使用 OpenAI GPT-4o 和 LangGraph,构建一个高效的研究报告 AI Agent。文章详细介绍多智能体系统设计与 GPT Researcher 机制,提升 AI 应用开发能力。
在上一篇文章,分享了使用 DeepSeek-V2+LangGraph 编写了一个编码助手类 AI Agent ,这篇文章使用 OpenAI 最近上新的 GPT-4o,结合 LangGraph 编写一个能够撰写高质量研究报告的多智能体系统,实现机制参考 gpt-researcher,我会首先介绍下 gpt-researcher 这个项目的工作机制,然后使用 LangGraph 逐步进行实现。
LangGraph 是什么
LLM 应用构建方式先后经历了 zero-shot(零提示) or few-shot (少样本提示)、function calling(函数调用)、RAG (检索增强生成),直到现如今的agentic workflows(代理工作流) (也叫flow engineering,流程工程),吴恩达也曾公开表示:“我认为 AI 代理工作流将在今年推动大规模的 AI 进展,甚至可能比下一代基础模型更多。这是一个重要的趋势,我建议所有从事 AI 工作的人都关注一下。” 而 LangGraph 作为 LangChain 的扩展组件,就是为了适应这一趋势,旨在创建代理和多代理流程,它增加了创建循环流程的能力,并且具有内置记忆功能,这两个都是创建代理所必需的重要属性。LangGraph 为开发者提供了高度可控的能力,能够灵活地创建任意定制代理,对于创建自定义代理和流程至关重要,关于 LangGraph 的详细介绍,请看这篇 👉使用 LangGraph 编写了一个编码助手类 AI Agent。
GPT Researcher 是什么
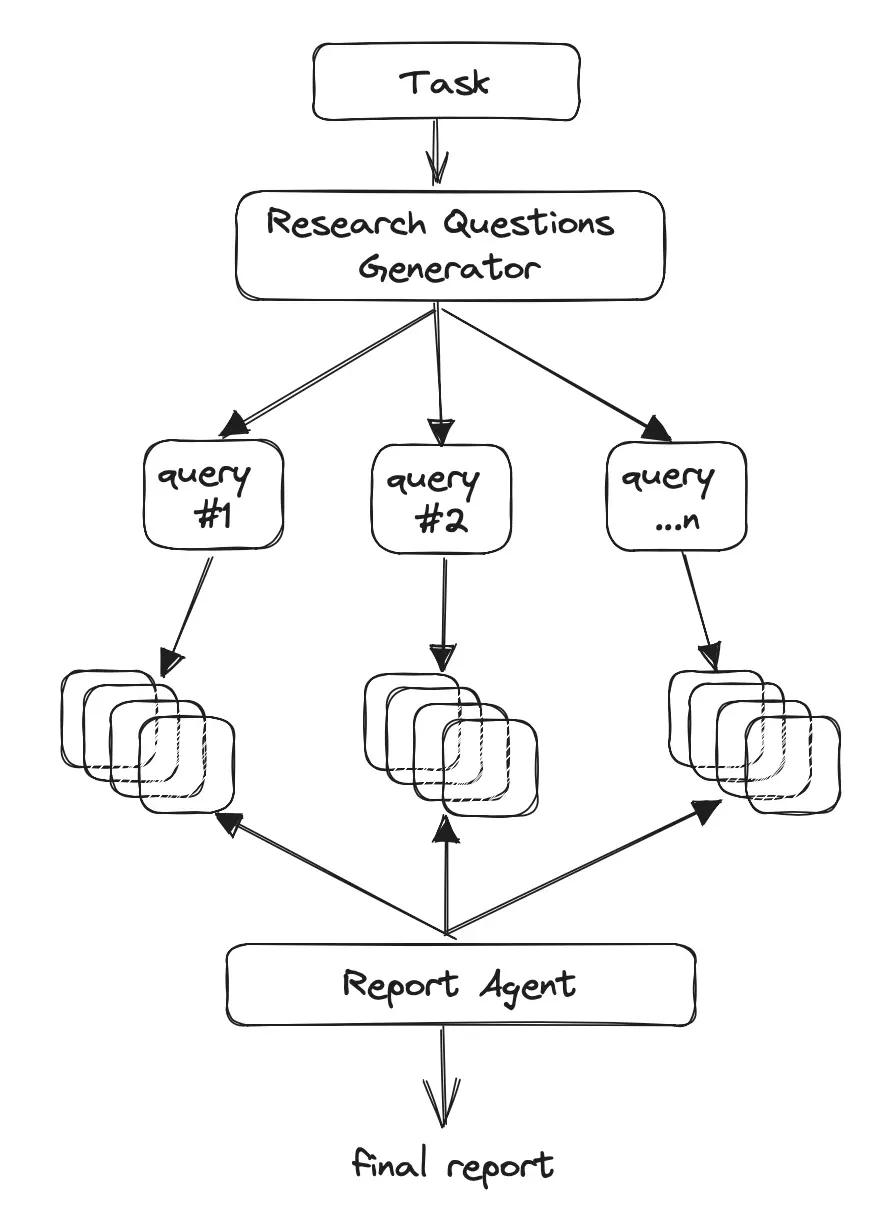
GPT Researcher 是一个多代理系统,专为各种任务的综合在线研究而设计,代理可以生成详细、正式且客观的研究报告,并提供自定义选项,专注于相关资源、结构框架和经验报告。主要思想是运行“计划者”和“执行”代理,而计划者生成问题进行研究,“执行”代理根据每个生成的研究问题寻找最相关的信息。最后,“计划者”过滤和聚合所有相关信息并创建研究报告。具体工作流程如下:
- 根据研究搜索或任务创建特定领域的代理。
- 生成一组研究问题,这些问题共同形成答案对任何给定任务的客观意见。
- 针对每个研究问题,触发一个爬虫代理,从在线资源中搜索与给定任务相关的信息。
- 对于每一个抓取的资源,根据相关信息进行汇总,并跟踪其来源。
- 最后,对所有汇总的资料来源进行过滤和汇总,并生成最终研究报告。
LangGraph 实现方案
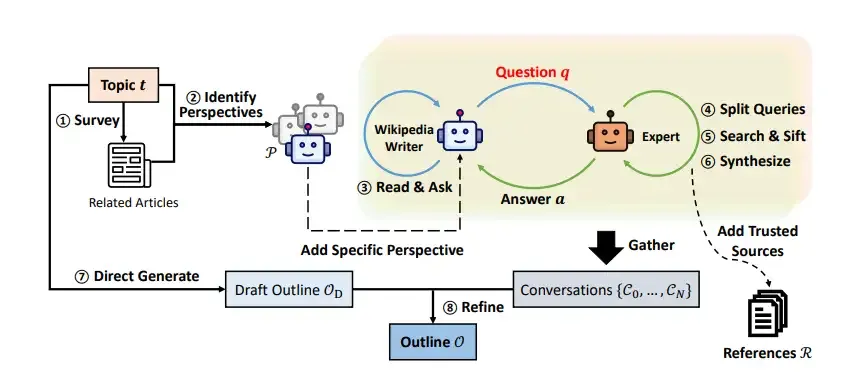
可以发现,GPT Researcher 主要由两个代理组成,为了提高生成的报告内容的质量,这里参考论文使用大语言模型从零开始协助撰写类似维基百科的文章的思路(这篇论文探讨了如何利用大型语言模型从头开始撰写有根据且结构化的长篇文章,其广度和深度与维基百科页面相当。这个问题尚未得到充分研究,但在写作前的阶段提出了新的挑战,包括如何研究主题并制定提纲。作者提出了 STORM,一个通过检索和多角度提问合成主题提纲的写作系统。STORM 通过发现研究给定主题的不同视角、模拟作者基于可信的互联网来源向话题专家提出问题的对话,以及 curated 收集的信息来创建提纲,来模拟写作前的阶段。为了评估,作者整理了 FreshWiki,一个最近的高质量维基百科文章数据集,并制定了一个评估提纲阶段的评估指标。他们还收集了经验丰富的维基百科编辑的反馈。与基于提纲驱动的检索增强型基线生成的文章相比,更多的 STORM 文章被认为是有组织的。专家反馈还帮助识别了生成有根据的长文章的新挑战,例如源偏见转移和无关事实的过度关联。)
这里进一步细化代理的职责,我们定义 7 个具有不同专业技能的代理用于提高研究过程的深度和质量:
- Chief Editor (主编):负责监督研究过程并管理团队,作为协调其他代理的“主”代理,充当 LangGraph 主接口。
- GPT Researcher(GPT 研究员):一个专业代理,对给定主题进行深入研究。
- Editor(编辑): 负责规划研究大纲和结构。
- Reviewer (审稿人):根据一套标准验证研究结果的正确性。
- Reviser (修订者):根据审稿人的反馈修订研究结果。
- Writer(撰稿人):负责编写最终报告。
- Publisher(发布者):负责以各种格式发布最终报告。
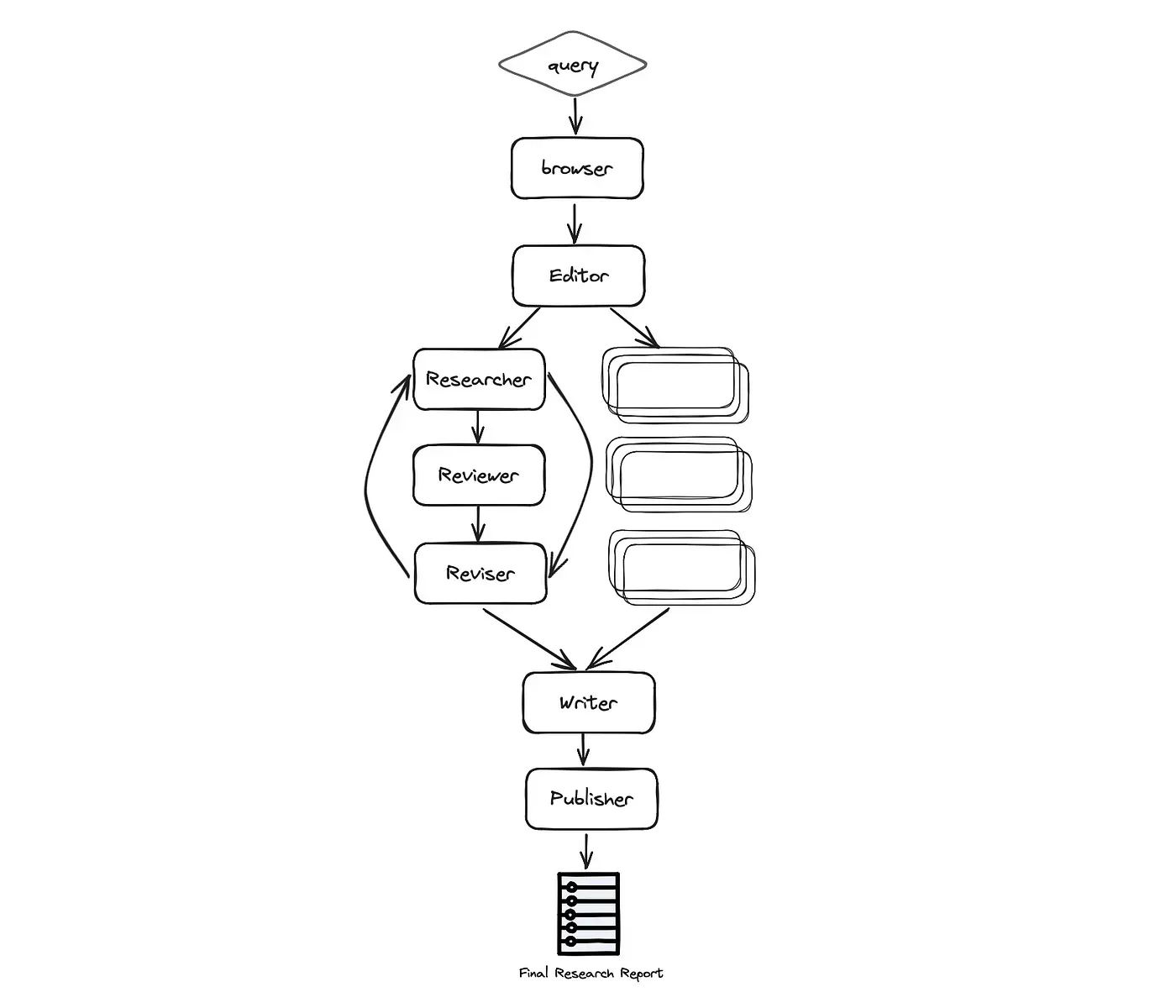
自动化过程包括以下阶段:规划研究、数据收集和分析、审阅和修订、编写报告,最后是发布,详细解释如下:
- Browser (gpt-researcher) : 浏览网络,根据给定的研究任务进行初步研究。这一步对于计划研究过程至关重要,可以根据最新和相关的信息规划研究过程,而不仅仅依赖于预先训练的数据来完成特定任务或主题。
- Editor:根据初步研究,规划报告的大纲和结构,编辑还负责根据计划的大纲触发并行研究任务。
对于每个大纲主题(并行进行):
- Researcher (gpt-researcher) :对子主题进行深入研究并撰写草稿,这个代理底层封装了 GPT Researcher 项目。
- Reviewer:根据一组准则验证草稿的正确性,并向修订者提供反馈(如果有)。
- Reviser :根据审阅者的反馈修订草稿,直到满意为止。
- Writer: 编写最终报告,包括引言、结论和参考文献部分,根据给定研究结果。
- Publisher : 将最终报告发布为 PDF、Docx、Markdown 等多种格式。
1. 定义 StateGraph
在 LangGraph 中,状态是通过一种结构化方法来实现的,开发人员定义了一个 GraphState 来封装应用的整个状态。图中的每个节点都可以修改这个状态.
class ResearchState(TypedDict):
# 研究任务
task: dict
initial_research: str
sections: List[str]
research_data: List[dict]
# 报告布局
title: str
headers: dict
date: str
table_of_contents: str
introduction: str
conclusion: str
sources: List[str]
report: str
2. 初始化 Researcher(GPT 研究员)
创建了一个 Research 代理
from gpt_researcher import GPTResearcher
class ResearchAgent:
def __init__(self):
pass
async def research(self, query: str):
# 初始化研究员
researcher = GPTResearcher(parent_query=parent_query, query=query, report_type=research_report, config_path=None)
# 对给定查询进行研究
await researcher.conduct_research()
# 撰写报告
report = await researcher.write_report()
return report
async def run_initial_research(self, research_state: dict):
task = research_state.get("task")
query = task.get("query")
print_agent_output(f"Running initial research on the following query: {query}", agent="RESEARCHER")
return {"task": task, "initial_research": await self.research(query=query, verbose=task.get("verbose"))}类似的,其他代理也使用上述方式声明,完整代码后台回复 DeepSeek 获取,
3. 初始化 Research Team(研究团队)
然后初始化整个研究团队:
class ChiefEditorAgent:
def __init__(self, task: dict):
# 使用当前时间(以秒为单位)作为任务ID,也可以是任何唯一的标识符
self.task_id = int(time.time())
# 创建一个输出目录,名称基于任务ID和查询的前60个字符
self.output_dir = f"./outputs/run_{self.task_id}_{task.get('query')[0:60]}"
self.task = task
os.makedirs(self.output_dir, exist_ok=True)
def init_research_team(self):
# 初始化各个代理
writer_agent = WriterAgent()
editor_agent = EditorAgent()
research_agent = ResearchAgent()
publisher_agent = PublisherAgent(self.output_dir)
# 使用ResearchState定义一个状态图,
workflow = StateGraph(ResearchState)
# 为每个代理添加节点
workflow.add_node("browser", research_agent.run_initial_research)
workflow.add_node("planner", editor_agent.plan_research)
workflow.add_node("researcher", editor_agent.run_parallel_research)
workflow.add_node("writer", writer_agent.run)
workflow.add_node("publisher", publisher_agent.run)
# 添加节点之间的边
workflow.add_edge('browser', 'planner')
workflow.add_edge('planner', 'researcher')
workflow.add_edge('researcher', 'writer')
workflow.add_edge('writer', 'publisher')
# 设置起始节点和结束节点
workflow.set_entry_point("browser")
workflow.add_edge('publisher', END)
return workflow
async def run_research_task(self):
# 初始化研究团队并获取工作流
research_team = self.init_research_team()
# 编译工作流图
chain = research_team.compile()
# 异步调用工作流,并传递任务信息
result = await chain.ainvoke({"task": self.task})
# 返回研究结果
return resultLangGraph 状态图的构建过程主要由 3 个函数组成:add_node、add_edge 和 set_entry_point,通过这些函数,可以将节点依次添加到状态图中。
4. 初始化 Reviewer(审稿人)和 Reviser(修订者)
每个研究(子主题)任务都像是一个独立的项目,有自己的审查和修订流程。这样做的好处是,可以快速地完成更多的工作,因为不是在等待一个任务完成后才开始下一个任务。但是,如果所有的代理都依赖于同一个状态更新,就可能会出现问题,比如可能会出现大家争相报告,导致信息混乱,最终出来的报告可能会出错。为了避免这种情况,LangGraph 采用了一种子图的方式,每个子图有自己的独立状态,可以独立管理自己的工作进度。通过这种并行机制,让不同的代理可以同时工作,但又通过子图的方式,确保每个任务都能独立、有序地进行,从而保证了整个研究过程的高效和准确。在这个例子中,我们关注的是如何审查和修订研究草稿,所以定义的状态就是围绕草稿的信息来进行的。
class DraftState(TypedDict):
task: dict
# 讨论的主题
topic: str
draft: dict
# 审阅者
review: str
# 修订说明
revision_notes: str在 DraftState 中可以看到,主要关心讨论的主题,以及评审者和修订说明,它们彼此之间进行沟通,以最终完成子主题研究报告。
class EditorAgent:
def __init__(self, task: dict):
self.task = task
async def run_parallel_research(self, research_state: dict):
workflow = StateGraph(DraftState)
workflow.add_node("researcher", research_agent.run_depth_research)
workflow.add_node("reviewer", reviewer_agent.run)
workflow.add_node("reviser", reviser_agent.run)
# 设置边缘 researcher->reviewer->reviser->reviewer...
workflow.set_entry_point("researcher")
workflow.add_edge('researcher', 'reviewer')
workflow.add_edge('reviser', 'reviewer')
workflow.add_conditional_edges('reviewer',
(lambda draft: "accept" if draft['review'] is None else "revise"),
{"accept": END, "revise": "reviser"})通过定义条件边(add_conditional_edges),如果审稿人有审阅意见,状态图就会指向修订者;或者如果没有审阅意见,循环就会以最终草稿结束。如果回到构建的主图中,会看到这项并行工作是在 researcher 节点下进行的(workflow.add_node("researcher", editor_agent.run_parallel_research)),这个节点是由主编辑代理调用的。
运行研究助手
from dotenv import load_dotenv
from agents import ChiefEditorAgent
import asyncio
import json
# 用于加载环境变量
# export OPENAI_API_KEY = "xxx"
# export TAVILY_API_KEY = "xxx" 用于搜索
# export LANGCHAIN_TRACING_V2 = "true"
# export LANGCHAIN_API_KEY = "xxx" 使用LangChain的可观测平台LangSmith对我们的多Agent系统运行过程进行实时跟踪
load_dotenv()
# 定义一个函数open_task,用于打开并加载任务配置文件
def open_task():
with open('task.json', 'r') as f:
task = json.load(f)
# 检查加载的任务是否为空,如果为空则抛出异常
if not task:
raise Exception("No task provided. Please include a task.json file in the root directory.")
# 函数返回加载的任务对象
return task
# 定义一个异步函数main,作为程序的入口点
async def main():
# 调用open_task函数加载任务
task = open_task()
# 创建ChiefEditorAgent类的实例,并将加载的任务传递给它
chief_editor = ChiefEditorAgent(task)
# 调用ChiefEditorAgent实例的run_research_task方法来异步执行研究任务
research_report = await chief_editor.run_research_task()
return research_report
if __name__ == "__main__":
asyncio.run(main())使用 task.json 声明研究任务:
{
"query": "LLM 应用发展经历了哪几个阶段?",
"max_sections": 3,
"publish_formats": {
"markdown": false,
"pdf": true,
"docx": false
},
"model": "gpt-4o-2024-05-13",
"follow_guidelines": true,
"guidelines": [
"报告必须以 APA 格式编写",
"每个小节必须包含使用超链接的支持来源,如果不存在这样的来源,则删除该小节或将其重写为上一节的一部分",
"报告必须用中文书写"
],
"verbose": true
}query- 研究任务model- 使用的大语言模型max_sections- 报告中的最大章节数,每个章节代表研究查询的一个子主题publish_formats- 报告发布的格式,这里使用 pdf 格式follow_guidelines- 如果设置为 true,研究报告将遵循以下指南,完成时间会更长。如果设置为 false,报告生成速度会更快,但可能不遵循指南。guidelines- 报告必须遵守的指南列表。verbose- 如果设置为 true,应用程序将向控制台打印详细的日志信息。
结论
在代理工作流中,通过人的干预来确保流程的正确性、可控性是非常重要,这样才能最大化的得到确定性结果,比如本篇中的例子,通过人的介入可以帮助助手修订并专注于适当的研究计划、主题和大纲,从而提高报告整体生成质量,而 LangGraph + LangSmith 就是构建可观测代理工作流的最佳组合,当然优雅的代理工作流设计背后靠的是强大的基础模型能力提升,GPT-4o 真能打!
我写过的 LangChain 相关文章合集
- 从零开始学 LangChain(1):入门介绍
- 从零开始学 LangChain(2):Model I/O 模块和 Data Connection 模块
- 从零开始学 LangChain(3):Memory 模块和 Chain 模块
- 从零开始学 LangChain(4):Agents 模块和 Callbacks 模块
- LLM 应用开发框架 Semantic Kernel 和 LangChain 比较(上篇)
- LLM 应用开发框架 Semantic Kernel 和 LangChain 比较(下篇)
- 轻装上阵,加速商业化!LangChain 0.1 预发布看点!
- LangChain 在多轮对话中让 Agent 保持长期记忆的 8 种方式
- 如何使用 LangChain 实现 Agent 的 ReAct 模式
- LangChain 创始人最新访谈:开源 LLM 中间件的未来与挑战
- 刚刚!LangChain 宣布推出 LangChain v0.2 预发布版本!
- 使用 DeepSeek-V2+LangGraph 编写了一个编码助手类 AI Agent