探索在 Groq 上体验 Llama 3 的四种方式,包括 Web、移动端、API 及 LangChain 集成。了解 Groq LPU 如何实现 800 tokens/s 的超高速推理,大幅提升 AI 应用性能。
北京时间4月19日凌晨,Meta在官网上官宣了Llama-3,作为继Llama1、Llama2和CodeLlama之后的第三代模型,Llama3在多个基准测试中实现了全面领先,性能优于业界同类最先进的模型,你有没有第一时间体验上呢,这篇文章就分享下如何在Groq上以超过 800 tokens/s 的魔鬼推理速度体验Llama3,会同时分享Web端、移动端、API方式以及集成到LangChain中4种体验方案。
本文首发自个人博客 利用 Groq 体验 Llama3 的4种方式,800 tokens/s 的推理速度真的太快了!
Groq 有多快
先看两组数据
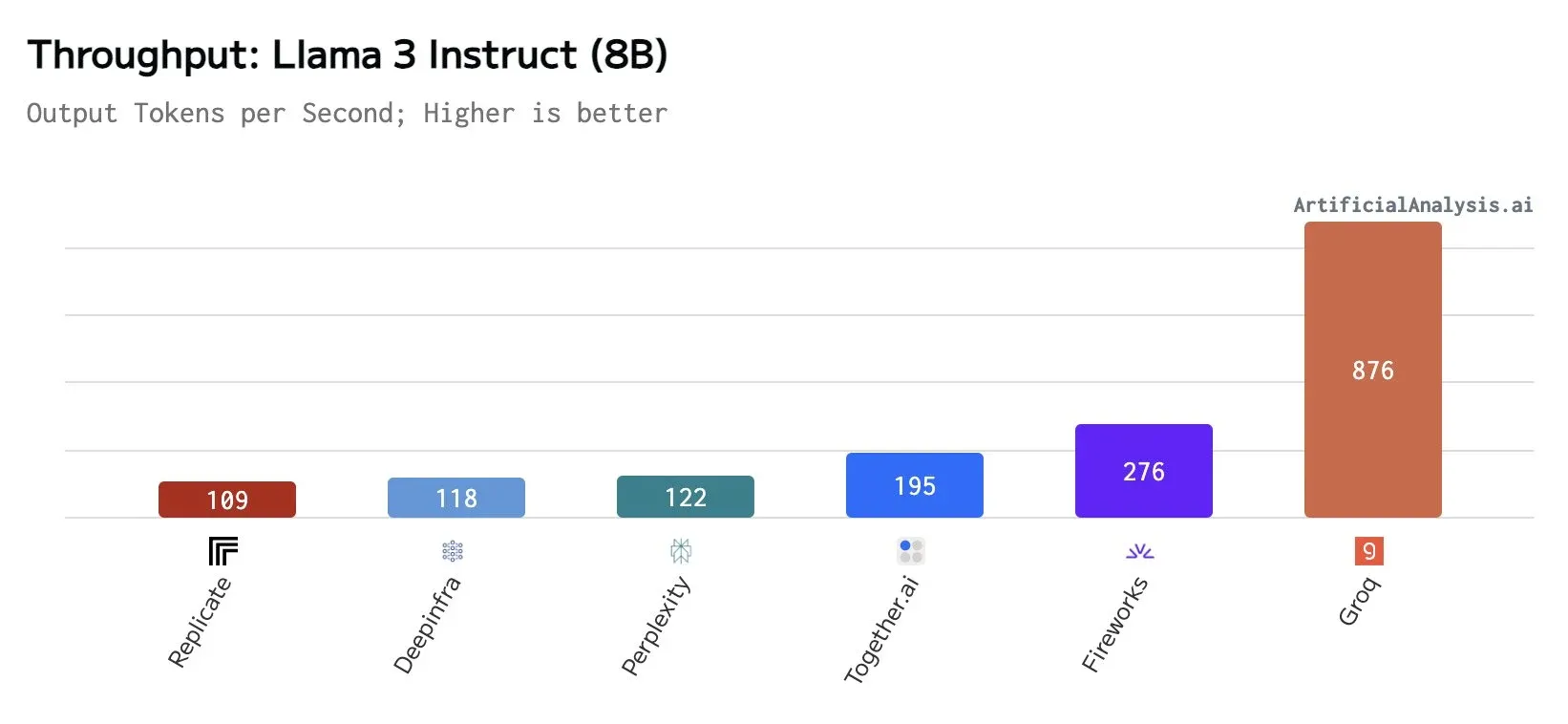
Llama3 8B 每秒钟 876 tokens 的输出速度,人眼基本跟不上模型的输出速度了,要知道 Llama3 8B 的质量与 GPT-3.5 和 Llama2 70B 相似,可以显著提升一些常见的 AI 应用场景的用户体验;RAG 的性能瓶颈不再是 LLM,而是 Retrieval,什么 HyDE(假设⽂档嵌⼊,利⽤ LLMs ⽣成假设性答案,以增强⽂档检索的准确性)、LLM 重排序器(对检索到的⽂档进⾏重排序,以优先选择最相关和上下⽂适当的信息)不再是 RAG 链路速度瓶颈…
初看数据,我以为是个噱头,本着务实的态度,我自己实际体验了一把,大家自己看 👇
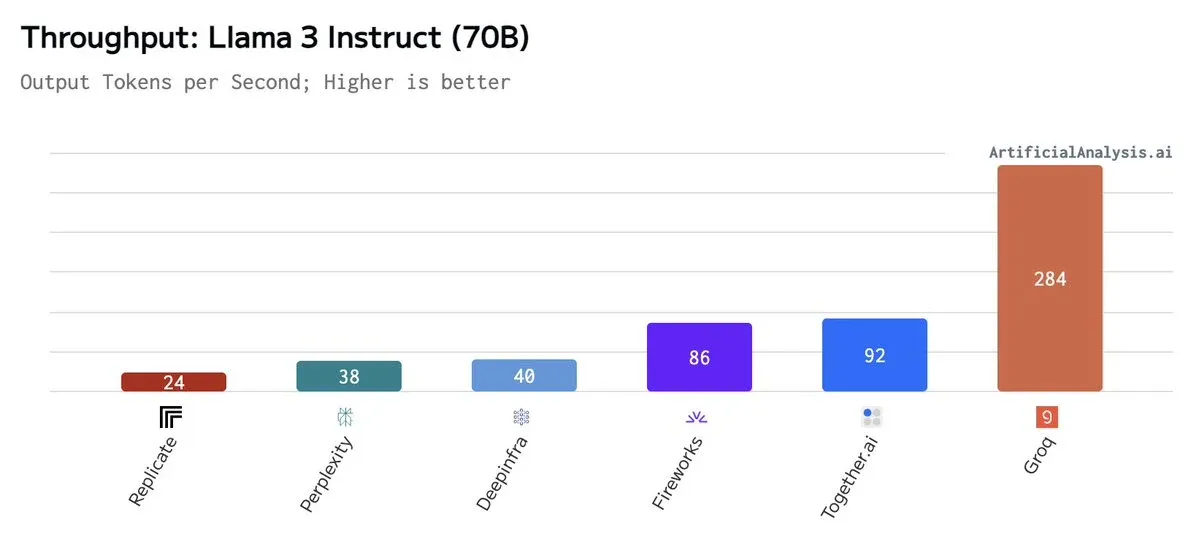
结果 Llama3 70B 的实际体验结果比测评数据还高。
Groq 为什么这么快
源于 Groq 开发出了一种新的 AI 处理器 ——LPU(Language Processing Unit),其推理速度相较于英伟达 GPU 提高了 10 倍。
- 专业优化:LPU 专门针对语言模型推理任务进行了优化,特别是在序列处理方面。
- 创新架构:LPU 采用了一种新的计算模式,能够高效地按顺序处理任务,而不是并行处理。
- 软件先行:Groq 在硬件开发前就创新了软件和编译器,以确保芯片间的高效通信。
- 内存与处理单元的整合:LPU 的设计使得数据流局部性得到更好的利用。
- 针对性能和成本的优化:LPU 在设计时就注重了性能提升和成本降低。
详细科普请前往这里查看
4 种 Groq 体验方案
1. Web 端
无需登录,即可直接在网页版进行尝试,地址指路 👉groq.com,当前支持的模型有 Llama3 8B-4k 、 Llama3 70B-8k 、 Llama2 70B-8k 、 Mixtral 8X7B-32k 、 Gemma 7B-it
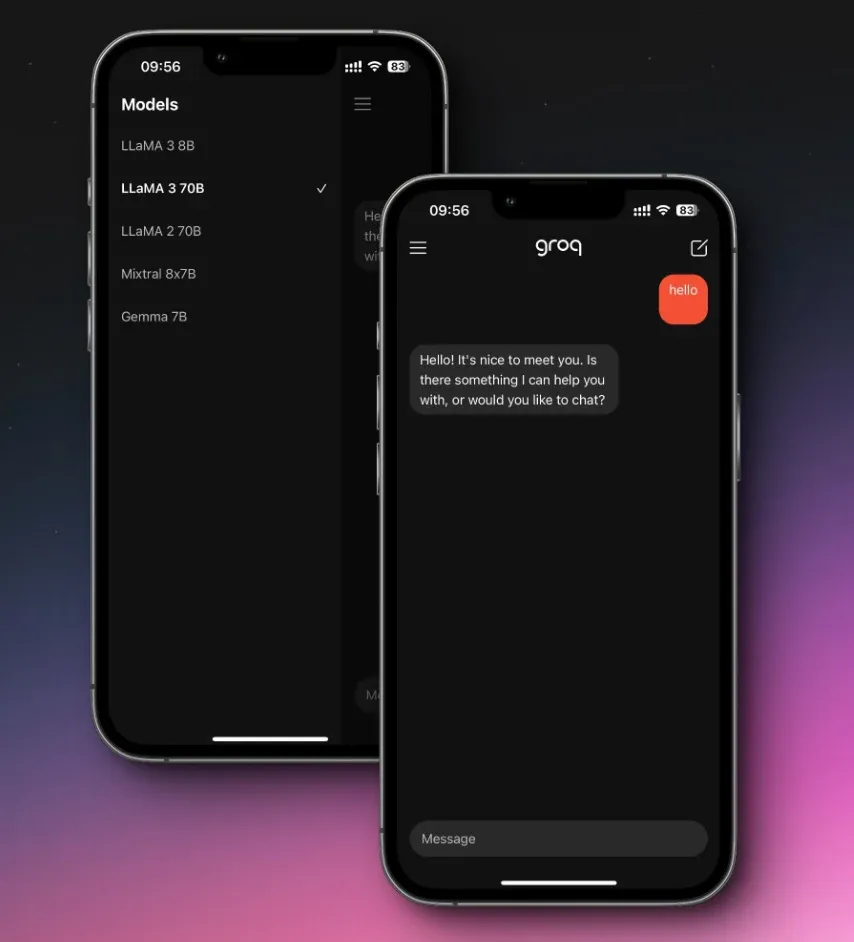
2. 移动端
Gorq 的 iOS 应用已经推出,目前不需要登录即可使用,通过下面的 TestFlight 安装地址:testflight.apple.com,支持的模型有 Llama3 8B 、 Llama3 70B 、 Llama2 70B 、 Mixtral 8X7B 、 Gemma 7B
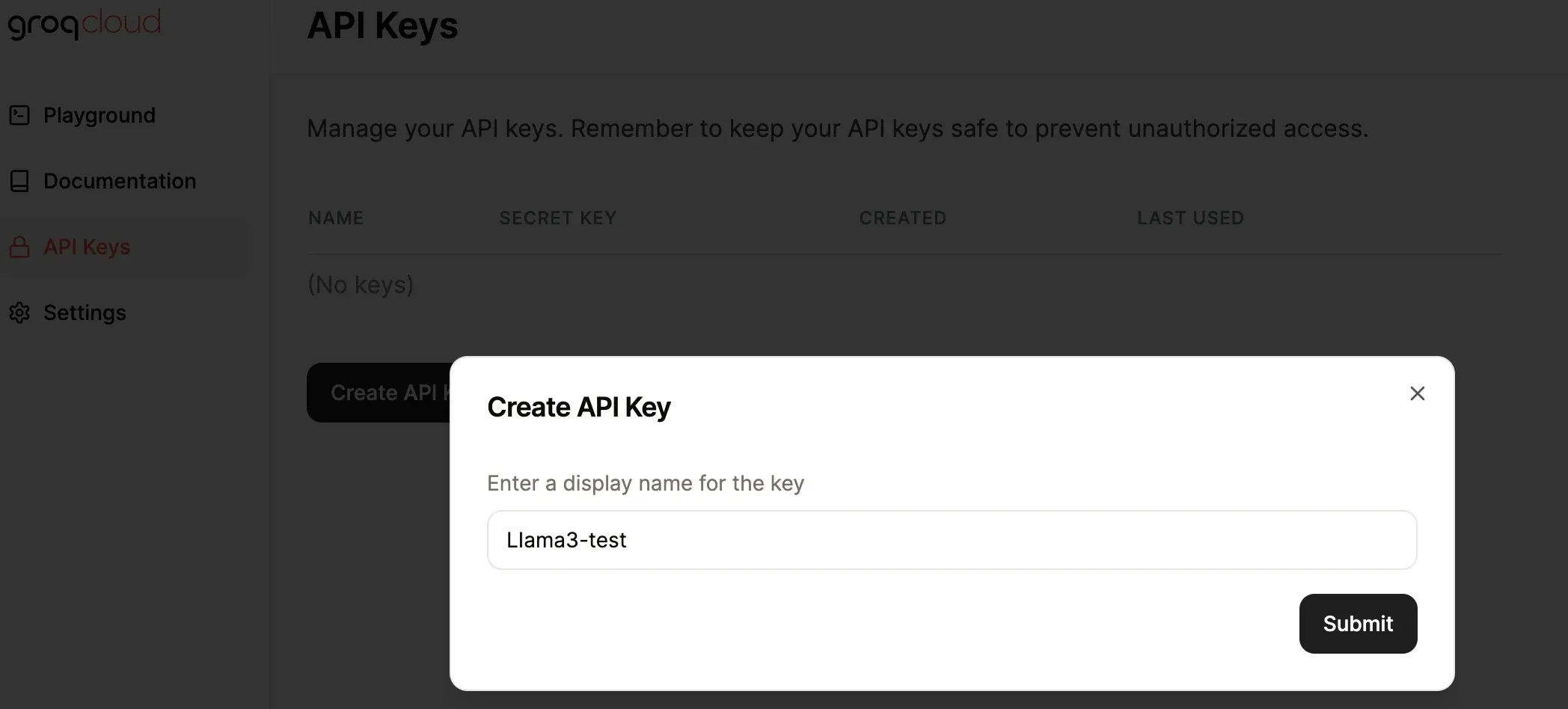
3. API 调用
先前往这个地址 https://console.groq.com/keys 申请好 API-KEY。
安装依赖库
pip install groq
调用
import os
from groq import Groq
client = Groq(
api_key=os.environ.get("GROQ_API_KEY"),
)
llm = client.chat.completions.create(
messages=[
{
"role": "user",
"content": "编写一篇中国神话故事,篇幅500~800字,必须使用中文输出",
}
],
model="llama3-70b-8192",
)
print(llm.choices[0].message.content)4. LangChain 中使用
安装依赖库
pip install langchain-groq
使用
from langchain_core.prompts import ChatPromptTemplate
from langchain_groq import ChatGroq
llm = ChatGroq(temperature=0, model_name="llama3-70b-8192")
human = "{text}"
prompt = ChatPromptTemplate.from_messages([("human", human)])
chain = prompt | llm
response = chain.invoke({"text": "编写一篇中国神话故事,篇幅500~800字,必须使用中文输出"})
print(response.content)更多体验方式
如果由于网络原因你还是无法访问,请使用我在这篇文章推荐的5 个免费稳定的 Llama 3 在线体验地址