Vol.6:如何将 AI 模型转化为生产环境中的产品?
大家好,Weekly Gradient 第 6 期内容已送达!在本期分享内容包括:如何将 AI 模型转化为生产环境中的产品,包括售前与解决方案的草稿完成、产品或项目启动、数据采集与管理、模型训练与调试等,非常适合本次 AI 浪潮新入场做大模型项目交付的乙方朋友以及甲方决策者阅读;Agent 可观测性项目,用于代理应用执行图分析和调试;LLM 微调和训练平台产品,用于提升训练效率,提高推理速度,减少显存占用;产品方面包括生成式 UI/UX 产品盘点;市场方面分享了 2024 年零售与消费品行业 AI 现状与趋势 报告,更多内容请查看周刊全文。本期共包括 4 篇论文、4 篇工程相关文章、4 条产品信息和 3 条市场方面的洞见,最后在观点部分重点分享了从 GPT-3 开始,AI 是如何开始改变企业的游戏规则的。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
- Retrieval-Augmented Generation for AI-Generated Content: A Survey:一篇 RAG 技术的调研汇总,RAG 技术在人工智能生成内容 AIGC 各个领域的应用和进展,来自北大 DAIR Lab 汇总了 RAG 技术在 Text、Image、Code、Audio、3D 等等多种 AIGC 垂直领域中的技术研究(论文),汇总资料:https://github.com/PKU-DAIR/RAG-Survey
- MapCoder: Multi-Agent Code Generation for Competitive Problem Solving:代码合成是一个复杂的过程,需要深入理解自然语言描述,生成复杂算法和数据结构的代码指令,并经过全面的单元测试。尽管大语言模型(LLMs)在自然语言处理方面表现出色,但在代码生成方面仍有局限。本文提出了一种新颖的多代理提示方法,模拟人类开发者的程序合成全周期,包括回忆示例、规划、代码生成和调试。MapCoder 框架通过四个 LLM 代理实现这一过程,并在多个基准测试中展示了其卓越的代码生成能力,刷新了 HumanEval、MBPP、APPS、CodeContests 和 xCodeEval 的记录。此外,该方法在不同编程语言和问题难度上均表现出色。项目的 GitHub 地址:https://github.com/Md-Ashraful-Pramanik/MapCoder
- MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation:大语言模型(LLMs)在文本到 SQL 任务中表现出色,其关键在于利用上下文学习(ICL)方法超越了简单的微调方法。尽管如此,它们在面对复杂模式和查询(如 BIRD)时的表现仍低于人类专家。本研究深入探讨了 LLMs 的提示敏感性,提出了一种创新策略,通过多提示探索答案的广阔空间,并巧妙地整合结果。通过构建精细调整的数据库架构链接多提示,进而创造出多样的候选 SQL 查询。最后依据置信度评分筛选这些候选查询,并采用多选机制展示最优解。在 BIRD 和 Spider 测试中,该方法分别达到了 65.5%和 89.6%的准确率,显著超越了以往的 ICL 方法,在 BIRD 上刷新了准确性和效率的 SOTA 记录。
- AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments:诊断和治疗病患是一个复杂且持续性的决策过程,医生需要收集信息并据此采取行动。大语言模型(LLMs)的进步为临床护理带来了福音,但现有的评估更多依赖于静态的问答,无法模拟实际的互动决策过程。为此,斯坦福和霍普金斯联合开发了 AgentClinic,这是一个多模态评估平台,让 LLMs 在模拟临床环境中扮演医生的角色,通过对话和数据收集来揭示病情。提供了两种环境:AgentClinic-NEJM 结合图像和对话,而 AgentClinic-MedQA 仅包含对话,模拟了偏见因素,发现这不仅降低了诊断的准确性,还影响了患者的配合程度和信心。同时发现,所使用的 LLM 对患者代理的性能有显著影响,且交互次数需保持适中,过多或过少都会影响诊断准确性。相关的代码和数据已经公开发布,网址为https://AgentClinic.github.io。
工程
如何将 AI 模型转化为生产环境中的产品?:toB 大模型项目的研发和交付,和传统机器学习项目的实施部署其实没有太大差别,这本开源电子书非常详细的概述了一个机器学习项目的生命周期,包括售前与解决方案的草稿完成、产品或项目启动、数据采集与管理、模型训练与调试、部署与测试、DevOps 实践以及最终的项目交付,这些步骤涵盖了从项目准备到实施再到最终交付的全过程,非常适合这次 AI 浪潮新入场做大模型项目交付的乙方朋友以及甲方决策者阅读。
chat-with-your-data-solution-accelerator:本项目是一个基于 Azure 的开源解决方案加速器,采用 RAG 模式,利用 Azure AI 搜索和 Azure OpenAI 大型语言模型,提供类似 ChatGPT 的交互体验和问答功能。主要特点包括:私有 LLM 访问用户私有数据,实现高效的自然语言交互;通过单一应用程序访问完整数据集,减少端点数量;支持语音转文字,方便快速获取答案和进行后续查询;查询时可直接访问源文档以增加上下文理解;支持批量上传各种类型文件,并提供易于操作的编排功能,包括提示和文档配置。
腾讯开源混元-DiT:5 月 14 日,腾讯旗下的混元文生图大模型宣布对外开源,目前已在 Hugging Face 平台及 Github 上发布,包含模型权重、推理代码、模型算法等完整模型,可供企业与个人开发者免费商用。
这个算是上周的事情了,主要是这周我深度体验了下,真的不错,特别是文生图模型,当前国内提供文生图能力的大模型厂商,有一个算一个基本都是 Stable Diffusion 模型基础上简单改改,好一点的还加入更多中文场景下的图片数据(阿里通义万相),有的甚至滥用充数,完全是做了一层中文转英文(百度家的),然后输入模型的,大家可以试试用烤面冷、凉拌猪耳朵或者凉拌菠菜等这类国内小吃和传统菜品验证下。


AgentOps:这是一个开源的 Python SDK,用于监控 AI Agent、跟踪 LLM 成本、进行基准测试等。它支持多种主流 LLM 和 Agent 框架的集成,包括 Llama、Mistral、Claude、Gemini、Dall-E、Whisper、Cohere 等。该 SDK 提供了分步代理执行图分析和调试功能,可以帮助跟踪 LLM 基础模型的支出,并进行 1,000 多次的 Agent 基准测试。此外,它还能检测常见的提示注入和数据泄露漏洞,确保合规性和安全性。该 SDK 可以轻松集成到 CrewAI、LangChain 等框架中使用。
产品
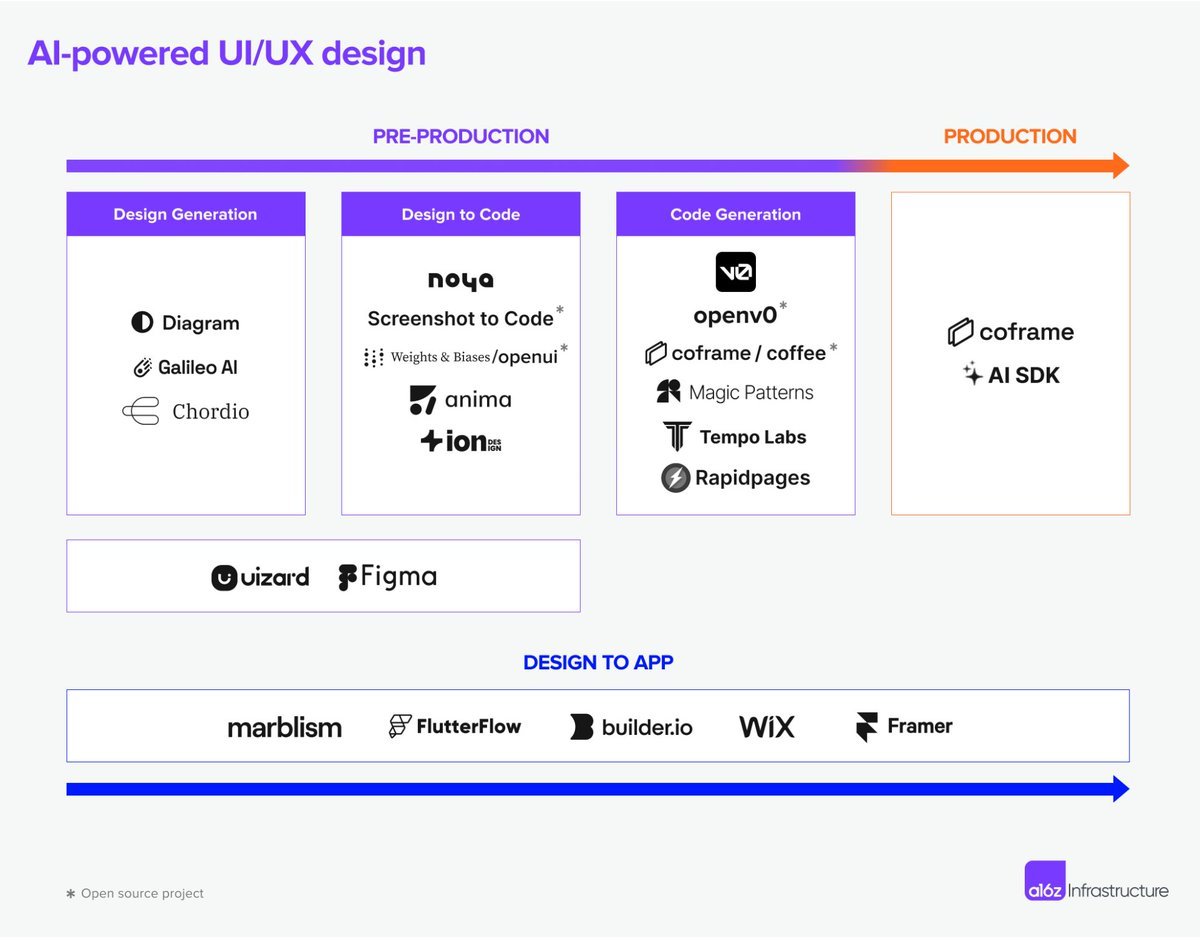
生成式 UI/UX 创业公司全景图:
界面设计:Galileo_AI、Tempo_Labs(YC 投资)、diagram
设计工具:noyasoftware、uizard、Wegic
D2C(Design to Code):AnimaApp、flutterflow
设计系统:magicpatterns(YC 投资)
筷子科技 AIGC 内容商业应用平台 i:公司定位在利用 AI 技术解决企业级营销内容生产和管理的效率与转化问题。筷子科技最初通过程序化生产创意图片,提高了企业广告创意图片的生产效率,并连接了多家主流互联网平台的营销体系,帮助广告主进行数据分析和投放优化。主要服务于大消费行业的大中型 To C 品牌,如欧莱雅、华为等。2020 年后,随着短视频内容的兴起,筷子科技转向视频内容生产,利用前期积累的技术经验,程序化量产营销视频。同时,公司开始研发面向更广泛品牌的 AIGC 应用产品,并推出了 Kuaizi.ai AIGC 内容商业应用平台,该平台通过 AI 提升内容生产效率,并整合了多个平台的营销资源,利用智能推荐算法和数据分析提高营销效果。
又是一个 + AI 的产品案例,对客户而言,他们不止在意营销内容的生产效率,更在意如何能有效驱动销售转化,打通全环节。筷子科技是 AI 在品牌内容商业领域的深度应用者及拓展者而非依赖者,AIGC 浪潮来临前,公司就已经找到了稳定的可持续规模化发展的业务模式。
Unsloth:LLM 微调和训练平台,更快地训练和推理速度、更少的显存占用、提供算力托管。Unsloth 详细功能介绍亮点信息:
速度提高 30 倍。Llama 微调只需要 3 小时而不是 85 小时。
内存使用量减少 60%,允许批量增加 6 倍。
产品支持 NVIDIA、Intel 和 AMD GPU。
手动自动求导和链式矩阵乘法优化。
用 OpenAI 的 Triton 语言重写了所有内核。
Flash Attention 通过 xformers 和 Tri Dao 的实现。
提供开源版本使微调速度提高 2 倍,内存减少 50%。
国内的算想未来也提供类似服务。
Huggingface 模型推理服务:Huggingface 推出的模型推理服务,旨在降低了部署模型的成本。支持一键部署现有模型、私有模型通过 docker 镜像部署,并具备 autoscaling 功能,可在没有负载时自动缩减到 0 实例。
市场
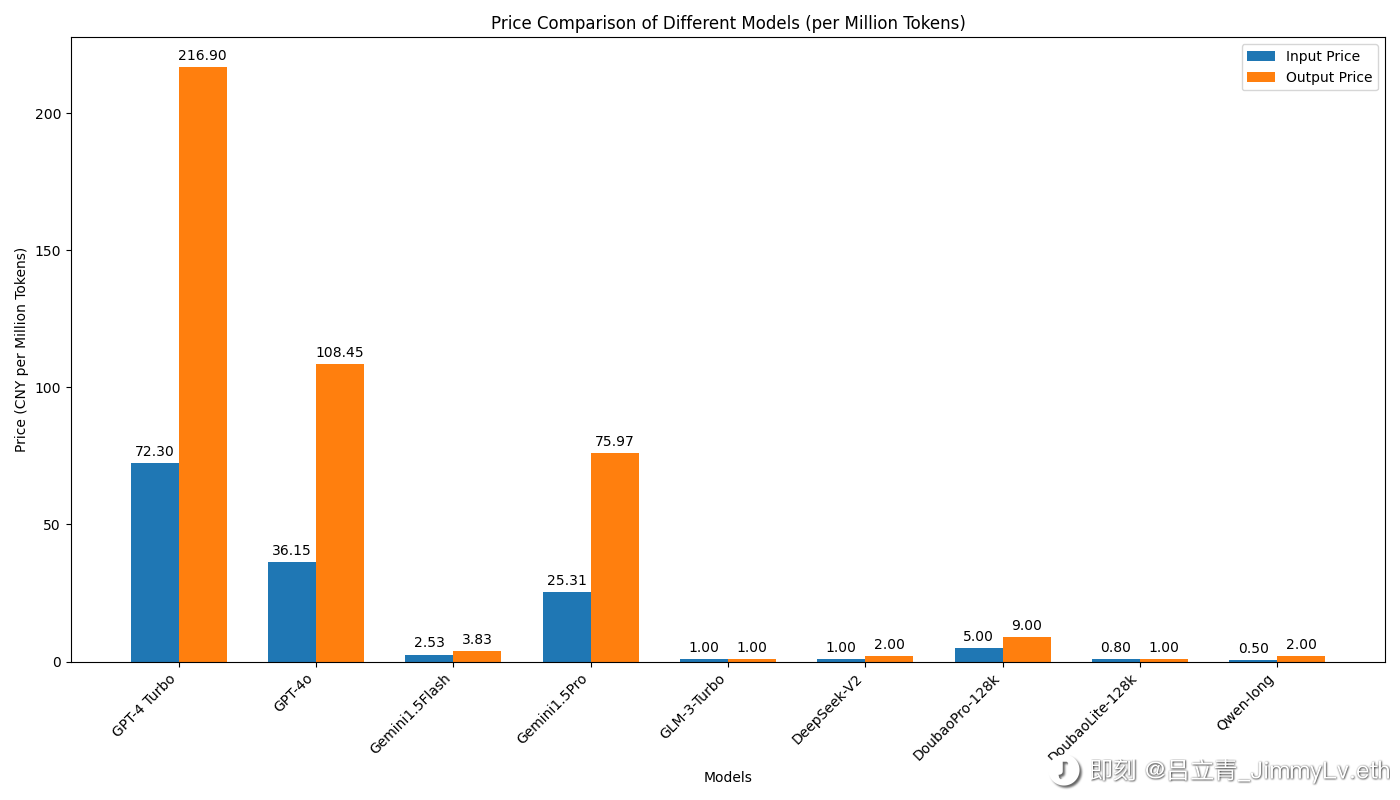
大模型价格战:价格战的时间线应该从从 DeepSeek-V2 发布开始,毕竟自那以后新闻稿上的模型 API 调用价格计量单位从 xxx 元/千 tokens 开始变成了 xxx 元/百万 tokens,下面是一个简单的时间线:
DeepSeek 发布全球最强开源 MoE 模型:2024-05-06,DeepSeek-V2(32K 上下文) API 的定价为:每百万 tokens 输入 1 元、输出 2 元
用大模型 API 就上 bigmodel.cn!:2024-05-11,智谱 AI 的 GLM-3 Turbo API 价格调整为 1 元/百万 tokens(输入输出同价)
2024 春季火山引擎 FORCE 原动力大会上: 2024-05-15 ,字节 Doubao-pro-128k(128K 上下文) API 的定价为:每百万 tokens 输入 5 元、输出 9 元;Doubao-lite-128k(128K 上下文) API 的定价为:每百万 tokens 输入 0.8 元、输出 1 元
智谱 AI 最新推出 Batch API:2024-05-21,支持的模型以及价格:GLM-4 API 价格为 50 元 / 百万 tokens,GLM-3-Turbo API 价格为 0.5 元 / 百万 tokens(输入输出同价)
降价,立即生效!:2024-05-21,阿里云 Qwen-Long API 价格调整为每百万 tokens 输入 0.5 元、输出 2 元。
免费,立即生效!:2024-05-21,百度宣布 ERNIE Speed 和 ERNIE Lite 两款模型宣布免费
首先肯定是利好 AI 应用层探索的,但如果不是模型推理优化带来的基础设施成本降低、从而带动消费 API 价格降低,那这种卷价格的市场策略我很反感, 赔钱补贴最终比的不是谁家模型能力强,而是谁家便宜,对大模型来说技术是核心,还想着用共享单车、百团大战的那种烧钱打法,那最后就是双输,模型能力没提升,钱也没了。

2024 年零售与消费品行业 AI 现状与趋势:零售与快速消费品行业在 AI 分析方面潜力巨大,可借助 AI 提升运营效率、改善顾客与员工体验,进而推动增长。NVIDIA 发布首份年度报告《2024 年零售与消费品行业 AI 现状与趋势》,深度分析了零售业中 AI 的应用现状、对收入与成本的影响,以及正在塑造行业未来的新兴趋势,该调研吸引了全球 400 多位参与者,包括首席高管、其他高管、部门经理及个人,问题涉及 AI 的多个方面、热门应用案例、主要挑战、基础设施投资规划及部署方式。
scale 官宣 F 轮融资 10 亿美元,估值 138 亿美元:Accel 领投,众多行业巨头如 Nvidia、AMD、Amazon、Meta 参与,在这波大模型浪潮中获利的公司,除了英伟达和 OpenAI,便是 Scale。Scale 旨在构建以 AI 技术为核心的数据基础设施平台,拥有宽广且强大的护城河,在大模型价值链上占据重要生态位。
8 年来,Scale 一直是领先的 AI 数据基础设施,助力推动了 AI 领域最激动人心的进步。
今天,我们宣布 Scale 已完成一笔 10 亿美元的融资交易,估值达到 138 亿美元。此次融资由现有投资者 Accel 领投,几乎所有现有投资者均参与其中:Y Combinator、Nat Friedman、Index Ventures、Founders Fund、Coatue、Thrive Capital、Spark Capital、NVIDIA、Tiger Global Management、Greenoaks 和 Wellington Management。同时,我们也热烈欢迎新投资者的加入:Cisco Investments、DFJ Growth、Intel Capital、ServiceNow Ventures、AMD Ventures、WCM、Amazon、Elad Gil 和 Meta。
随着这一里程碑的实现,我们来看看我们的旅程进展以及接下来的计划。
成为 AI 数据基础设施
2016 年,我在麻省理工学院学习 AI。那时,AI 的三大基石——数据、算力和算法已显而易见。我创立 Scale,旨在提供推动 AI 全生命周期发展的数据支柱。过去 8 年,Scale 助力了 AI 几乎所有重大突破领域:
Scale 的自主数据引擎推动了 L4 级自动驾驶的突破。
Scale 的公共部门数据引擎为美国国防部内多个重大 AI 项目提供了支持。
Scale 与 OpenAI 合作,在 GPT-2 上首次实验了基于人类反馈的强化学习(RLHF),并将这些技术扩展到 InstructGPT 及更远。
Scale 参与了白宫支持的 DEFCON 31 红队演习,并与美国国防部合作,对 LLMs 进行严格的评估、测试和红队演习。
今天,Scale 为几乎所有领先的 AI 模型提供数据支持,服务于 OpenAI、Meta、微软等组织。
下一阶段:前沿 AI 的数据愈加丰富
AI 数据仍面临重大问题。随着模型变大,数据需求呈指数增长,这引发了一个关键问题:我们会耗尽数据吗?正如数据、算力和算法构成 AI 的三大支柱,我们认为 AI 数据的未来也基于三大原则:
数据极大丰富(abundance):我们必须建立数据基础,引领 AI 数据丰富时代的到来,而非屈服于数据稀缺。
前沿数据多样性(frontier):随着 AI 能力的不断增强,我们必须构建前沿数据,始终推动 AI 能力向复杂推理、智能体、多模态等方向发展。
测量与评估(measurement evaluation):我们必须建立评估系统,以衡量 AI,建立信心,推动采用,并扩大影响。
丰富并非默认,而是一种选择。它需要汇聚工程、运营和 AI 领域的顶尖人才。
我们的使命是建立 AI 的数据基础设施,随着今天的融资,我们正迈入这一旅程的下一阶段——加速前沿数据的丰富多样性,铺就我们通往 AGI 的道路。
扩展阅读 👉 国内图像领域内的数据标注公司行业现状
观点
AI 正在改变企业的游戏规则:文章探讨了 AI 如何通过自动化重复性任务、数据分析和模式识别,帮助企业提高效率、增加收入和市场份额。通过介绍 AI 的演变、层次结构以及在不同行业中的实际应用案例,文章强调了 AI 技术对企业未来发展的重要性。
Vol.6:如何将 AI 模型转化为生产环境中的产品?
