Vol.5:面向企业的大模型应用算一个新赛道吗?
第 5 期内容已送达!在本期分享内容包括:揭秘 OpenAI 发布会现场演示中 GPT-4o 低延迟语音交谈背后采用的实时语音解决方案,IBM 在实践中如何利用三种混合搜索方案(关键字搜索、向量搜索、基于语义的稀疏编码器搜索)提升 RAG 效果, 分享 LinkedIn 在客服问答系统中如何结合检索增强生成(RAG)和知识图谱(KG)的,同时介绍一款快速准确地将 PDF 转为 markdown 的开源工具,和一个 OCR 开源项目,提供了完整的 OCR 解决方案所需的所有功能,一款向量数据库厂商 Weaviate 开源出生产级 RAG 框架。国内大模型市场方面,介绍了零一万物开源的 Yi-1.5 模型、腾讯的新产品(智能体平台)腾讯元器、字节豆包系列大模型(原云雀)、Kimi 会员功能(对话唤出打赏功能),最后分享一组关于各个大模型的 TTFT (Time To First Token,token 首次输出时间)以及 TPS(Tokens Per Second,每秒处理 token 数)数据的对比,以及「大模型应用层 To B 并不是一个新赛道」的洞见,本期共包括 4 篇论文、5 篇工程相关文章、6 条产品信息和 3 条市场方面的洞见。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
Blended RAG:通过语义搜索和混合查询检索器提高 RAG(检索增强生成)的准确性:IBM 出品,提出了一种新型的“混合 RAG”策略,结合了密集向量索引、稀疏编码器索引等语义搜索技术及混合查询策略。通过这种方法,在 NQ 等信息检索数据集上取得了更佳的检索成效,并刷新了基准记录。此外,将“混合检索器”应用于 RAG 系统,使得在 SQUAD 等生成式问答数据集上的表现大幅超越了传统的细调方法。
在这篇论文中,作者尝试了三种独特的搜索策略:
- 基于关键词相似度的搜索( BM25 用于关键词搜索,BM25 索引精于运用全文搜索,并结合模糊匹配技术,为执行更高级的查询操作打下坚实基础)
- 基于密集向量的搜索 ( KNN 用于向量搜索,得益于句子转换器,能够精确衡量文档内容与查询内容向量表示的相似性)
- 基于语义的稀疏编码器搜索(Elastic Learned Sparse Encoder(ELSER)则用于稀疏编码器的语义搜索,融合了语义理解和相似性检索,捕捉词汇间细微的关系,更真实地反映用户意图与文档的相关性)
- 以及将以上三者的融合,创造出混合型查询方式
使用新知识微调 LLM 会增加模型幻觉风险吗?:大语言模型经过监督微调时,可能会遇到未经预训练获得的新事实信息,之前就有人推测这可能会教会模型产生事实不正确的响应,因为模型被训练生成不基于其现有知识的事实。谷歌这篇最新论文考察了这种新知识注入对微调模型利用其已有知识能力的影响。研究设计了一个问卷问答的受控实验,探究了微调中引入新知识对模型利用先前知识能力的影响。实验表明,大语言模型在微调中学习新事实的速度较慢,但一旦学会,却会线性增加产生幻觉的倾向,作者强调大语言模型主要通过预训练获取事实知识,而微调则旨在使其更高效地运用这些知识。
基于知识图谱的检索增强生成技术在客户问答系统中的应用:这篇论文 LinkedIn 分享了一种结合检索增强生成(RAG)和知识图谱(KG)的客服问答系统,该系统通过集成历史工单的结构化数据和树状结构表示,显著提高了召回成功率至 86 ~ 94%。系统使用 GPT4 进行实体检测和意图识别,通过知识图谱过滤实体并利用嵌入技术检索意图。这种方法不仅保留了问题的内部结构和相互关系,还提高了检索精度和答案质量,已在 LinkedIn 的客户服务中部署,有效缩短了问题解决时间。
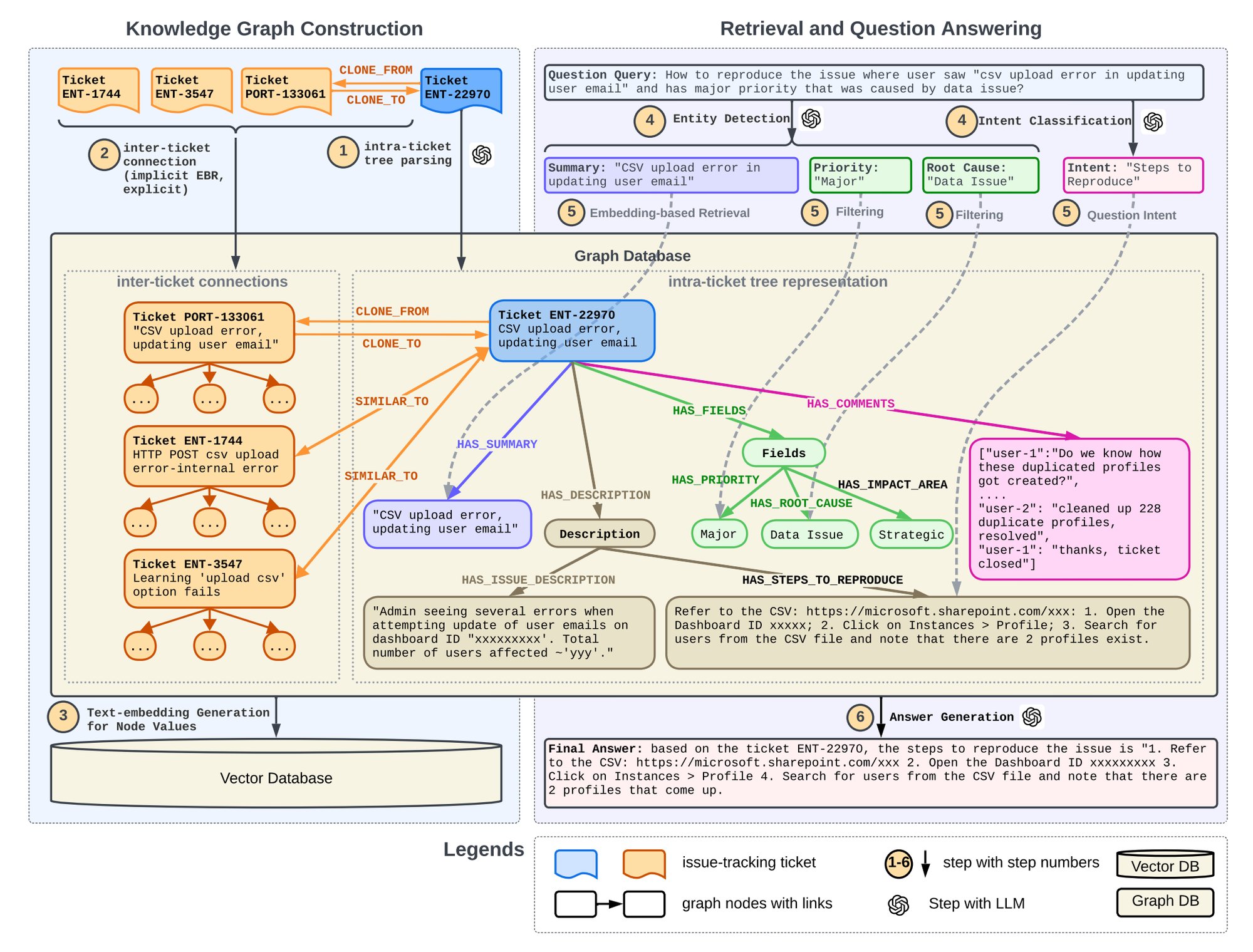
R4:Reinforced Retriever-Reorder-Responder for Retrieval-Augmented Large Language Models(增强型检索-重排-应答器,用于增强检索的大语言模型):阿里设计的 RAG 框架R4:Reinforced Retriever-Reorder-Responder(增强检索器-重排序-响应器),它包含三个主要模块:
- 检索器(Retriever):使用 Dense Passage Retriever(DPR)检索相关文档。
- 重排序器(Reorder):通过图注意力学习和强化学习机制动态调整检索文档的顺序。
- 响应器(Responder):将查询和调整后的文档作为输入,生成回答。
具体过程包括:
- 文档顺序调整:利用图注意力学习将检索文档动态调整到开始、中间和结束位置,以最大化回答质量的强化奖励。
- 文档表示增强:对于生成质量较差的回答,通过文档级别的梯度对抗学习来细化检索文档的表示。
实验使用了 3 类任务 5 个数据集,包括生成式问答(Generative QA)、多项选择问答(Multi-choice QA)和对话(Dialogue)任务,R4 框架在知识密集型任务上的表现超过了多个强基线模型,包括 REALM、ICR、REPLUG、Selfmem、SELF-RAG、FILCO 和 LongLLMLingua。
工程
- Mrker:Marker 是一种快速准确地将 PDF 转换为 markdown 的工具,支持各种文档类型,优化于书籍和科学论文,支持所有语言,能够去除页眉、页脚等多余元素,格式化表格和代码块,提取并保存图片,将大部分方程式转换为 latex 格式。Marker 工作过程是一个基于深度学习模型的流水线:
- 提取文本,必要时进行 OCR(启发式方法、Surya、Tesseract)
- 检测页面布局并找到阅读顺序(Surya)
- 清理并格式化每个区块(启发式方法、Texify)
- 组合区块并后处理完整文本(启发式方法、PDF 后处理器)
- 我如何夺冠新加坡首届 GPT-4 提示工程大赛:作者分享了提示工程策略,包括 CO-STAR 框架和使用分隔符进行文本分段的重要性。CO-STAR 框架包括上下文、目标、风格、语气、受众和响应等要素,有助于提高大语言模型的响应效果。分隔符在复杂任务中起关键作用,帮助模型更好地处理不同部分的提示。同时介绍了如何为大语言模型(LLM)设定动态规则以及使用 LLM 进行数据集分析的优势和限制,文章还展示了使用 LLM 分析 Kaggle 数据集的例子,以及验证 LLM 分析能力的实验结果。另外,还介绍了使用 ChatGPT 的高级数据分析插件进行数据分析的尝试。这篇文章讨论了在数据分析中何时应该使用大语言模型(LLM),以及如何通过指导和优化响应格式来最大程度地利用 LLM 的优势。作者提供了关于如何处理复杂任务、标记和引用中间输出、优化响应格式以及将任务指令与数据集分离的技巧。指路 👉中文译文
- Verba:Verba 是一个开源的 RAG 工具,旨在使 RAG 易于使用,同时具有模块化架构,用户可以根据需要自定义各个部分。它包括数据源、自定义问题回答等功能。用户可以在 Verba 中查看答案来源,并具有数据管理功能,使用户可以管理上传的数据。Verba 还提供简化的数据导入界面,用户可以直接上传数据,无需运行复杂的脚本。应用还包括状态页面,让用户了解应用程序的运行状态和功能。Verba 的架构分为五个关键步骤,包括 ReaderManager、ChunkerManager、EmbeddingManager、RetrieveManager 和 GenerationManager,每个步骤都可定制以适应不同需求。系统的 Retriever 组件使用混合搜索技术检索相关上下文,结合了传统关键词搜索和矢量搜索。Weaviate 是一个多功能的工具,提供各种搜索方法,包括传统关键词搜索、矢量搜索和混合搜索。最终,Verba 通过 Generation 组件生成用户查询的答案,并展示用于生成答案的信息块及其相关性分数。Verba 的架构设计灵活,并且易于理解和使用,用户可以根据特定用例扩展基本功能。未来,Verba 计划添加 Weaviate 的多租户功能,以支持多用户设置,提供更专注于企业的解决方案。
- surya:Surya 是一个功能全面的文档 OCR 工具包,支持超过 90 种语言的文字识别,能够进行行级文本检测,阅读顺序检测,以及布局分析,包括表格、图像、标题等的检测。它几乎提供了完整的 OCR 解决方案所需的所有功能。
- Livekit:OpenAI GPT-4o 采用了 Livekit 的实时语音解决方案,该方案具备以下特点:内置常用 ASR/TTS 功能、可对接大型模型插件、支持自定义代理交互逻辑,以及自动实现扩缩容。
产品
-
- ChatGPT UI 更新
- 推出 GPT-4o:支持文字、语音和视频(严格来说是图片帧)跨模态交互,但是逻辑推理能力个人体验下来略差于 gpt4-turbo
- 推出 ChatGPT 桌面应用(Mac 版)
- GPT-4o API 定价,输入 $5.00 / 百万 tokens,输出 $15.00 / 百万 tokens,支持 128k 上下文;同时每个 trie 级别对应的速率限制(RPM)在 gpt-4-turbo 基础上提升 5 倍
- 除了发布会的演示场景外,OpenAI这篇 blog在能力探索部分探讨了更多场景,包括了视觉叙述能力、根据真人照片制作海报能力、人物设计能力(动作捕获)、模拟人书写手法(手写体)、3D 合成等
新模型免费用户可限量用,同时 API 加量减价,感谢其他大模型厂商和开源模型的追赶,促使 OpenAI 也需要把免费作为一种竞争策略;OpenAI 没有发布 GPT-5,而是把重心转向应用层,数据确实不够用了,Scaling Laws 阶段性到头了,也反映出合成数据潜力很大;首席科学家 Ilya Sutskever 离职,至此 OpenAI 团队的所有 GPT 论文通讯作者都已离开,看了谷歌发布会,DeepMind 团队开始发力了,对于 OpenAI 继续引领大模型趋势我表示怀疑。
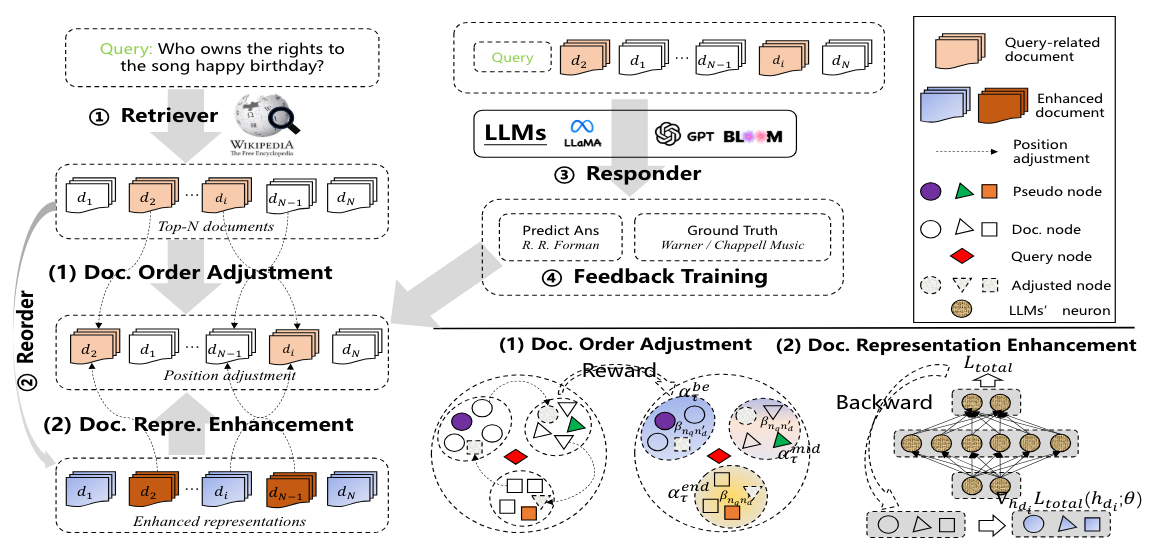
另一个点,GPT-4o 在 TTFT(Time To First Token,token 首次输出时间)指标上表现优异,特别适合实时应用场景,但在 TPS(Tokens Per Second,每秒处理 token 数)方面落后于 gemini-1.5-flash,GPT-4o 在实时性能方面进行了大量优化,很牛的基础设施工程,虽然处理速度较慢,但能更快地开始响应。
(数据来自 https://thefastest.ai,上面有各个大模型的 TTFT 以及 TPS 数据的对比)
-
- 谷歌搜索 AI 版,结果生成支持多步推理能力
- 100 万上下文的 Gemini 1.5 Flash 模型,和 200 万上下文(需申请)的 Gemini Pro 模型,开源了多模态模型 Pali Gemma,以及 Gemma2(预计 6 月推出)
- Google Workspace 全线支持 AI
- 手机版 Gemini ,将支持和 AI 视频对话
- 其他模态 AI 产品:图片生成 Imagen 3,音乐生成 Music AI Sandbox,视频生成 Veo
- 发布第 6 代 TPU Trillium ,是上一代的 4.7 倍强。同时发布 Arm 架构的 Google Axion 处理器
有一个点很有意思,谷歌 Gemini 的 AI 视频对话是真的视频,OpenAI 的 GPT-4o 是通过高频截帧的方式。
零一万物开源 Yi-1.5 :零一万物发布 Yi 系列开源模型 Yi-1.5, 分为 34B、9B、6B 三个版本,采用 Apache 2.0 许可证,且提供了 Yi-1.5-Chat 微调模型可供开发者选择,Yi-1.5 是 Yi-1.0 的持续预训练版本,使用 500B 个 token 来提高编码、推理和指令执行能力,并在 300 万个指令调优样本上进行了精细调整,Yi-1.5 模型进一步提升了编码、数学、推理和指令遵循能力,Yi-1.5 34B 在一些指标超过了 Qwen 的 72B,几乎与 Meta Llama 3 的 70B 相当,商业闭源模型方面,同时开放了 Yi-Large、Yi-Large-Turbo、Yi-Medium、Yi-Medium-200K、Yi-Vision、Yi-Spark 等多款模型 API 接口。
- GitHub 地址技术报告:https://github.com/01-ai/Yi-1.5
- Hugging Face 模型下载地址:https://huggingface.co/01-ai
- 魔搭社区模型下载地址 :www.modelscope.cn/organization/01ai
腾讯元器:腾讯推出的智能体平台,和字节的扣子、Dify 编排流等模式差不多。
字节发布豆包大模型:5 月 15 日,字节跳动火山引擎原动力大会正式推出豆包大模型,就是之前的云雀,豆包系列包括:豆包通用模型 pro(升级版)、豆包通用模型 lite(简化版)、豆包-角色扮演模型、豆包-语音合成模型、豆包-声音复刻模型、豆包-语音识别模型、豆包-文生图模型、豆包-Function Call(函数调用)模型、豆包-向量化模型。
Kimi 上线打赏功能,对话触发后,点击【给 kimi 加油】即可,打赏模式等同于变相开启会员制,是 Kimi 实现商业化的一种新方式,Kimi 的打赏模式共有 6 种,从 5.2 元「送 Kimi 一朵花」优享 4 天到 399 元「和 Kimi 一起登月」优享一年。
市场
大模型应用层 To B 并不是一个新赛道:作者认为国内大模型应用层 To B 仍然属于传统 To B 软件开发赛道,仍然要跟其他传统 To B 供应商在旧的标准下进行竞争,我十分认可,摘录如下。
0、前言
本文并不是一个复杂的观点,但现在似乎在 To B 公司以外的人来说还并非共识。为了节省我后续的重复沟通成本,所以单独写一个短篇来简述这个观点。
由于 To B 领域包罗万象,远非这一个观点能够概括的,所以得先说明这个观点针对的范围:
- 主要讨论 To 中大 B 的场景,面向小微 B/Pro C 领域专家个体等的不在讨论范围内。
- 不讨论品牌价值已经很高的极为知名的公司(如智谱等),更多讨论品牌价值不高的 To B 公司。
- 不讨论“核心技术能力在其方向鹤立鸡群,几乎看不到第二名”的以核心技术能力和优秀的战略选择立身的公司。
- 不讨论客户就是要买大模型产品的“政绩”类需求。
1、认知的演变
大模型的热潮启动之后,整个领域自然的出现了一些分化,例如:文本模态与 Agent、生图场景、泛游戏圈等。
从技术层级来说,大家一般粗略划分为:模型层、中间件层+应用层。目前中间件层仍然较薄,跟应用层的边界模糊。(我个人角度其实认为这个划分太过粗糙,不过这不是本文的主题。)在应用层中,根据客户的不同大致分为:To B、To C、To Pro、To Dev 的中间件等。而本文就是讨论这里的 To B。
从应用层 To B 的团队背景来说主要有两类:
- 之前就是做 To B 的,正在往增加大模型能力的方面转型。
- 原目标是跳大模型的浪潮,一番探索之后决定去做 To B 方向。
对于前者来说,团队的思路、已有客户、公司品牌等都已经绑定在传统 To B 赛道中,对他们来说本文的观点才是默认认知。
而对于后者来说,大家在前期的认知可能是:大模型应用层 To B 是一个新赛道,跟传统 To B 供应商的竞争有限,也享受着不同的评价标准与定价体系。而这里就是本文抛出不同观点的地方。
2、房间里的大象
2.1、客户不会单纯为 AI inside 支付溢价
经常被大模型创业者所忽视的一点是:客户并不会单纯为 AI inside 支付溢价。前期过度宣传阶段,大家可能会把新技术与更好的效果联系在一起而为此买单,但很快市场就因为涌入的人太多而良莠不齐。市场经过一段时间教育之后,终会回归为效果付费。
这个不止在 To B 方面,在 To C 中,会更偏好 AI inside 的人也是有限的,想想我们的父母一代,他们是否会只因为一个 App 使用了 GPT4 而不看效果就为它持续付费?
不过现在 To C 方面无论是国内还是海外,做一锤子买卖,骗用户进行订阅然后指望 TA 忘记退订的商业思路已经大行其道。用户对大模型的信心就那么些,迟早会有用完的时候。我相信即使是海外用户,也不会看着账单上一堆不用的鸡肋订阅费无动于衷。
2.2、在 B 客户内落地需要深度“适配”
大模型的应用仍然要深入接入 B 客户企业内的流程中才能发挥价值,并不是说我们卖客户一个 RAG 产品就可以直接数钱。想象我们是在没有 Office 的市场里销售 Excel,市场上也没有同类的表格产品。如何才能让用户能够利用上它的价值呢?需要很多的用户培训与原有文档体系的改造,而这些客户自己无法完成。
踏上这条路之后,就跟传统的 2B 业务没有太多的区别。传统 2B 中需要的所有事情,在大模型应用层 2B 中也都需要。而客户也更习惯以对待传统 2B 供应商的方式来对待未来的供应商。
3、大模型应用层 To B 仍然属于传统 To B
由于我一直对 To B 方面关注有限,所以也是直到最近才意识到这个事情,是在与一个 2B 方向的创业者讨论时意识到的。线下后续与人讨论时,有 2B 经验的人也都赞同这个观点。
大模型应用 To B 甚至都不是一个传统 To B 的子赛道,也不是 To B + AI,它与传统 To B 的区别实际上更小,需要被视为就是传统 To B 中又增加了一种新技术而已,就像是增加了 GBDT 模型(例如 XGBoost)一样。
目前仍然属于变更期,一些之前没有 To B 能力的团队可以靠着现在的大模型方案来获得 To B 的敲门砖,进入到 B 客户的供应商体系内。但长期来说他们需要补齐 To B 的其他能力/职能,无法“独善其身”,这可能是一些转型过来的团队没有意识到的。客户只需要一个能力更强的新供应商,而不是一个什么“大模型应用供应商”。脏活累活仍然是要做的,否则要么认识到自己不想做而主动退出,要么被客户嫌弃而丢弃。
相对来说,本文更多是针对于文本模态/Agent 的场景,生图/生视频等没有现存替代方案的方面这方面收到的制约会少一点,但也无法不受此影响。
我很难有效的论证这个观点,会同意的人自然会同意,强烈反对人总会反对。所以我只能抛出来引发大家的思考,也许能够帮助到一些中间还没有想清楚的人。
2024 年 AI Agent 行业报告:甲子光年 4 月底发布的一份报告,探讨 AI Agent 在概念变化,学术及商业界的尝试与探索,对各行业、各场景对于 AIGC 技术的需求进行调研及梳理,展示 AI Agent 领域近期的突破及商业实践范式。
2024 AIGC 应用层十大趋势白皮书:IDC 联合钉钉出品的,忽略钉钉 PR 打广告的部分内容,IDC 对企业决策者采用 AI 的调查部分很值得一看。
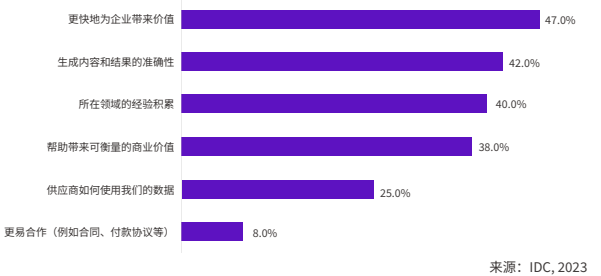
企业选择 AIGC 项目时的重点考虑因素
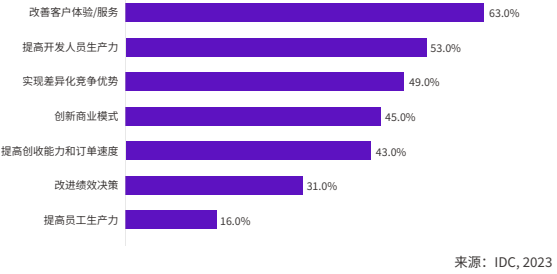
企业最希望通过 AIGC 应用实现的商业利益
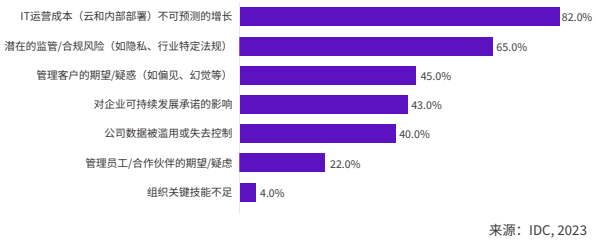
企业最担心与 AIGC 应用相关的商业风险
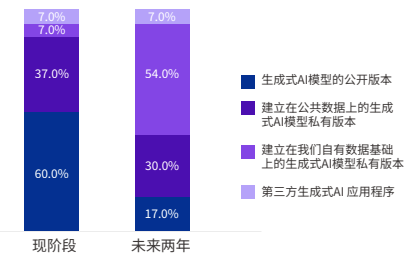
Vol.5:面向企业的大模型应用算一个新赛道吗?
