漫谈 Python 服务器编程
昨天看了一位博主的 Let’s Build A Web Server 系列,觉得很有意思,就想在此基础上展开梳理下 Python 服务器编程的演化。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
Show Me Code
这是一个简单的回显服务器,服务端每次读取请求并返回一些内容给客户端。
1 | import socket |
但由于服务器是单进程的,如果一个请求占住了服务器,就没办法处理另一个请求,作为改进,加一些改动,每来一个请求就fork一个进程来处理。
1 | import os |
但多进程模型处理不好会出现僵尸进程(在终止后仍然在系统保留着进程记录表的进程)和孤儿进程,因此父进程需要处理SIGCHILD 信号来收集退出的子进程的信息。
1 | import os |
这就是CGI原理,一般来说是每个请求进来时,从server fork出一个进程,仅仅处理这一个请求,处理完成就退出,处理的过程是从环境变量中获取HTTP头,从标准输入中读取POST数据,从标准输出中输出HTTP响应,CGI只能收到一个请求,输出一个响应,由于需要不停地创建和销毁进程,效率低下;功能十分有限,很难在CGI体系去对Web请求的控制,例如:用户认证等。
FastCGI && WSGI
FastCGI
后来就出现了FastCGI,就是更Fast(误)的CGI,FastCGI使用进程/线程池来处理一连串的请求。这些进程/线程由FastCGI服务器管理,而不是Web服务器。当进来一个请求时,Web服务器把环境变量和这个页面请求通过一个Socket长连接传递给FastCGI进程。所以FastCGI有如下的优点:
* 性能:通过进程/线程池规避了CGI开辟新的进程的开销。
* 兼容:非常容易改造现有CGI标准的程序。
* 语言无关:FastCGI是一套标准,理论上讲只要能进行标准输出(stdout)的语言都可以作为FastCGI标准的Web后端。
* Web Server隔离:FastCGI后端和Web Server运行在不同的进程中,后端的任何故障不会导致Web Server挂掉。
WSGI
WSGI (Python Web Server Gateway Interface, Python Web服务器网关接口)是一个Web服务器和Web应用程序之间的标准化接口规范,用于增进应用程序在不同的Web服务器和框架之间的可移植性。
当Web Server收到一个请求后,可以通过Socket把环境变量和一个Callback回调函数传给后端Web应用,Web应用在完成页面组装后通过Callback把内容返回给Web Server。
1 | def app(environ,start_response): |
这样做的优点有很多,异步化,通过Callback将Web请求的工作拆解开,可以很方便的在一个线程空间里同时处理多个Web请求。方便进行各种负载均衡和请求转发,不会造成后端Web应用阻塞。绝大部分的python web开发框架都遵守了这套标准(PEP3333)。
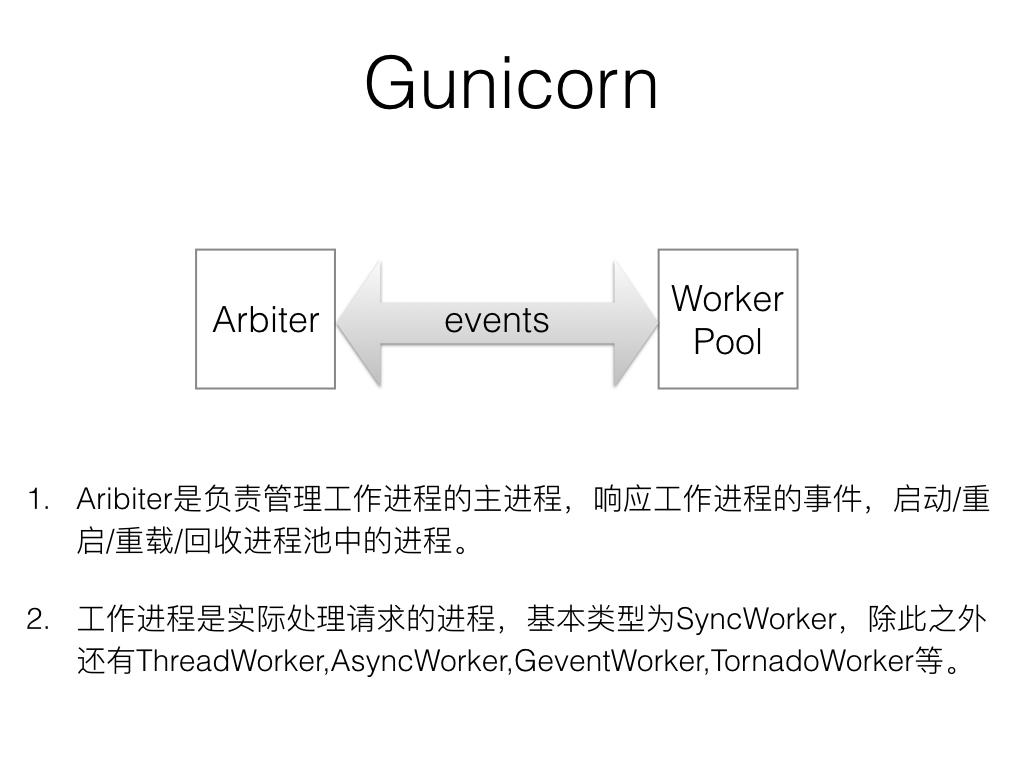
Gunicorn
Gunicorn是使用Python实现的WSGI服务器,直接提供了http服务,它采用pre-fork模型来处理和转发请求,并且在woker上提供了多种选择,gevent、eventlet这些都支持, 在多worker最大化里用CPU的同时,还可以使用协程来提供并发支撑, 对于网络IO密集的服务比较有利。
1 | gunicorn [OPTIONS] 模块名:变量名 |
- 常用配置参数:
- 指定一个配置文件(py文件)
-c CONFIG, --config=CONFIG - 与指定socket进行绑定
-b BIND, --bind=BIND - 以守护进程形式来运行Gunicorn进程,其实就是将这个服务放到后台去运行。
-D, --daemon - 工作进程的数量。gunicorn依靠操作系统来提供负载均衡,通常推荐的worker数量是:(2 x $num_cores) + 1
-w WORKERS, --workers=WORKERS - 工作进程类型. 包括 sync(默认), eventlet, gevent, or tornado, gthread, gaiohttp
-k WORKERCLASS, --worker-class=WORKERCLASS - 确认要写入Error log的文件FILE. ‘-‘ 表示输出到标准错误输出
--access-logfile FILE - 确认要写入Access log的文件FILE. ‘-‘ 表示输出到标准输出.
--error-logfile FILE, --log-file FILEpre-fork 模型
pre-fork 服务器会通过预先开启大量的进程,等待并处理接到的请求,所以能够以更快的速度应付多用户请求,在遇到极大的高峰负载时仍能保持良好的性能状态。
prefork工作模型,每个worker进程都是从master进程fork过来。在master进程里面,先建立好需要listen的socket之后,然后再fork出多个worker进程,这样每个worker进程都可以去accept这个socket( fork的进程空间是copy on write产生的,多个子进程会继承该文件描述符)
模拟用户请求过来的场景,当一个连接进来后,所有在accept在这个socket上面的进程,都会收到通知,而只有一个进程可以accept这个连接,其它的则accept失败。多个worker进程之间是对等的,他们同等竞争来自客户端的请求,各进程互相之间是独立的,worker进程的个数是可以根据cpu核数设置的。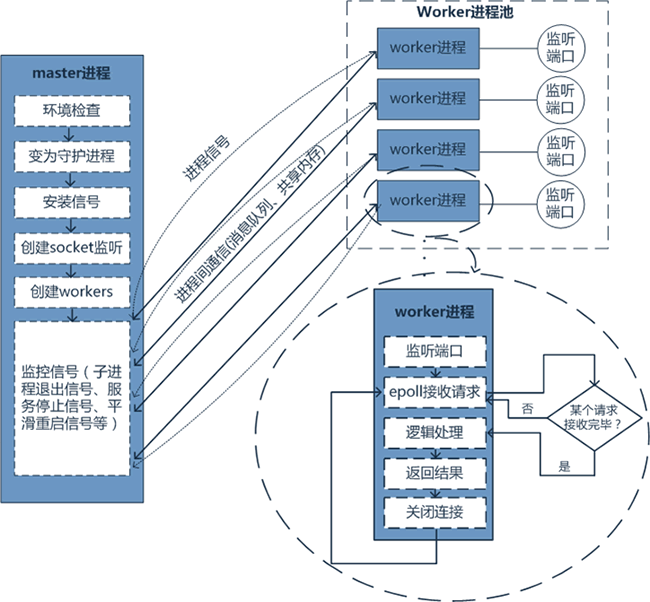
- 指定一个配置文件(py文件)
- 在gunicorn/arbiter.py代码中列举了相应的多个信号,针对不同信号的实现代码也定义在该文件:
- HUP,重启所有的配置和所有的worker进程
- QUIT,正常关闭,它会等待所有worker进程处理完各自的东西后关闭
- INT/TERM,立即关闭,强行中止所有的处理
- TTIN,增加一个worker进程TTOU,减少一个worker进程
- USR1,重新打开由master和worker所有的日志处理
- USR2,重新运行master和worker
- WINCH,正常关闭所有worker进程,保持主控master进程的运行
uWSGI
uWSGI是使用C写的,它的socket fd创建、worker进程的启动都是使用C语言系统接口来实现的,在worker进程处理循环中,解析了http请求后,使用python的C接口生成environ对象,再把这个对象作为参数塞到暴露出来的WSGI application函数中调用,而这一切都是在C程序中进行,只是在处理请求的时候交给application ,完全使用C语言实现的好处是性能会好一些。
除了支持http协议,uWSGI还实现了uwsgi协议,一般我们会在uWSGI服务器前面使用Nginx作为负载均衡,如果使用http协议, 请求在转发到uWSGI前已经在Nginx这里解析了一遍,转发到uWSGI又会重新解析一遍。uWSGI为了追求性能,设计了uwsgi协议,在Nginx解析完以后直接把解析好的结果通过uwsgi协议转发到uWSGI服务器,uWSGI拿到请求按格式生成environ对象,不需要重复解析请求,如果用Nginx配合uWSGI,最好使用uwsgi协议来转发请求。异步模型
在生产环境中的Python应用中有多线程,多进程,异步三种提高效率的方式,对异步方式来说,基于事件驱动的异步模型(IO多路复用模型,select,poll,epoll)对服务器的资源的有效利用率显然易见,并衍生了大量的异步网络框架。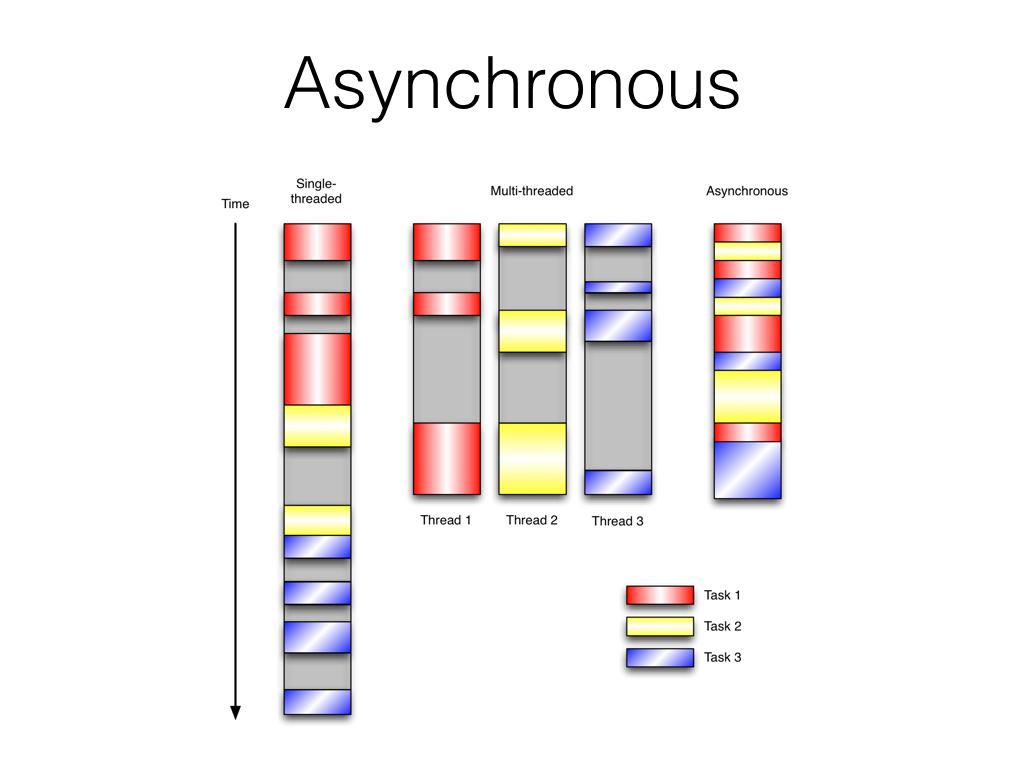
Twisted
- Twisted是一个基于Reactor模式(利用循环体来等待事件发生,然后处理发生的事件的模式)的异步IO网络框架。Reactor主要有如下两个功能:
- 监视一系列与你I/O操作相关的文件描述符(description)。监视文件描述符的过程是异步的,也就是说整个循环体是非阻塞的;
- 不停地向你汇报那些准备好的I/O操作的文件描述符。
Twisted就是基于Reactor模式帮我们抽象出了异步编程模型以及各种非阻塞的io模块(tcp、http、ftp等),使我们很方便地进行异步编程。
Tornado
Tornado在知乎广为使用,当你用Chrome打开网页版本的知乎,使用开发者工具仔细观察Network里面的请求,就会发现有一个特别的状态码为101的请求,它是用浏览器的websocket技术和后端服务器建立了长连接用来接收服务器主动推送过来的通知消息。这里的后端服务器使用的就是tornado服务器。Tornado服务器除了可以提供websocket服务外,还可以提供长连接服务,HTTP短链接服务,UDP服务等。Tornado服务器由facebook开源。
协程
协程占用内存小,用户主动控制退出,回调更优雅。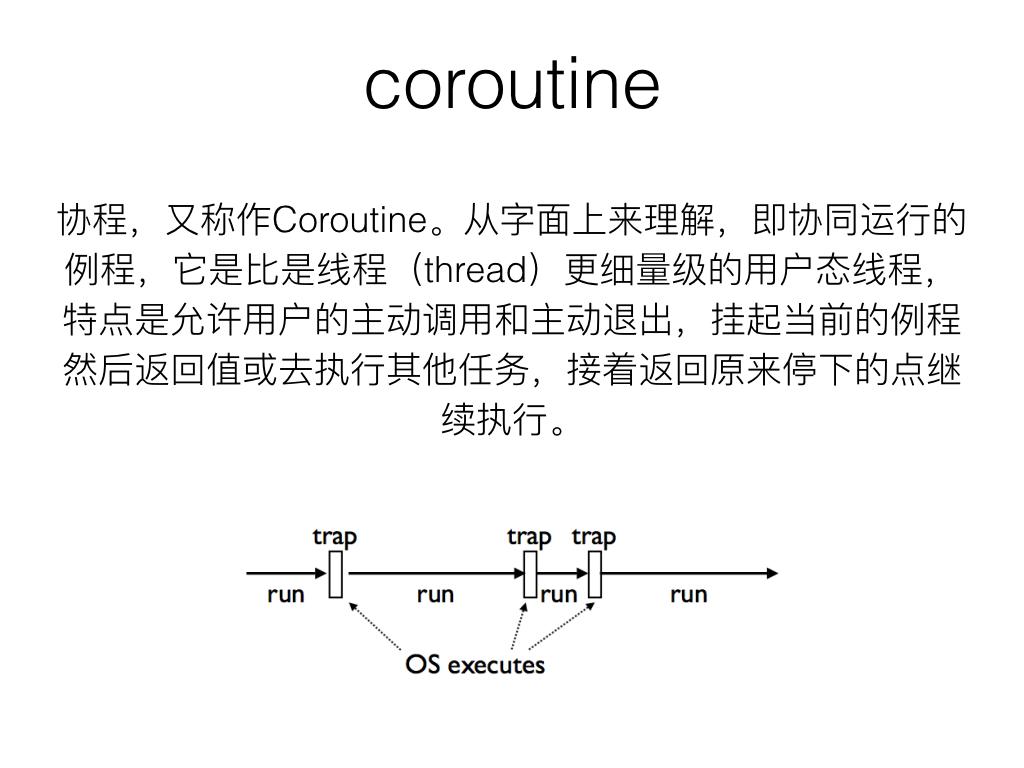
异步协程
生成器的进化
在 Python2.2 中,第一次引入了生成器,生成器实现了一种惰性、多次取值的方法,此时还是通过 next 构造生成迭代链或 next 进行多次取值。直到在 Python2.5 中,yield 关键字被加入到语法中,这时,生成器有了记忆功能,下一次从生成器中取值可以恢复到生成器上次 yield 执行的位置。之前的生成器都是关于如何构造迭代器,在 Python2.5 中生成器还加入了 send 方法,与 yield 搭配使用。
在 Python3.3 中,生成器又引入了 yield from 关键字,yield from 实现了在生成器内调用另外生成器的功能,可以轻易的重构生成器,比如将多个生成器连接在一起执行。这样不同的生成器之间可以互相通信,这样构造出的生成链更加复杂,但生成链最小组合子的粒度却精细至单个 yield 对象。
asynico.coroutine 与yield from
Python 3.4后出现了专门处理异步网络请求IO的标准库asyncio,并提供了一个默认的event loop。asyncio.coroutine 装饰器是用来将函数转换为协程的语法,只有通过该装饰器,生成器才能实现协程接口。使用协程时,你需要使用 yield from 关键字将一个 asyncio.Future 对象向下传递给事件循环,当这个 Future 对象还未就绪时,该协程就暂时挂起以处理其他任务。一旦 Future 对象完成,事件循环将会侦测到状态变化,会将 Future 对象的结果通过 send 方法方法返回给生成器协程,然后生成器恢复工作。虽然asyncio成为标准库,但它使用方法却较为复杂,不便于使用。
async/await
随后的Python 3.5后出现了协程语法糖async/await用以取代 asyncio.coroutine 与 yield from,从语义上定义了原生协程关键字,避免了使用者对生成器协程与生成器的混淆。
Gevent
因为tornado很多轮子不成熟,asyncio没有经历过大规模生产环境检验(Sanic , aiohttp ),故使用了Gevent处理一些并发请求问题,使用gunicorn+gevent成为常见的部署选择之一,Gevent基于Greenlet与Libev,greenlet是一种微线程或者协程,在调度粒度上比py3的协程更细。greenlet存在于线程容器中,其行为类似线程,有自己独立的栈空间,不同的greenlet的切换类似操作系统层的线程切换。
gevent monkey.patch_all,方便的导入非阻塞的模块,不需要特意的去引入。
参考链接
漫谈 Python 服务器编程
