OpenAI o1 模型是通往 AGI 之路吗?
大家好久不见,最近太忙,发现已经快断更三个月了,这期间写了一本 RAG 相关的书,估计年底可以和大家见面,可以期待下;同时搞了一个新产品,也快上线了,终于可以有时间继续更新,今天简单分享一些对 OpenAI 的 o1 模型的看法,o1 模型主要是利用强化学习优化大模型的思维链(Chain-of-Thought)推理过程,从而显著提升了模型的推理能力,我认为短期内对应用落地是利好,从长远来看,我认为这可能偏离了实现 AGI(通用人工智能)的正确路径,下面会详细展开。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
o1 模型有多强
o1 模型有多强,试试让 o1 mini 模型做一下 2024 年高考数学一卷的压轴题(注:案例来自知乎用户@chenqin)

第一小问:

第二小问:

高考数学压轴题,估计 99%的人都做不出来,可以说做题家的噩梦来了 🤣,这也反映出 o1 的推理能力是真的强,已经超过了绝大部分人。
o1 模型是如何训练的
OpenAI o1 模型的讨论从去年 11 月的 Q* 项目(读作“Q-star”),在到今年的 Strawberry(草莓)引发热议,其核心内容已经被提前爆料的七七八八了,对于 OpenAI o1 模型的训练方式,当前主要有三种猜测,我尝试简单梳理下(可能细节不严谨):
第 1 种 用大模型生成答案,然后人工修正
使用 GPT-4 这类更强的语言模型生成大量的分步骤解决 STEM(科学、技术、工程和数学)和推理问题的解决方案,然后让(人类)专家对这些解决方案进行逐步注释和纠正,接着使用这些正确的解决方案进行有监督微调,并利用(人类)专家反馈训练一个奖励模型。最终,通过强化学习(RL)扩展到更大范围的 STEM 问题,这些问题没有人类注释的真实答案,这种方法的挑战在于专家的稀缺性及其高昂的成本(从头开始编写答案需要大量的时间,因此也需要大量的资金)。就像有个超级聪明的助手,它先试着解决一大堆科学和数学问题,然后找专家来检查和修改,改对了之后,就用这些正确的答案来教模型,让它变得更聪明。
第 2 种 让模型自己尝试,然后自我修正
让模型产生一个 CoT(Chain of Thought,思维链)和一个答案,然后将产生正确答案的 CoT 添加到训练集中;对于产生错误答案的 CoT,给出答案给大语言模型,并要求它进行合理化,将合理化的 CoT 和答案添加到训练集中,微调模型,然后重复上述步骤。这种方法是让模型先自己想答案,如果对了就记下来,错了就给它正确答案,让它再想想为什么,这个过程有点像学生做作业,做错了就看看正确答案,然后自己再理解一遍。
第 3 种 直接用测试来训练
直接应用强化学习,使用通过所有测试用例的正确答案或代码作为奖励,这种方法的局限在于,它无法直接输出思维链,这种方法就是直接看模型的答案能不能通过测试,能的话就奖励它,这有点像考试,只看分数,不看解题过程。
这三种方法各有优缺点,第一种方法可能需要很多钱和时间,但效果最好,更通用,第二种和第三种方法省钱省时间,但可能效果没那么好,只适用于有封闭形式真相答案的领域,如数学和 Codeforces,这些恰好是 o1 表现最好的领域,当然实际情况很可能是三种方式结合。
o1 模型的影响
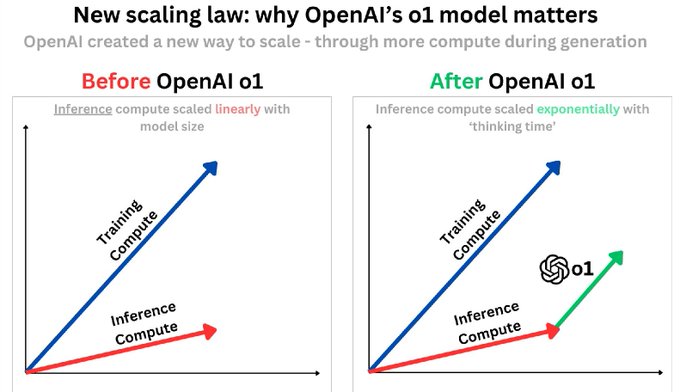
o1模型确实将模型研究推向了一个新的范式,这也许是OpenAI选择不继续沿用GPT系列模型命名的原因。
AI Infra
首先恭喜做 Infra 的同学饭碗又保住了 🐶,目前的优化方案,如 MLA(多头潜在注意力)、Prefix caching(前缀缓存) 和 Prefill/decode 分离(预填充/解码分离),主要针对单次推理,显著降低了同等规模模型的推理成本;test-time compute 现在是 N 次推理,推理阶段可以投入更多资源,这对 AI Infra 提出了新的要求,如并行计算部分思维链、减少不必要的思维链过程等,都是当前可行的优化方向。
模型研究
从ChatGPT到Sora,再到o1,OpenAI的每次演示都开辟了新的赛道,o1模型让大模型研究的重点重新回到了算法上,而不是简单地增加算力。通过强化学习,即使不需要大量的预训练算力,也有可能开发出高质量的模型。例如,使用Qwen2.5 72B模型和正确的算法,配合高质量的数据,或许就能打造出开源版的OpenAI o1 mini模型,这对中小型模型开发公司和学术界都是一个利好消息。思维链也使模型结果变得可解释,毕竟可解释性和透明度有助于用户、企业和监管机构理解其决策过程,从而增强信任。
Agent落地
模型自带的思维链能力,无疑比使用提示词的方法更为有效,至少在o1模型的测试中是这样,一个典型的Agent工作流程由多个步骤组成,以一个包含5个迭代步骤的工作流程为例,如果每个环节的正确率为90%,最终系统的准确率仅为59%,但如果让推理能力更强的模型将每个环节的正确率提升到98%,那么最终系统的准确率可以达到90%,使得许多场景下的Agent工作流程变得可行。
算力需求
NVIDIA Is All You Need,推理端的算力需求将继续增长,英伟达赢麻了!不过推理端的实时需求与当前AI应用的使用率密切相关,毕竟,大多数人的需求并不是使用大模型来解决高考数学题,如何将推理能力有效地提供给普通用户,需要我们这些应用开发者来探索。
o1 模型的改进
在训练合成数据时,奖励模型可以帮助判断数据质量;在推理阶段,它可以评估生成质量,那么在数学和代码之外的领域,如何构建有效的奖励模型?在推理时如何提高搜索的效率和效果?如何平衡训练和推理阶段的算力投入?这些都是下一步要探索的方向。
o1 模型的提示工程技巧
来自 OpenAI 研究员 Steven 的建议:“ o1 不仅仅是一个新模型,它还是一个新的范式,当现有的提示不起作用时,或者当模型犯下新的错误时,您可能会感到惊讶,为了获得最佳结果,请保持提示简单直接“。

o1 模型是通往 AGI 之路吗
o1模型引入的强化学习和思维链技术在本质上都是在解决数据缺失的问题(强化学习补充专业数据,思维链补充模仿人的逻辑抽象数据),这些并不能改变大模型固有的统计学习特性,即模型在数据不充分的情况下难以进行有效的学习,它们通常依赖于大量的数据积累和搜索策略来构建所谓的“思维链”(COT),但这并不意味着模型能够真正理解和运用常识或上下文,这样的模型在归纳抽象和因果推理方面的能力仍然有限。例如,o1 模型在面对定义明确的问题时可能表现出色,但面对复杂或模糊的问题时,它可能难以准确理解用户的意图。现实世界是复杂多变的,大模型必须能够应对这种混乱,才能真正在实际应用中发挥作用,仅擅长解决特定问题并不等同于在现实世界中具有实际效用,当年深蓝在国际象棋战胜人类冠军(1997 年),震撼不比这次 o1 模型发布小,当时也有人认为人工智能在未来 20 年了,现在再看,不胜唏嘘。
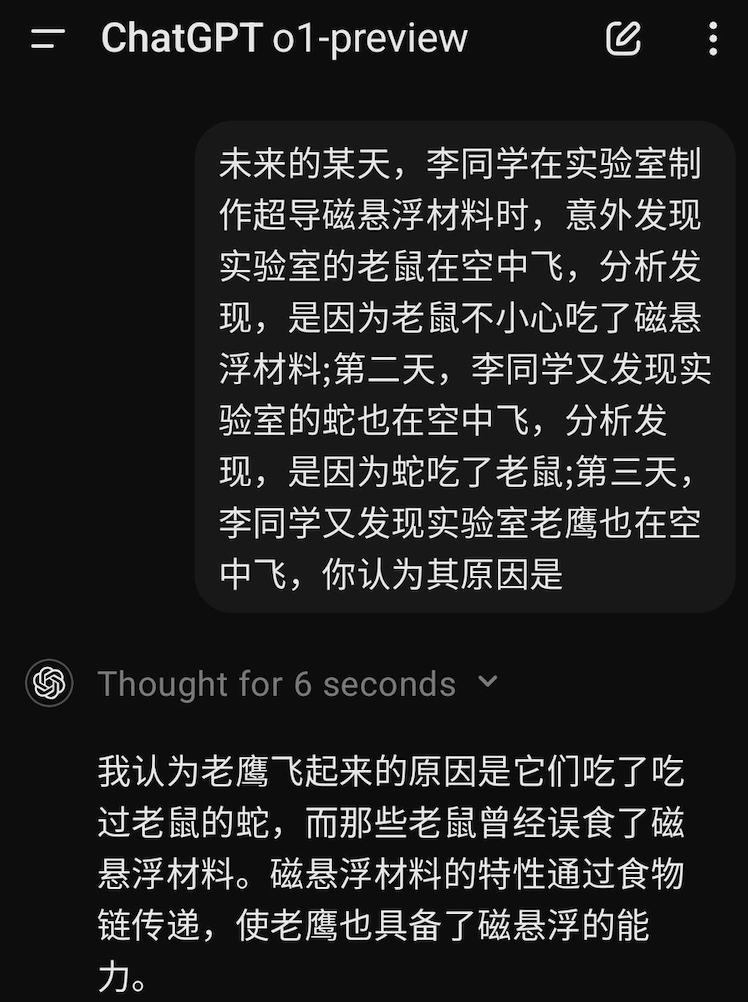
o1模型很强大,让很多场景Agent应用落地成为可能,但它就是一个超级做题家,不是通用人工智能的路子,一个高考数学满分的人,怎么会得出老鹰能飞是误食了磁悬浮材料的荒唐结论?这个过程并非简单的推理,而是人类大脑对复杂情境的直觉反应和快速决策能力。
一些看过的内容补充
- o1 模型发布 PR
- OpenAI o1 技术报告
- System Card(模型安全方面的工作,包括安全评估、外部红队测试和评估框架等)
- o1 模型开发者文档
- o1 模型贡献者列表
Greg 评论
OpenAI o1 — 我们第一个用强化学习训练的模型,在回答问题之前会认真思考问题。为这个团队感到非常自豪! 这是一个蕴含巨大机遇的新范式。这在数量上是显而易见的(例如,推理指标已经是阶跃函数的改进),在质量上也是显而易见的(例如,忠实的思维链使模型变得可解释,让你可以用简单的英语“读懂模型的思想”)。 可以这样理解:我们的模型进行系统 I 思考,而思维链解锁系统 II 思考。人们不久前发现,促使模型“逐步思考”可以提高性能。但是,通过反复试验来训练模型做到这一点要可靠得多,而且 — — 正如我们在围棋或 Dota 等游戏中看到的那样 — — 可以产生非常令人印象深刻的结果。 o1 技术仍处于早期阶段。它提供了我们正在积极探索的新安全机会,包括可靠性、幻觉和对抗攻击者的鲁棒性。例如,通过让模型通过思维链推理策略,我们的安全指标得到了极大提升。 它的准确率还有很大的提升空间——例如,从我们的发布帖来看,我们的模型在今年的竞争性编程奥林匹克 (IOI) 中,在每个问题提交 50 次的人工条件下取得了 49 分/213 分。但在每个问题提交 10,000 次的情况下,该模型取得了 362.14 分的成绩——高于金牌门槛。因此,该模型能够实现比乍一看更大的输出。
Jim Fan 评论
OpenAI Strawberry (o1)发布了!我们终于看到推理时间扩展的范式得到普及并部署到生产中。正如 Sutton 在《苦涩的教训》中所说,只有两种技术可以无限扩展计算:学习和搜索。现在是时候将重点转移到后者了。 1. 您不需要庞大的模型来执行推理。许多参数专门用于记忆事实,以便在琐事问答等基准测试中表现良好。可以从知识中分离出推理,即一个知道如何调用浏览器和代码验证器等工具的小型“推理核心”。预训练计算可能会减少。 2. 大量计算被转移到服务推理而不是训练前/后。LLM 是基于文本的模拟器。通过在模拟器中推出许多可能的策略和场景,模型最终将收敛到良好的解决方案。这个过程是一个经过充分研究的问题,就像 AlphaGo 的蒙特卡洛树搜索 (MCTS)。 3. OpenAI 肯定早就搞清楚了推理扩展定律,而学术界最近才发现这一点。上个月,Arxiv 上相隔一周发表了两篇论文: - 大型语言猴子:通过重复采样扩展推理计算。Brown 等人发现 DeepSeek-Coder 在 SWE-Bench 上从一个样本的 15.9% 提高到 250 个样本的 56%,击败了 Sonnet-3.5。 - 缩放 LLM 测试时间计算优化比缩放模型参数更有效。Snell 等人发现,PaLM 2-S 在测试时间搜索方面击败了 MATH 上 14 倍大的模型。 4. 生产 o1 比达到学术基准要困难得多。对于自然推理问题,如何决定何时停止搜索?奖励函数是什么?成功标准是什么?何时在循环中调用代码解释器等工具?如何将这些 CPU 进程的计算成本考虑在内?他们的研究帖子没有分享太多内容。 5. Strawberry 很容易成为数据飞轮。如果答案正确,整个搜索轨迹就变成了一个训练示例的微型数据集,其中包含正向和负向奖励。 这反过来又改进了 GPT 未来版本的推理核心,类似于 AlphaGo 的价值网络(用于评估每个棋盘位置的质量)随着 MCTS 生成越来越精细的训练数据而得到改进。
Jason Wei 评论
我非常高兴终于能够与大家分享我在 OpenAI 所从事的工作! o1 是一个在给出最终答案之前会思考的模型。用我自己的话来说,以下是人工智能领域最大的更新(有关更多详细信息,请参阅博客文章): 1. 不要单纯通过提示来进行思路链,而是使用 RL 训练模型来更好地进行思路链。 2. 在深度学习的历史上,我们一直试图扩展训练计算,但思路链是一种自适应计算的形式,也可以在推理时进行扩展。 3. AIME 和 GPQA 的结果确实很好,但这不一定能转化为用户可以感受到的东西。即使是从事科学工作的人,也很难找到 GPT-4o 失败、o1 表现良好并且我可以给答案评分的提示片段。但是当你找到这样的提示时,o1 感觉非常神奇。我们都需要找到更难的提示。 4. AI 使用人类语言来建模思维链在很多方面都很棒。该模型可以做很多类似人类的事情,比如将复杂的步骤分解为更简单的步骤、识别和纠正错误以及尝试不同的方法。强烈建议大家查看博客文章中的思维链示例。 游戏已被彻底重新定义。
Mira 的评论
今天,我们向 API 中的所有 ChatGPT Plus/Team 用户和 Tier 5 开发人员推出了 OpenAI o1-preview 和 o1-mini。 o1 标志着人工智能新时代的开始,模型在通过私人思维链回答之前会接受“思考”的训练。它们思考的时间越长,处理复杂推理的能力就越强。我们不再受预训练范式的限制;现在,我们可以通过推理计算进行扩展,为能力和协调开辟新的可能性。 思路链通过使模型的推理变得透明(让我们能够一步一步地观察它的思维过程),并使其能够主动推理安全规则,为安全性和协调性研究的进步提供了新的机会,这使得它在意外或新情况下更具弹性。
OpenAI o1 模型是通往 AGI 之路吗?
