Vol.23:为什么大语言模型仍无法做到真正的推理?
大家好!Weekly Gradient 第 23 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
TableRAG: Million-Token Table Understanding with Language Models:Google Deepmind 团队近期发布了一项研究成果,提出了名为 TableRAG 的新方法,专门用于处理百万级单元格的大型表格理解任务。TableRAG 结合了模式检索与单元格检索,能够在提供信息给语言模型之前精准定位关键数据,从而实现更高效的数据编码和精确检索,大幅缩短提示长度并减少信息丢失。该研究还基于 Arcade 和 BIRD-SQL 数据集创建了两个新的百万标记基准,以全面测试 TableRAG 的性能。实验结果显示,TableRAG 在大规模表格理解任务中表现出色,达到了业界领先水平。传统的基于大型语言模型(LLM)的表格问答(QA)系统往往需要将整个表格作为输入,这限制了处理大型表格的能力,因为 LLM 通常有上下文长度的限制,且过长的上下文可能会削弱推理能力。为了解决这些问题,TableRAG 通过查询扩展与模式和单元格检索相结合,使得 LLM 智能体能够依据这些信息解答查询。TableRAG 的核心组件包括表格查询扩展、Schema 检索、单元格检索等,它通过精确识别查询所需的列名和单元格值,并通过预先训练的编码器 fenc 进行编码和检索,从而提高了效率和准确性。此外,TableRAG 还引入了单元格编码,以优化在大型表格中的处理效率。在效果评估方面,TableRAG 在 ArcadeQA 和 BirdQA 数据集上的表现优于其他方法,尤其是在处理大型表格时。伸缩性测试也证明了 TableRAG 在不同表格大小下的稳定性和可伸缩性。消融研究进一步验证了 TableRAG 中各个组件的有效性,包括检索方法、检索结果数量 K、编码、查询扩展以及模式检索和单元格检索等。
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents:论文主要介绍了一个名为 Agent Security Bench (ASB) 的数据集,它用于评估基于大型语言模型(LLM)的智能体在不同场景下的攻击和防御效果,涵盖多种攻击方法和评估指标,并对攻击结果进行了分析,揭示了智能体在安全性方面的脆弱性。ASB 框架包含 10 个场景、10 个代理、400 多种工具、23 种攻防方法和 8 个评估指标,用于测试各种攻击,如提示注入、记忆污染和后门攻击,以及 10 种防御措施。研究发现,代理在系统提示、用户提示处理、工具使用和记忆检索等阶段存在关键漏洞,攻击成功率高达 84.30%,而当前防御措施效果有限。研究还提供了多个评估指标,如攻击成功率(ASR)、防御下的攻击成功率(ASR-d)、拒绝率(RR)等,以衡量智能体的安全性和性能。
Domain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization:这篇论文介绍了一种名为SMART-SLIC的领域特定大型语言模型(LLM)框架,该框架集成了检索增强生成(RAG)、知识图(KG)和向量存储(VS),旨在解决LLM在领域特定和知识密集型任务中的幻觉、知识断层和缺乏知识归属问题。
SMART-SLIC框架:
- 领域特定数据集:通过主题专家(SME)选择的核心文档构建引用和参考网络,使用SCOPUS、Semantic Scholar和OSTI等API扩展数据集,并应用多种剪枝策略去除不相关的文档。
- 维度降低:使用非负张量分解(NTF)从数据中提取潜在结构,采用二分搜索策略避免过拟合,最终确定最佳的簇数。
- 知识图本体:将T-ELF和文档元数据映射为头实体、尾实体关系,形成三元组并注入Neo4j KG中。
- 向量存储组装:使用Milvus向量数据库存储原始文档的向量表示,并将部分文档的全文向量化后加入向量存储。
- 检索增强生成(RAG):通过外部知识库获取信息,指导生成模型的输出,提高响应的准确性和相关性。RAG包括一般查询和特定文档查询两种路径,分别调用ReAct代理和工具执行器。
实验与验证:
- 数据集:最初选择了30篇专门研究大规模恶意软件分析和异常检测的文档作为核心文档,最终扩展到8,790篇科学出版物。
- 潜在特征提取:通过T-ELF分解得到25个主题簇,每个簇包含一定数量的文档。
- 向量存储:将8,790篇文档向量化并存储在Milvus中,22%的文档有全文,也进行了向量化处理。
- 知识图:从25个簇中提取1,457,534个三元组,注入Neo4j KG中,形成321,122个节点和1,136,412条边关系。
- 问答验证:通过Zero-Shot Conditioning和主题特定问题验证SMART-SLIC的RAG系统,结果表明GPT-4配合RAG的回答准确率为97%,而未使用RAG的GPT-4回答率为20%。
Inference Scaling for Long-Context Retrieval Augmented Generation Google DeepMind:这篇论文研究了长上下文检索增强生成(RAG)中的推理扩展问题,特别是如何通过增加推理计算来提高RAG的性能。
这篇论文提出了两种推理扩展策略:上下文学习增强生成(DRAG)和迭代上下文学习增强生成(IterDRAG)。具体来说:
- 上下文学习增强生成(DRAG): DRAG通过在输入提示中包含多个RAG示例,利用长上下文LLMs的能力。DRAG允许模型在上下文中学习如何定位相关信息并将其应用于响应生成。
- 迭代上下文学习增强生成(IterDRAG): IterDRAG通过将输入查询分解为更简单的子查询,并使用交错检索进行回答。通过迭代检索和生成,LLMs构建推理链,弥合多跳查询的组合性差距。
此外,论文还提出了一个计算分配模型,用于预测在不同推理参数下的RAG性能。该模型通过量化RAG性能与不同推理配置之间的关系,提供了对最优计算分配的指导。
实验设计
- 数据集: 论文在多个基准问答数据集上进行了实验,包括Bamboogle、HotpotQA、MuSiQue和2WikiMultiHopQA。每个数据集都包含多个问题和答案对,用于评估模型的推理生成能力。
- 参数配置: 实验中考虑了不同的推理参数配置,包括检索文档数量、上下文示例数量和生成步骤数量。通过调整这些参数,研究了不同配置下的RAG性能。
- 评估指标: 使用了精确匹配(EM)、F1分数和准确率(Acc)等指标来评估模型的性能。
结果与分析
- 固定预算下的最优性能: 对于给定的推理计算预算(即最大有效上下文长度LmaxLmax),论文通过枚举不同的推理参数配置,找到了在该预算下可实现的最优平均指标P∗(Lmax)P∗(Lmax)。结果表明,DRAG和IterDRAG的性能随着有效上下文长度的增加而显著提升。
- 整体性能: DRAG和IterDRAG的性能一致优于基线方法,特别是在较长的有效上下文长度下,IterDRAG表现出更好的扩展性。
- 推理扩展定律: 论文观察到,当有效上下文长度扩展时,RAG性能几乎线性地增加,提出了推理扩展定律。结合数据集特定的结果,关键观察包括:推理计算的线性关系、IterDRAG在较长上下文下的有效性以及超过1M令牌后性能增益的逐渐减少。
-
研究方法
这篇论文提出了“旅程学习”范式来解决AI研究中的挑战。
旅程学习:旅程学习鼓励模型不仅学习捷径,而是学习完整的探索过程,包括试错、反思和回溯。其目标是创建能够像人类一样进行持续学习、反思、回溯和适应的AI系统。
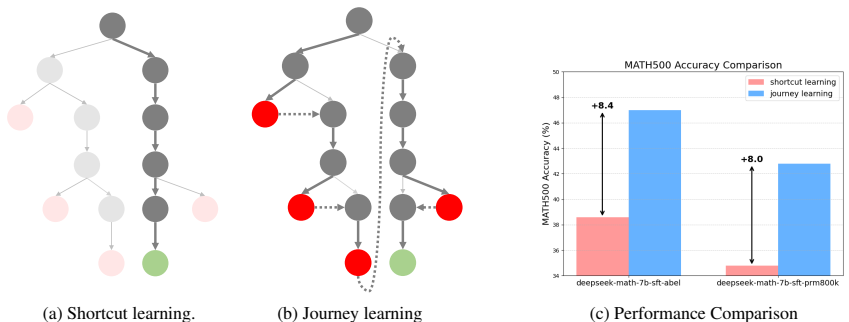
多路径探索:通过构建推理树并在树上执行搜索算法,结合过程级奖励模型来评估每个节点的正确性,从而构建长思考数据。
迭代改进:在每次迭代中,使用beam搜索选择得分最高的节点进行下一轮迭代,以提高生成长思考数据的质量和效率。
人类-AI协作:通过人类专家生成高质量的长思考数据,并使用AI驱动的过程进行数据增强,确保数据的多样性和质量。
实验设计
- 数据收集:使用了Abel数据集和PRM800K数据集进行预训练,并从PRM800K数据集中重新划分出MATH Train数据集用于直接偏好学习(DPO)。
- 实验设计:实验分为两个阶段:监督微调和直接偏好学习(DPO)。在监督微调阶段,首先进行短路径学习,然后在第二阶段进行旅程学习。在直接偏好学习阶段,使用nucleus采样生成20个响应,并从中选择5个正样本和5个负样本进行训练。
- 样本选择:从PRM800K数据集中选择12,000个样本进行DPO训练,并从这些样本中生成长思考数据。
- 参数配置:在监督微调阶段,使用DeepSeekMath-7B-Base模型,并在每个阶段进行3轮迭代训练。在直接偏好学习阶段,使用top-p=0.95和温度T=0.7进行nucleus采样。
结果与分析
监督微调结果:在MATH测试集上,旅程学习方法相比短路径学习方法在deepseek-sft-abel和deepseek-sft-prm800k模型上分别提高了8.4%和8.0%。
直接偏好学习结果:DPO方法的改进相对较小,但初步探索结果表明其具有潜力。
长思考数据生成
:通过多路径探索和人类-AI协作,成功生成了高质量的长思考数据,验证了旅程学习范式的有效性。
工程
- chunkr:一个基于视觉模型的 PDF 分块处理工具,支持快速的分段提取和 OCR 处理。项目使用 AGPL-3.0 许可证,同时提供商业许可证选项。该工具能够在单个 NVIDIA L4 实例上以大约每秒 5 页的速度处理 PDF 文件,是一个成本效益高且可扩展的解决方案。
- 在 Google Cloud 上使用 LlamaIndex 进行检索增强型生成 (RAG) 的综合指南:本文介绍介绍了如何使用 LlamaIndex、Streamlit、RAGAS 和 Google Cloud 的 Gemini 模型进行 RAG 解决方案的快速原型设计和评估。文章将 RAG 工作流程分解为四个步骤:索引和存储、检索、节点后处理和响应合成,详细说明了 LlamaIndex 如何简化这些过程。Google Cloud 的 Document AI 布局解析器被强调为文档处理的解决方案。讨论了自动合并检索等高级检索技术,利用分层索引提高检索准确性。文章最后通过使用 LlamaIndex 的检索器模块和自动合并检索器来检查检索过程,增强了检索准确性。它还比较了 LlamaIndex 与其他 RAG 工具,强调了其独特的优势,并讨论了在 Google Cloud 环境中优化性能的策略。
- 揭秘提示词压缩技术:在多文档搜索、问答系统、文档自动摘要生成以及阅读理解等多样化且复杂的应用场景中,往往会面临输入提示(prompt)长度显著增加的挑战。这种超长prompt不仅加大了大型语言模型(LLM)的推理成本,还显著延长了推理时间,从而严重限制了其在需要即时响应的实时应用场景中的适用性。为了克服这一难题,优化prompt设计,如通过压缩技术精简关键信息、采用更高效的prompt格式或结构,变得尤为关键。这样的策略旨在平衡模型性能与实时性需求,确保LLM能够在复杂多变的场景下依然保持高效、准确的响应能力。卓世科技提出的中文提示词压缩技术通过定义长提示词结构、小语言模型与大语言模型的分布对齐、多层次压缩策略和专业词汇保留等措施,显著降低了推理成本和时间。在多文档搜索和问答系统中,该技术显著提升了响应速度和准确性,特别适合在垂直领域应用。
- 使用 pgvector 和 Timescale 构建 Git 历史代码助手:本文详细介绍了 OpenSauced 如何利用 Timescale 和 pgvector 创建 GitHub 历史的代码助手。OpenSauced 是一个专注于开源项目和贡献者洞察的平台,旨在解决 GitHub 在提供实时数据和洞察方面的不足。本文首先介绍了 OpenSauced 的背景和目标,然后深入探讨了选择 Timescale 的原因,包括其卓越的性能、对 PostgreSQL 的熟悉度以及成本效益。OpenSauced 通过 Timescale 的高效时间序列机制,每小时集成数万个新的实时 GitHub 事件,提供深入的洞察和指标。本文还描述了数据管道的实现,利用 Go 微服务持续从 GitHub 事件流中读取数据并批量插入 Timescale。此外,本文探讨了 pgvector 在检索增强生成 (RAG) 中的使用,创建了一个名为 StarSearch 的 AI 功能,通过 Timescale 对 pgvector 扩展的支持,快速回答用户问题。
- OpenAI o1 系列模型负责人Noam Brown演讲:Noam Brown 的演讲详细回顾了他在 AI 推理领域的研究历程,特别是在扑克、围棋和外交等游戏中的突破。他强调了搜索和规划算法在提升 AI 性能中的关键作用,并通过具体案例展示了这些算法如何显著提高 AI 的表现。Brown 还讨论了这些技术在自然语言处理中的应用,如 Cicero 系统在外交游戏中的成功。此外,他展望了未来 AI 发展的方向,特别是如何通过增加推理计算来实现更强大的 AI 模型。
- 再谈LLM逻辑推理的三大谬误:作者认为LLM在许多情况下所做的事情只是类似于推理,但并不完全是正确、可靠的推理算法,这比根本没有推理算法更糟糕,因为它会让你错误地认为它有效,并且你可能无法判断它何时无效,而再多的渐进式创新(技巧)也无法解决这个问题。如果没有范式转变,将真正的推理纳入语言模型,这些错误不可避免。
产品
Kimi探索版内测,智谱清言发布 AI搜索 智能体,都是对o1思维链相关能力的应用。
OpenAI 在10月1日的 DevDay 活动上推出了多项新能力
Realtime API 允许开发者创建接近实时的语音到语音体验,提供了六种不同的声音选择。此外,OpenAI 还展示了一个基于 Realtime API 构建的旅行规划应用示例,以及如何使用该 API 与人类进行电话交谈,询问食品订购等事宜。
OpenAI 还在其 API 中引入了视觉微调功能,允许开发者使用图像和文本来提高 GPT-4o 的性能,尤其是在涉及视觉理解的任务中。
OpenAI 还推出了模型蒸馏功能,允许开发者使用更大的 AI 模型来优化较小的模型,并提供了一个评估工具来衡量微调性能。
OpenAI 的 prompt caching 功能与 Anthropic 几个月前发布的类似功能相似,可以减少成本并提高延迟。
OpenAI 发布新交互界面 Canvas:OpenAI 于10月3日推出了名为 Canvas 的全新交互界面,这是 ChatGPT 自发布以来的首次重大界面升级。Canvas 是一个能够与 ChatGPT 并肩作战的界面,适用于写作和编码等多种任务。该界面基于 GPT-4o 构建,目前处于测试阶段,所有 Plus 用户可以直接使用,未来计划向所有免费用户开放。Canvas 支持研究、写作、编码和邮件撰写,并具备代码审查、修复 bug、添加评论等功能,极大地提升了用户的工作效率。在提升 GPT-4o 编码性能方面,Canvas 显示了显著效果,并对现有编码工具如 GitHub Copilot 和 Cursor 带来了潜在影响。
Meta 推出视频生成模型 Movie Gen:Meta 在其博客中首次公开展示了名为 Movie Gen 的生成式 AI 研究成果,该模型在视频生成领域展示了突破性的能力。Movie Gen 不仅能够根据文本提示生成高质量的视频和音频,还能对已有视频进行编辑,甚至可以从图片生成视频。Meta 强调,Movie Gen 的设计旨在为电影制作人和视频创作者提供有助于提高创造力的工具。Movie Gen 使用了一个 30B 参数的 Transformer 模型,能够生成长达 16 秒的高质量视频,并且在物体运动、主客体交互和相机运动等方面表现出色。此外,Movie Gen 还支持个性化视频生成,用户可以提供人物图像和文本提示,生成包含特定人物的视频。在视频编辑方面,Movie Gen 能够进行精确的像素级编辑,支持添加、移除和替换元素,修改背景和风格等高级编辑功能。音频生成方面,Movie Gen 能够基于视频和可选的文本提示生成高质量的音频,包括环境声音、音效和背景音乐。
Anthropic 推出的 Message Batches API 可以批量处理大量请求 价格便宜50%:Anthropic 于 2024 年 10 月 9 日发布了新的 Message Batches API,它允许开发者以每批 10,000 个查询为上限, 并且在 24 小时内以标准 API 调用价格的 50% 折扣进行处理。该 API 支持 Anthropic API 中的 Claude 3.5 Sonnet、Claude 3 Opus 和 Claude 3 Haiku,以及亚马逊 Bedrock 上的 Claude 的批量推理,并计划即将支持 Google Cloud 的 Vertex AI 上的 Claude 的批量处理。该 API 使得高吞吐量处理成为可能,提供更高的速率限制,以处理更大规模的请求量,而不会影响标准 API 的速率限制。它适用于不需要实时响应的大规模数据处理任务,如客户反馈分析、语言翻译等。
市场
AI教育硬件全景报告:近一年来,AI硬件在教育领域迎来爆发式增长——AI教育硬件产品层出不穷,从主流品类的AI学习机到新兴品类的AI学习灯、AI教育机器人等,新产品不断涌现;AI教育硬件的功能也日益丰富,从AI查词与翻译,到AI作文批改和AI口语陪练等,满足用户不同场景的学习需求;搭载大模型的AI学习机、AI词典笔、AI听力宝等教育硬件产品销售额大幅增长;广阔的市场前景也正在吸引互联网AI公司、教育科技公司、教育硬件公司等众多类型的玩家纷纷布局AI教育硬件赛道,此报告对消费级AI教育硬件的产品现状、未来趋势、企业竞争格局、市场规模、代表案例等进行了系统性研究。

AI智能助手产品分析报告:国内大模型C端产品的竞争现状梳理。

如何让AI作为“第二大脑”:a16z 整理的 「AI Brain」赛道,人生中的一个巨大挑战是如何传达你的感受、决策和行为背后的背景。作者 Justine Moore 描述了自己使用 ChatGPT 作为日记,记录思想和感受,甚至发送匿名的交流截图寻求建议。通过这种方式,她发现 AI 可以帮助个人在与他人沟通、自我理解和与应用交互方面的三个核心用例。在与他人沟通方面,AI 伴侣可以帮助用户以最简洁高效的方式表达内心思想,甚至可以根据与他人的过往互动来优化沟通。在自我理解方面,AI 可以帮助用户进行自我反思,提供关于用户优点和缺点的描述,并且可以帮助回忆起用户可能忘记的相关信息。在与应用交互方面,AI 可以让应用更好地理解用户,提供个性化的推荐和服务。
观点
对话Stability创始人:视频技术已进入工程阶段,2025年将是Agent元年:Stability AI 的创始人 Emad 在对话中分享了视频和生成式 AI 技术的最新进展,预测了 2025 年将成为 Agent 技术元年,并讨论了 AI 技术在视频制作、商业策略和开源生态系统中的应用与影响。
视频技术的工程阶段:我们已经拥有制作高质量视频的技术,但这些技术尚未完全整合,需要更多的技术架构突破。
Agent 技术的未来:2025 年将是 Agent 技术的元年,AI 将能够执行任务并返回结果,而不是同步处理。
AI 技术在视频制作中的应用:AI 技术正在改变视频制作的流程,包括创作、控制和构图,但仍需进一步的整合和优化。
商业策略的选择:在 AI 领域,既可以通过构建产品,也可以通过提供服务来实现商业化,两种模式都有其市场和优势。
开源经济学原理:开源模型的商业化依赖于围绕它提供实施服务和模型的垂直整合,以及通过优化和精确替换数据来降低成本。
AI 在消费级硬件上的运行:随着推理、量化等方面的优化,未来几年内,今天的 AI 模型将能够在消费级的硬件上运行。
Generative AI’s Act o1:红杉最新文章,谈到了o1的影响。
2024 年,生成式 AI 革命进入第三年,研究正向从快速预训练响应转变为推理时的推理,这一转变正开启新的自主应用的大门。AI 市场的主要玩家已经形成了稳定的平衡,随着 LLM 市场的稳定,推理层的发展和规模化成为了新的焦点。OpenAI 的 o1 模型(原名 Q*,又称 Strawberry)展示了真正的普遍推理能力,通过推理时计算实现了更深层次的推理,这标志着人工智能从快速模式匹配向更深思熟虑的推理的转变。AlphaGo 的成功启发了人工智能在推理方面的发展,展示了如何在推理时进行深入的搜索和模拟,以提高决策质量。然而,人工智能在构建价值函数和评估开放性问题时仍然面临挑战。Strawberry 模型通过强化学习和推理时计算的增加,展现了回溯和以新方式解决问题的能力,这表明了人工智能在推理方面的进步。
AI 的下一个前沿是从预训练的直觉反应(“系统 1”)向更深层次的、有意识的推理(“系统 2”)的飞跃,这要求模型在实时中推理决策。这种转变将推动推理云的发展,即根据任务复杂性动态扩展计算能力的环境。尽管存在一种观点认为会出现一个模型统治一切的情况,但目前 AI 市场在模型层面存在激烈的竞争,且模型很难直接转化为应用层的突破性产品。因此,应用层的 AI 公司正在开发复杂的认知架构,以提供领域特定的推理和服务。AI 转型的下一阶段是服务即软件,软件公司将劳动力转化为软件,这将扩大服务市场的规模。新的代理应用如 AI 律师、AI 工作助手等正在出现,这些应用通过降低服务的边际成本,正在扩展和创造新市场。对于投资者来说,基础设施和模型层面可能不是最佳的投资目标,而开发者工具和基础设施软件、应用层则更具吸引力。预计 reasoning 和 inference-time compute 的研发将对应用层产生深远影响,代理应用将变得更加复杂和稳健。未来,多智能体系统可能会普及,模拟推理和社会学习过程。人工智能的下一个重大突破可能是 AGI,这将是技术发展的下一个阶段。

Vol.23:为什么大语言模型仍无法做到真正的推理?
