历史,但用户消息往往是随机的,Agent的消息附加到聊天记录后,需要从语言模型中采样新的用户消息,以匹配用户的身份、意图和偏好。
$\tau$-bench的设计细节
模块化框架:$\tau$-bench采用模块化设计,包括数据库、API工具、领域策略和用户指令。这种设计允许灵活地添加新的领域或更新现有数据。
数据库和API工具:每个领域都有多个数据库和API工具,模拟真实世界的数据和功能。数据库的状态是隐藏的,只能通过API工具进行读取和写入操作。
领域策略:每个领域都有一个详细的策略文档,描述了Agent必须遵循的规则和限制。这些策略帮助模拟真实世界中的复杂规则和约束。
用户模拟: 使用语言模型(如gpt-4)来模拟用户的行为,生成自然语言的对话。这种方法可以产生多样化的用户输入,模拟真实世界中的不确定性。
评估过程:通过比较对话结束时的数据库状态与预期的目标状态来评估 Agent 的表现。这种方法确保了客观性和一致性。
模拟真实世界交互的原因
1. 动态对话:通过模拟用户和Agent之间的自然语言对话,$\tau$-bench能够捕捉到真实世界中复杂的交互模式。
2. 规则遵循:Agent 需要在遵循领域策略的同时完成任务,这模拟了现实世界中对规则和政策的遵守。
3. 多样性和复杂性:使用语言模型生成的多样化用户输入和复杂的数据结构,使得基准测试能够模拟真实世界中的多样性和复杂性。与其他评测的区别
交互类型: $\tau$-bench强调Agent与人类用户和API的交互,而其他一些基准测试可能只关注Agent与环境的交互。
规则遵循: $\tau$-bench特别关注Agent在遵循领域策略方面的能力,而其他基准测试可能更侧重于简单的指令遵循或工具使用。
用户模拟: $\tau$-bench使用语言模型来模拟用户,生成自然语言的对话,而其他基准测试可能使用规则驱动的用户模拟器或真实用户。
任务多样性: $\tau$-bench的任务设计更加开放和多样化,能够模拟多种现实世界场景,而其他基准测试可能更专注于特定的任务类型。
工程
常见的 AI 模型格式:一篇扫盲文章,介绍了常见 AI 模型格式,包括 GGUF、PyTorch、Safetensors 和 ONNX,并分析了它们的优缺点、使用场景以及硬件支持情况。
- GGUF:是一种二进制格式,用于快速加载和保存模型,易于阅读。它支持灵活的量化方案,通常用于语言模型,但也适用于其他类型的模型。GGUF 的优点包括简单、快速、高效和便携性,但也有其他格式需要转换的缺点,以及在模型保存后修改或微调不便利。
- PyTorch:使用
.pt或.pth扩展名保存模型状态。PyTorch 格式基于 Python 的 pickle 模块,它允许序列化和反序列化 Python 对象,但也有局限性,如安全性问题、效率问题以及可移植性问题。 - Safetensors:由 Hugging Face 开发,解决了传统 Python 序列化方法中的安全性和效率问题。它支持延迟加载和部分数据加载,但在量化方案上不如 GGUF 灵活。
- ONNX:提供与供应商无关的机器学习模型表示方法,包括模型的计算图。它适用于跨平台和硬件部署,但在量化张量的支持上有限。
万相Wan2.1视频LoRA训练指南:作者介绍了如何使用 LoRA 来个性化训练万相视频生成模型,从基础概念到实际操作,指导如何根据不同的生成任务和应用场景选择合适的 LoRA 模型,包括文本到视频 LoRA(T2V-LoRA)和图像到视频 LoRA(I2V-LoRA)。此外,还提供了环境准备、数据集准备、训练参数调整等相关信息,以及如何开始训练。
Qwen 团队开源多模态模型 Qwen2.5-Omni-7B,它能够无缝处理多种形式的输入(文本、图像、音频和视频),并实时生成文本与自然语音输出。Qwen2.5 Omni 采用了新的 Thinker-Talker 架构,支持跨模态理解,并通过 TMRoPE 技术实现了视频与音频输入的精准同步。该模型在实时音视频交互、自然流畅的语音生成以及全模态性能优势方面表现出色,超越了许多现有的流式和非流式替代方案。在端到端语音指令跟随能力和多个领域的基准测试中,Qwen2.5 Omni 均表现出色。
pdf-craft:一个专注于处理扫描书籍 PDF 文件的工具,它能够将 PDF 文件转换为 Markdown 或 EPUB 格式。使用 DocLayout-YOLO 算法提取书页正文,并过滤掉页眉、页脚等元素,确保文本的语义通顺。对于 EPUB 格式的转换,PDF craft 会将 OCR 识别的数据传输给 LLM,并构建书本的结构,最终生成带目录的 EPUB 文件。在使用过程中,需要配置 LLM 服务,此外,PDF craft 还支持将 PDF 转换为 Markdown 格式,并将插图、表格、公式以图片形式插入到 Markdown 文件中。
Agno 提供了一个标准化的代码库,用于构建和管理 Agentic 系统:通过标准化的代码库(工作区),可以更快地构建和部署高质量的 Agentic 系统。这些工作区包含了多年的实践经验,为开发者提供了一个极好的起点。Agno 建议在本地环境中实验和完善代理系统,直到达到 6/10 的质量标准,然后再转向生产环境进行迭代和完善,最终达到 9/10 的质量标准。

产品
OpenAI 推出4o Native Image Gen,原生多模态模型,通过精确的图像和文本结合,提升图像生成的实用性。集成在 GPT-4o 中,能够根据用户的需求生成具有特定风格和情境的图像,例如高质量的游戏角色外观、高级别的文本渲染、多图生成等。此外,OpenAI 还提供了一系列的示例和指令,展示了如何通过自然语言指令来优化和创造图像。同时,OpenAI 也承认了模型的局限性,包括处理非西班牙语文本、维护图像一致性和细节渲染等方面的挑战。
效果太强了,大家最好使用英文测试,OpenAI 这次数据做的十分扎实,因为只有 OpenAI 和谷歌早早就开始在原生多模态上进行投入,前有 gemini-2.0-flash-exp-image-generation ,现有 4o 图像生成,这个能力其他家其实都不太好追,当然也可以像字节一样的进行工程上的取巧。
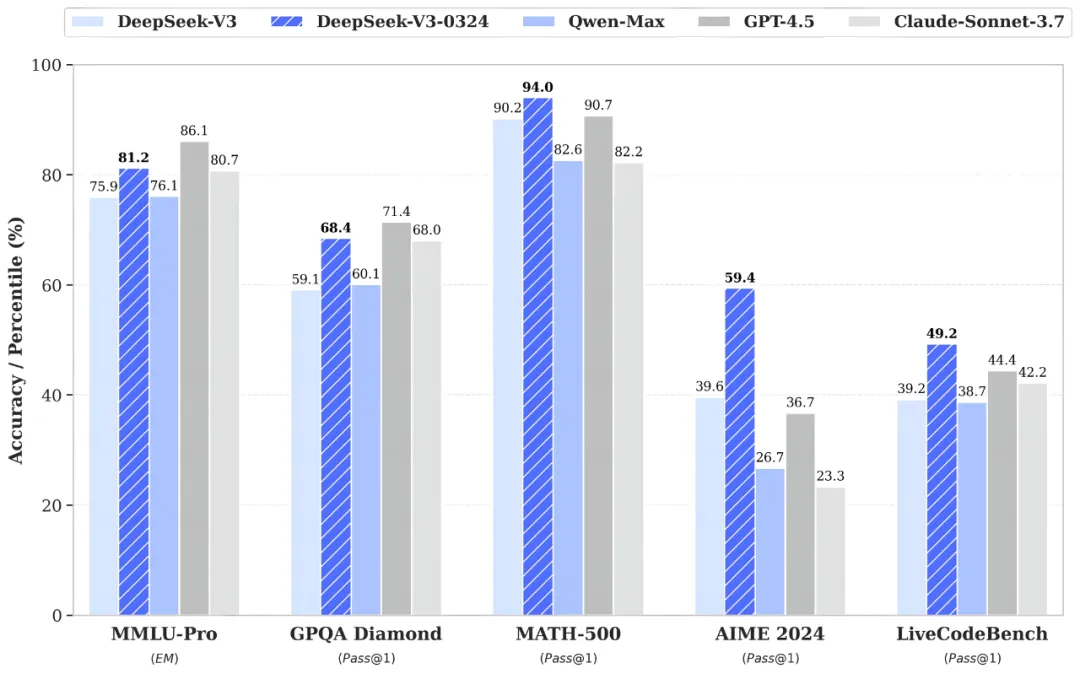
DeepSeek-V3 模型进行了小版本升级,推出了 DeepSeek-V3-0324 版本:新版本在推理任务上表现更佳,超过 GPT-4.5 的得分,在数学、代码任务上也有所提升。同时,新版本在中文写作、前端开发能力上也有显著提升,特别是在 HTML 等代码前端任务上的代码可用性和视觉效果。此外,新版本的中文搜索能力优化,能够在联网搜索场景下提供更详细准确的结果。DeepSeek-V3-0324 模型的参数约为 660B,支持的上下文长度为 128K,模型参数已开源。
-
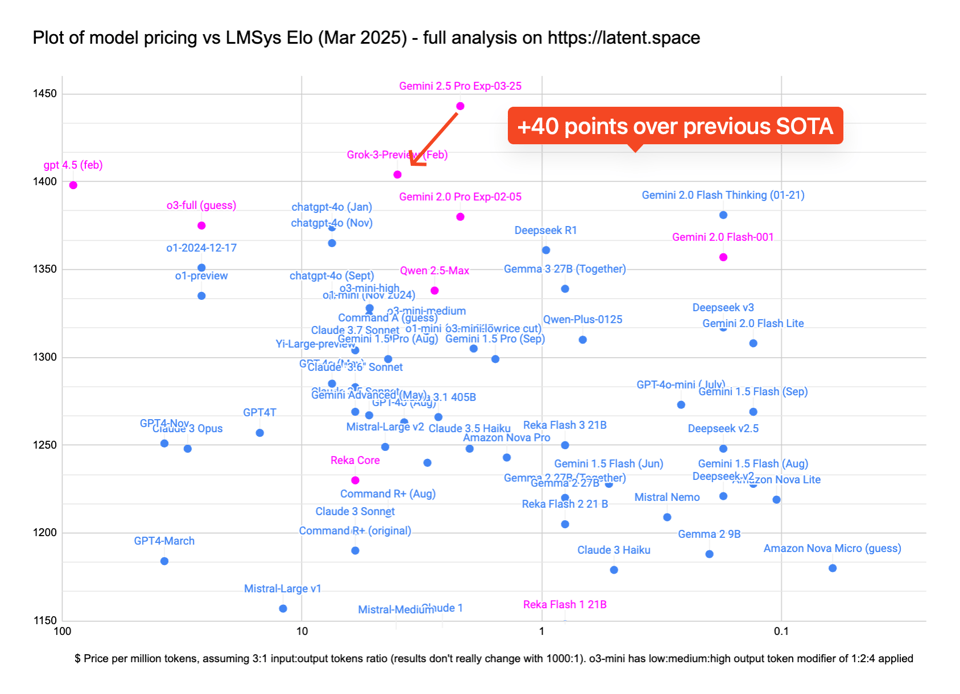
- 复杂任务处理:Gemini 2.5 Pro Experimental 版本在 LMArena 人类偏好榜单上大幅度领先。
- 推理和编码能力:Gemini 2.5 Pro 在常见的编码、数学和科学基准上展现出卓越的性能,特别是在不适应推理的情况下。
- 人类知识和推理的边界:Gemini 2.5 Pro 在人类最后的考试(Humanity’s Last Exam)数据集上达到了 18.8% 的水平,这证明了其在捕捉人类知识和推理的能力上的显著提升。
- 编码性能:Gemini 2.5 Pro 在创建视觉效果丰富的 Web 应用和代码应用方面有显著提升,并在 SWE-Bench Verified 基准上使用自定义代理设置得分达到了 63.8%。
- 多模态和长上下文窗口:Gemini 2.5 Pro 展现出卓越的性能,能够理解和处理来自不同信息源的复杂问题,包括文本、音频、图像、视频甚至整个代码仓库。
Linkloud 与 Cartesia 官方合作,可免费体验价值 299 美金的最高等级套餐 “Scale” 一个月(包含 800 万 Credits 及容纳 15 条并发请求)!
Cartesia之前介绍过,“高拟人” TTS目前是国内外做的最好的产品,就是国内流式传输时延迟有点高。

市场
图解四部门《人工智能生成合成内容标识办法》及配套强制性国标与指南:鉴别部分设计很多技术细节,这次政府效率蛮高,我强烈支持,否则内容污染下去就玩完了。
2025面向决策者的负责任AI指南智能应用最佳做法:微软出品,就咨询公司那一套说辞。
2025年B2B企业AISEO实战策略报告:面向 AI 搜索做内容建设的策略。
2025年AI新时代内容营销行业洞察:沙利文出品,也是面向 AI 的品牌建设,更细致一点。

观点
真正的LLM Agent:依旧是上一期观点部分模型即产品(The Model is the Product)的理念的延续。
- Agent的核心价值。 Agent的核心价值在于它们能够自主规划和执行任务,而不是简单依赖预设的工作流程。
- Agent的发展方向。 未来的Agent将通过强化学习(RL)与推理(Reasoning)的结合,实现自主决策和工具使用。
- Agent的定义。 Agent是指能够在没有外部提示的情况下,自主内部完成任务的系统。
- Agent的独立性。 Agent能够在内部自主完成任务,而不是依赖外部调用或人工流程干预。
- Agent的训练方式。 Agent的训练是通过「草稿」(draft)来完成的,即通过模型自主生成的草稿进行评估和优化。
- Agent的「苦涩教训」。 Agent的设计注重自主搜索、规划和行动的能力,而不是依赖简单的提示(prompt)和规则约束。
- Agent的商业化。 未来几年内,Agent将不再仅是API服务,而是作为产品直接提供给市场。
- Agent的潜力评估。 市场尚未充分认识到Agent的强化学习(RL)潜力,这是一个需要重视的新兴领域。
-
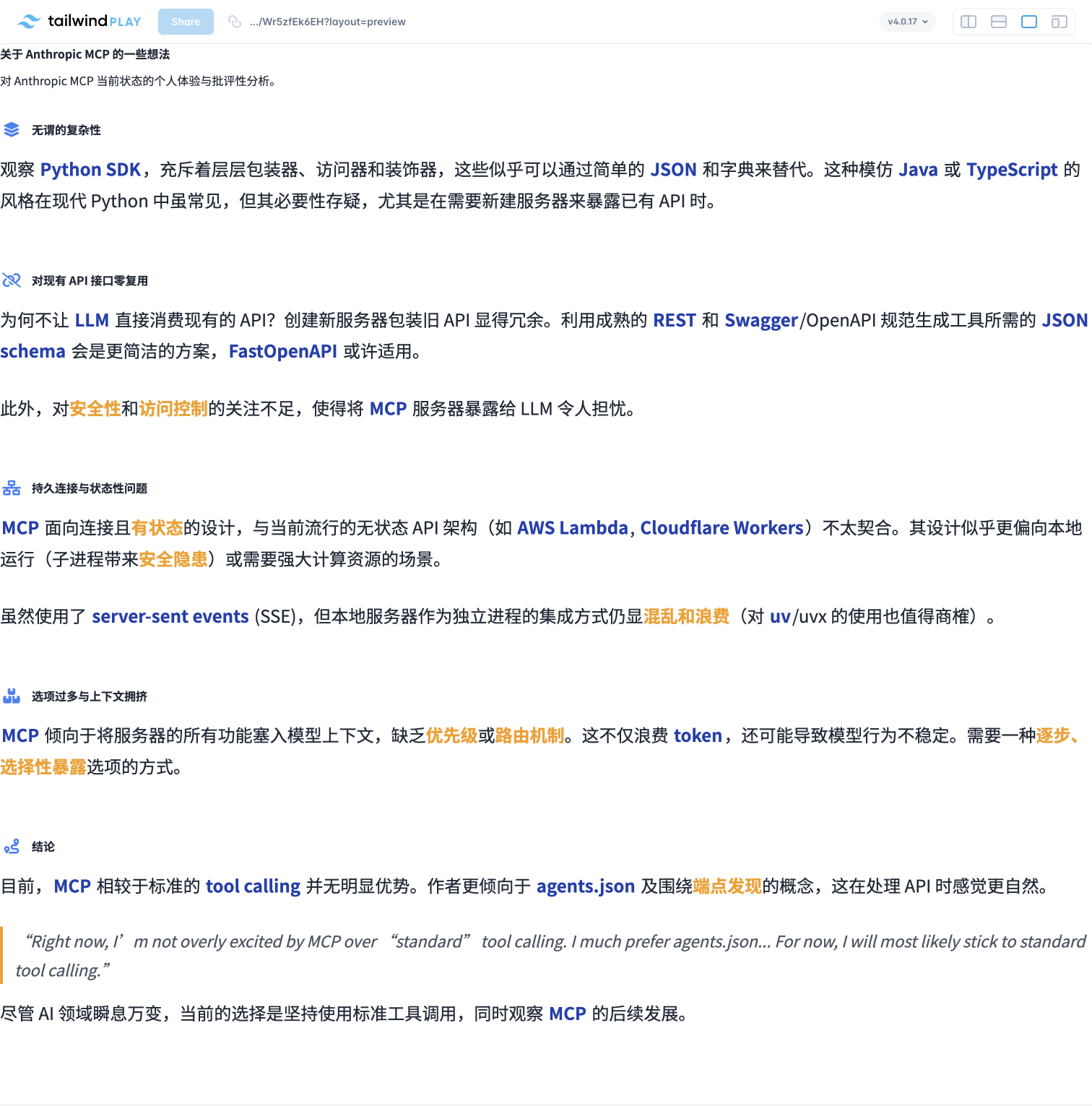
Vol.45:Anthropic MCP 当前还有哪些不足?
