Vol.2:开源模型与闭源模型之间的差距有多大?
大家好,Weekly Gradient 第 2 期内容已送达!开源模型部署需要的硬件配置,16 位浮点精度(FP16)的模型,推理所需显存(以 GB 为单位)约为模型参数量(以 10 亿为单位)的两倍,据此,Llama 3 7B(70 亿)对应需要约 14GB 显存以进行推理(以普通家用计算机的硬件规格作为参考,一块 GeForce RTX 4060 Ti 16GB 显卡市场价超过 3000 元)。模型量化(quantization)技术可以很大程度上降低显存要求,以 4-bit 量化为例,其将原本 FP16 精度的权重参数压缩为 4 位整数精度,使模型权重体积和推理所需显存均大幅减小,仅需 FP16 的 1/4 至 1/3,意味着约 4GB 显存即可启动 7B 模型的推理(实际显存需求会随着上下文内容叠加而不断增大)…
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
大海捞针法:大模型 Long Context 能力照妖镜:国外开发者 Greg Kamradt 最早设计了测评方法 Needle in A HayStack(中文称为 “大海捞针”,一段关键 信息文本(针)被放置在一个冗长的干扰文档(海)中,模型的任务是检索这个隐藏的关键信息,这是 Kimi 官方的测试),用于测试长上下文 LLMs 的上下文检索能力,但此方法采用的是相对简单的检索任务,为此来自复旦大学自然语言处理实验室的这篇论文提出了一个更全面的基础测试,姑且称为“增强版大海捞针法”(从简单的事实检索转移到更具挑战性的阅读理解任务,“针”代表包含答案的文档,而“海”则包含分散注意力的文档,模型必须找到分散在海中的一个或多个相关文档,并从中推断出正确的答案),即不光测试 LLMs 长上下文检索能力,还测试了 LLMs 整合检索到的内容并生成有效答案的能力,更符合真实使用场景。#Long Context #LLM 评测
这里是实验数据集和测评结果的说明,当前业界顶流的闭源模型 OpenAI GPT-4 128K 在单文档和多文档 QA 上平均准确率分别为 62.00%和 50.37%,Claude 2.1 200K 在单文档和多文档 QA 上平均准确率分别为 43.80%和 43.78%,不过这也和提示词设计、问题设置是否有歧义相关,不过实验设计总体上很严谨了。所以前段时间资本市场上所谓 kimi 引爆大模型“长文本竞赛”,大家心里还是要有一杆秤,第一,真正做到长上下文的,实际场景效果也是打折的;第二,还有几家厂商是在浑水摸鱼,明明就是 RAG,非说自己是基础模型具备长上下文能力……
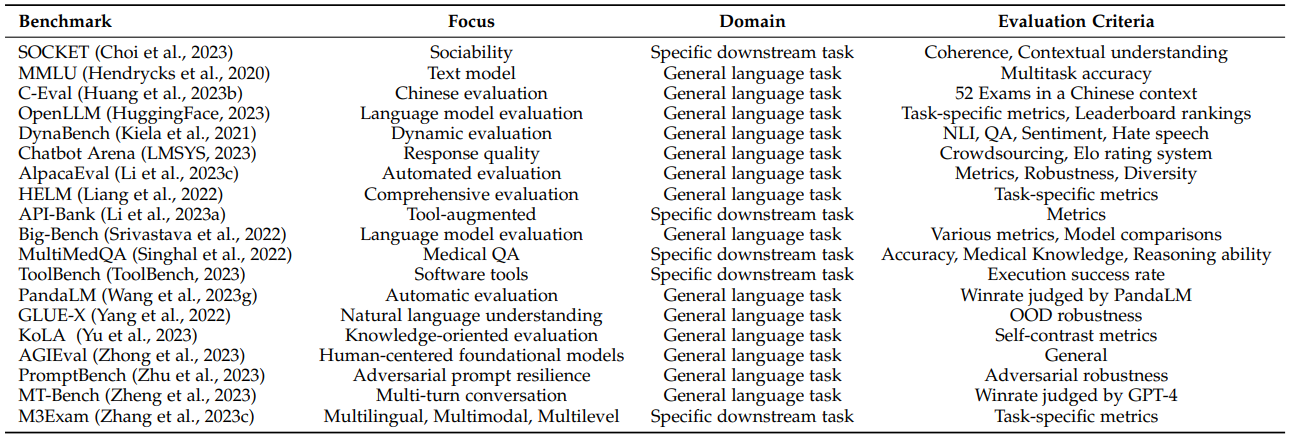
大型语言模型评估调查:这是一篇介绍大模型评测领域的综述性论文,一共调研了 219 篇文献,以评测对象 (what to evaluate)、评测领域 (where to evaluate)、评测方法 (How to evaluate)和目前的评测挑战等几大方面对大模型的评测进行了详细的梳理和总结。首先,测评有助于指标化理解大模型的长处和短处,其次,研究评测可以人与模型的协同交互提供指导和帮助,最后,评测可以规划大模型未来的发展演变、防范风险,这篇论文总结了 19 个流行的基准测试(主要分为通用基准和具体基准),每个基准关注的领域任务也不同,比如自然语言处理、偏见和真实性、医学应用、代理应用能力等。# LLM 评测
微软亚洲研究院还专门写了一篇博客对论文进行了深入解读,推荐阅读。
这篇论文其实都是大半年前的了,之所以写在这里,是因为本周 Llama 3 正式发布,想来谈谈到底怎么看待模型能力。相对靠谱一点的媒体还会发一些测试集得分来印证能力有多强,但我一直的观点是,模型能力怎么样是一个“小马过河”的问题,首先一定要自己上手试一试,然后顺着自己关注的模型能力侧重点再去看测试集分数,比如做 Agent,我就比较关注 LLMs 使用外部工具能力,那需要看看 API-Bank 测试集分数有没有公布,和业界靠前的模型比较起来差多少,如果没有,按照测试流程自己跑一个出来,目前没有模型是六边形战士(开源、工具调用、中英文能力、使用成本等),所以每当一个有影响力的新模型出来,整体能力毫无疑问是在提升,但是还是要从“是不是用起来更好”出发。
RAG 检索到的信息和 LLMs 内部先验知识之间孰强孰弱?:这篇论文探讨了检索增强生成(RAG)在与大型语言模型(LLMs)结合使用时的可靠性问题,它研究了当 LLM 单独给出错误答案时,提供正确的检索内容是否总能修正错误;反之,如果检索内容错误,LLM 是否能识别并忽略错误信息,还是会继续犯同样的错误。这涉及到分析 LLM 内部知识(即其先验知识)与检索到的信息之间的冲突。论文的主要结论:
提供正确的检索信息可以修正大多数模型错误(准确度达到 94%)
当参考文档中的信息被错误地修改时,如果 LLM 的内部先验较弱,则更可能重复错误的修改信息;如果先验较强,则更具抵抗力
修改信息与模型先验的偏差越大,模型越不可能偏好该信息
提示词设计(严格遵循或宽松判断)会影响 LLM 对 RAG 信息的选择偏好
工程
浅谈 LLM RAG 对话机器人和 Text2SQL 的设计和实现:AWS 官方博客分享了一篇深入解析大语言模型(LLM)在构建对话机器人和 Text2SQL 应用中的设计与实现的文章。内容涵盖了 LLM 的基本原理、开源与商业模型的对比、推理方式以及模型适配等关键技术点,特别强调了提示语工程的重要性和 LLM 项目实施中的预期控制。#Text2SQL
sparrow:基于 Unstructured 实现的 RAG 数据预处理方案,支持从各种文档、PDF、图像中提取数据,无缝处理表单、发票、收据和其他非结构化数据,可以和 LlamaIndex、Haystack等比较热门的 LLM 中间件框架集成。#RAG #ETL
和之前国内团队开源的RAGFlow其实差不多,聚焦在文档处理,但不是端到端。这个其实是当前 RAG 系统构建的难点,非结构化数据预处理+构建索引,在已经有这么多开发者社区活跃的的开源 LLM 中间件框架情况下,从头再搞一个 all-in-one 框架其实挑战性很大,但是从一个环节出发,以插件的形式支持这些框架,吸引开发者,然后慢慢发展为一个 Micro-SaaS 服务机会很大,比如Mathpix(通过 OCR 技术识别公式,可以快速准确地将数学公式截图和手写公式转换为 LaTeX 格式,无论是行间公式还是行内公式都可以准确识别,支持多国语言;可以识别图片或 pdf 文件中的表格,并输出 TSV(制表符分隔值)格式,可以直接将结果粘贴到 Excel 等电子表格中,解决了从扫描文档中提取表格数据的问题;可以直接将 pdf 转换为 LaTeX、Word、HTML 等易于编辑的格式),沉浸式翻译、谷歌 Bard 等都调用了它的服务。
Reader:jina-ai 出品的网页内容抓取工具,输入网页地址后,可以清理和格式化对应页面内容,输出纯文本。#RAG #ETL
这个工具的口号是将任何网页 URL 转换成对大语言模型友好的输入格式,实则就是将在线网页富文本内容转化为纯文本内容,比如如果有图片,就会转换为图片的描述。这一类抓取 URL,转换为纯文本的工具有很多, webscraper、code-html-to-markdown(偏向于更好地处理代码块)、MarkdownDown、gpt-api、web.scraper.workers.dev,firecrawl,自己部署后,作为大模型获取在线内容的插件还是不错的,也和 sparrow 一样,属于数据预处理环节的工具。
api-for-open-llm:为自主部署的开源大模型实现统一的后端接口,接口调用和响应格式兼容 OpenAI API ,这个项目的核心就是 FastAPI (Web 框架)+ vLLM(推理框架)写了一套 OpenAI 兼容 API,确实为他人节省不少时间。#OpenAI API
对于想在线部署开源模型使用,但又不想折腾应用层接入逻辑的朋友来说,这个库值得尝试,模型调用逻辑的代码基本不用改,换个模型名称和 API 路径就可以快速切换了。
产品
AI 硬件 Limitless 吊坠:Rewind 宣布更名 Limitless,并推出全新硬件 Limitless 吊坠(硬件售价 99 美元,大陆购买运费+税费约 30 美元,比起 AI Pin 699 美元和Rabbit R1 199 美元,便宜不少),因为主要是录音,功耗也相对较小,可以待机 100 小时,可通过 USB-C 充电,可以配合软件使用。软件部分提供无限音频存储和每月免费 10 小时的 AI 功能,如转录、摘要和笔记,而无限 AI 功能需要付费解锁,按月付费每月 29 美元,按年付费则每月 19 美元,想要构建效果出色的 AI 个人助理,采集的数据越丰富越好,线下场景的数据收集必不可少,但这种硬件涉及到的数据十分敏感,隐私安全尤为重要。当前也有类似的开源项目Adeus、01 Light提供软硬件一体的方案。
AI 搜索引擎这类产品,凭借 Perplexity AI 拿到英伟达、贝索斯等高额融资引爆市场,对标 AI 搜索时代的谷歌,拔高了这个赛道的天花板。开源方面:
morphic:支持生成式 UI 的 AI 搜索引擎,支持了地图 + 位置、股票图表甚至电商购物信息的可视化展示
-
商业化产品:
在用户体验上确实是一种极大的进步,也符合搜索的意图,直接给出答案,并支持进行下一步追问,而不是一些像传统搜索给出一串带关键字的网页链接。不过当前问题是 AI 搜索引擎的成本会比传统的搜索引擎成本高很多,Perplexity 2023 年 5 亿次搜索的成本大约在几千万美金,他们的 ARR 应该是无法覆盖这个成本的,需要更多的商业化尝试,比如已经计划引入广告;而且原始网页索引阶段还是用的谷歌 API,并且模型在如何更准确、有侧重点的组织网页内容来匹配搜索意图,依然也是一个很大的挑战。
市场
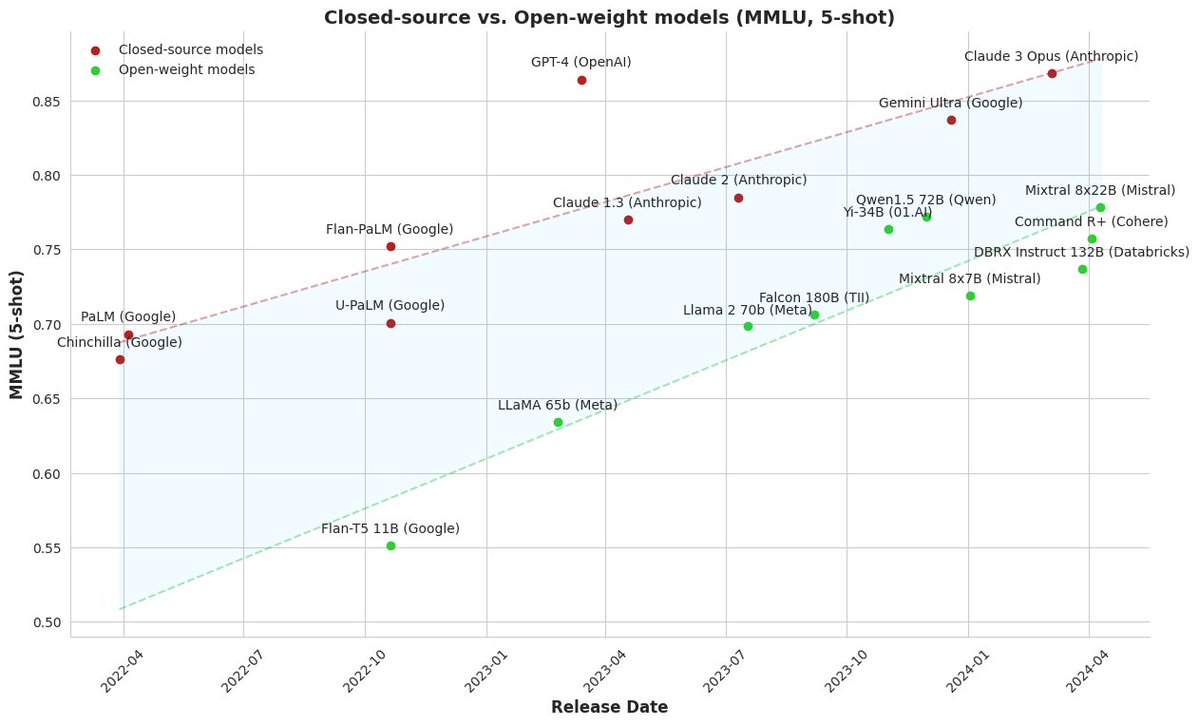
这里是关于 Chatbot Arena评测平台的介绍
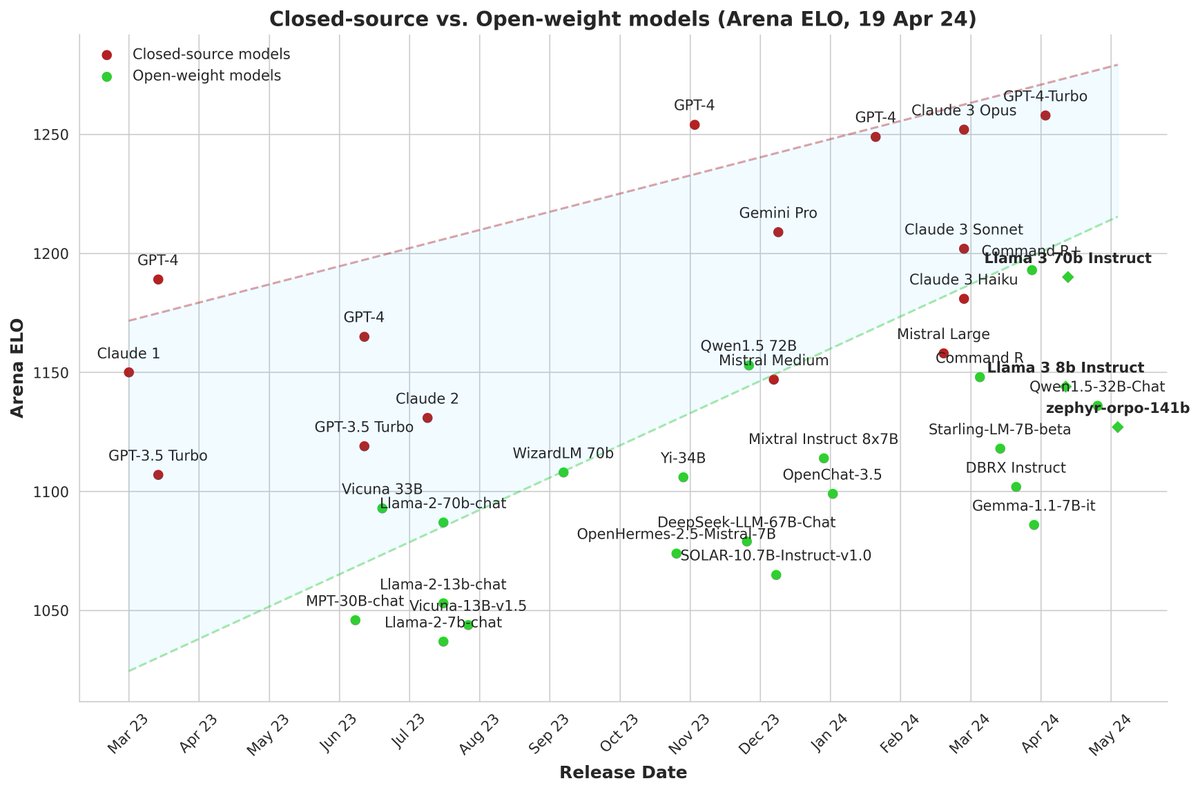
AGI 大基建与马拉松:2024 Q1 全球大模型的前沿手记:拾象科技 CEO 李广密的采访文字稿,提供了基本上完整的海外 AI 大模型的竞争和数据视角,不管是作为走在技术最前沿的关注者与投资者,还是站在最先端参与者角度来进行的深度思考,技术理解度都没的说。不过关于开源和闭源,在上次采访中,他认为开源永远追不上闭源,但本期节目,由于 xAI 和 Mata 的开源策略,观点有些微妙变化。
对话 MiniMax 闫俊杰:AGI 不是大杀器,是普通人每天用的产品:晚点对 MiniMax 创始人的采访,特别要说明的是,ChatGPT 还没发布,MiniMax 就已经在做了,我当时也是从 Glow (角色扮演、情感陪伴类)这款现象级产品了解到的。闫俊杰认为真正的人工智能(AGI)应该是普通人每天使用的产品,而非遥不可及的技术。他强调了技术和产品并重的重要性,并分享了 MiniMax 在大模型领域的冒险和创新,推荐阅读采访原文逐字稿。摘录一些很精彩的观点如下:
- “AGI 不是大杀器,是普通人每天用的产品。” —— 闫俊杰对 AGI 的应用前景的看法,强调了技术的普及性和实用性。
- “如果没有产品承接,即使你有一个技术进展,它最终也不是你的。” —— 强调了技术与产品结合的重要性。
- “我们最开始对 AI 产品的想象是一个同时有声音、形象、文字能力的智能体。” —— 描述了 MiniMax 早期对 AI 产品的愿景。
- “我们有一句话,Intelligence with everyone,我们并不是这个技术的 owner。” —— 闫俊杰对 MiniMax 使命的阐述,强调技术的普惠性。
观点
本周 AI 圈最重磅的新闻就是 Llama 3 发布了,在本期观点里,我想谈下在本地(普通家用计算机)运行开源模型的一些配置要求,以及我正在使用的一些开源模型,最后也会推荐一些稳定的 Llama 3 在线体验地址。
根据经验,16 位浮点精度(FP16)的模型,推理所需显存(以 GB 为单位)约为模型参数量(以 10 亿 为单位)的两倍,据此,Llama 3 7B(70 亿)对应需要约 14GB 显存以进行推理(以普通家用计算机的硬件规格作为参考,一块 GeForce RTX 4060 Ti 16GB 显卡市场价超过 3000 元)。模型量化(quantization)技术可以很大程度上降低显存要求,以 4-bit 量化为例,其将原本 FP16 精度的权重参数压缩为 4 位整数精度,使模型权重体积和推理所需显存均大幅减小,仅需 FP16 的 1/4 至 1/3,意味着约 4GB 显存即可启动 7B 模型的推理(实际显存需求会随着上下文内容叠加而不断增大)。
所以本地部署建议以 int4 部署,大小低于 40B 的模型,部署工具可以采用Ollama、lmstudio,带有 UI 界面,可以快速在本地跑起来,其他开源模型直接使用网页版或者购买 GPU 服务的方式体验,购买 GPU 部署推理服务时,选用Text Generation Inference(简称 TGI,是 HuggingFace 推出的一个项目,作为支持 HuggingFace Inference API 和 Hugging Chat 上的 LLM 推理的工具,旨在支持大型语言模型的优化推理)或 vLLM (被用于 Chatbot Arena 和 Vicuna 大模型的服务后端)作为推理框架。
开源模型选用方面,做 RAG、Agent、FunctionCalling 测试使用 Cohere 的大模型 Command R+(现在可以用 Meta 最新的 Llama3-70B 了),配合完全本地化的AI 搜索引擎(不需要百度或者谷歌的 API Key,也不需要任何一家大模型服务的 API Key),在中文写作方面 Qwen-72B,语言表达更地道一些,特定任务的小参数微调 base 模型用 Llama3-8B 或 Mistral-7B,代码生成和 text2sql 等编程类任务使用 deepseek-coder-33B 或 StarCoder-15B 作为微调 base 模型,模型我托管在 GPU Serverless 服务 Replicate 上。
一些稳定的 Llama 3 在线体验地址:
- 英伟达开发者:build.nvidia.com
- Hugging Face:huggingface.co
- llama2AI: www.llama2.ai
- MetaAI:www.meta.ai
- Replicate:llama3.replicate.dev
Vol.2:开源模型与闭源模型之间的差距有多大?
