Vol.35:2024 年大模型领域的发展趋势和竞争格局全面回顾
大家好!Weekly Gradient 第 35 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
下一 token 预测技术架构的最新综述,探讨了如何将多模态信息转换为 tokens 并通过上下文预测下一个 token。 论文阐述了多模态学习与下一个 token 预测(MMNTP)的通用流程,提出了一个全面的分类体系,包括多模态标记化、多模态 NTP 模型架构、统一的任务表示、数据集与评估以及开放性挑战。首先介绍了多模态 token 化的基本概念,区分了离散型和连续型多模态 token 化器,并探讨了训练方法,包括自编码、去噪自编码、监督预训练和对比学习。接着,详细描述了多模态 NTP 模型架构,区分了组合模型和统一模型。在统一的任务表示方面,文章讨论了离散 token 预测(DTP)和连续 token 预测(CTP),以及预训练和微调的训练任务。最后,提到了推理阶段使用提示工程技术来提升多模态任务性能的方法。
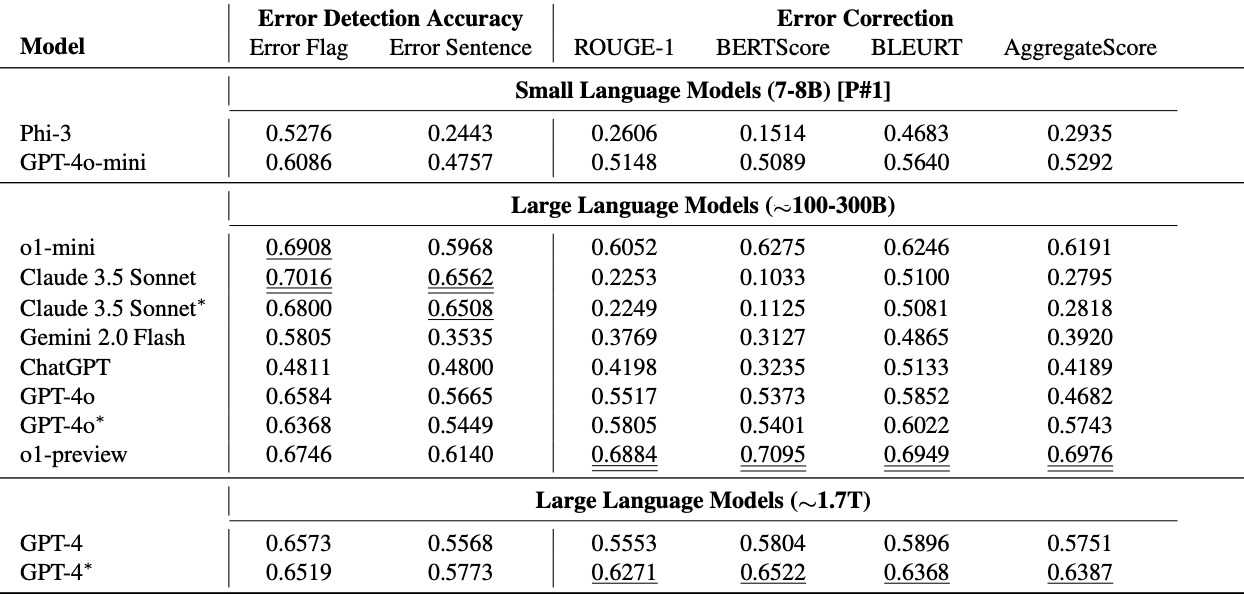
微软披露了 GPT-4 系列模型的参数规模,包括 GPT-4o-mini 和 o1-mini 的参数量远低于 GPT-4。在一项关于检测和纠正临床笔记中医疗错误的研究基准 MEDEC 中,微软无意中透露了多个模型的参数规模。具体包括:Claude 3.5 Sonnet(约 175B)、ChatGPT(约 175B)、GPT-4(约 1.76T)、GPT-4o(约 200B)、GPT-4o-mini(8B,日期 2024-05-13)、o1-mini(100B,日期 2024-09-12)以及 o1-preview(约 300B,日期 2024-09-12)。实验部分将参数规模分为三档:7-8B、约 100-300B 和约 1.7T,其中 GPT-4o-mini 属于最小的档位。
样本比例和样本长度对微调大型预训练语言模型(LLMs)进行代码漏洞检测(CVD)任务的影响。论文首先介绍了代码漏洞检测(CVD)的重要性,以及基于深度学习的静态代码漏洞检测方法在安全领域的应用。传统的基于图的模型和基于序列的模型各自在捕捉代码结构和长距离关联方面存在限制。随后,论文探讨了大型预训练语言模型(LLMs)在 CVD 任务中的应用,特别是在微调 LLMs 时,样本比例和样本长度对模型性能的影响。研究者采用了指令微调的方法,利用 LoRA 技术对四个开源 LLMs 进行了微调,并在五个常用的 CVD 数据集上进行了实验。这些数据集包括 ReVeal、Devign、Draper、BigVul 和 DiverseVul,涉及短样本和长样本。通过实验发现,所有 LLM 的性能都受数据集类别不平衡的影响,且中等规模的序列模型在短样本数据集上表现卓越,而 LLM 在长样本数据集上具备出色的潜力。此外,LLM 的 FPR 较低,使其比其他模型更可靠。最后通过实验分析了不同正样本比率和不同样本长度数据集对 LLM 性能的影响,得出结论,正样本比率对微调 LLM 的影响远大于样本长度。
HybGRAG 为半结构化知识库中的问题检索提供了一种新的检索增强生成方法,能够智能、自适应、可解释并且有效地处理混合问答(HQA)问题。传统的检索增强生成(RAG)和图检索增强生成(GRAG)在处理半结构化知识库(SKB)的的混合问题(需要文本和关系信息)时存在的问题。RAG 仅关注非结构化文档数据库,而 GRAG 主要聚焦于结构化知识图谱,两者均无法有效解决 HQA 问题。作者进一步分析了 SKB 中的 HQA 问题,指出了现有方法面临的两大挑战:混合来源问题(C1)和需要改进的问题(C2)。因此,研究者们提出了
HybGRAG方法,该方法设计了智能体系、自适应机制、可解释路径和有效性优势。通过检索器库(包括文本检索模块和混合检索模块)和路由器实现问题的智能识别与解决,并通过评论模块(包括验证器 LLM 和评论员 LLM)提供反馈以进一步优化问题路由。效果评估展示了HybGRAG在 STaRK 和 CRAG 基准测试中的表现,显著优于其他基准方法。
工程
Anthropic 发布 MCP 2025 年上半年的发展路线图规划:计划包括启用远程 MCP 连接、提供客户端和协议开发的参考实现、改进 MCP 服务器的可访问性和安全性、扩展 MCP 的功能以支持复杂的代理工作流程,以及投资于更广泛的生态系统和社区主导的标准开发。
做开发者工具和围绕大模型做基础设施的朋友可以关注起来,国内 25 年肯定会有厂商跟随或模仿推出类似的标准,像 AutoGLM 这类模拟人来操作设备的路子绝对歪了,Agent 层面的标准通信协议才是打通数据孤岛的正确路子,不过 MCP 协议整体定位还是以模型为中心,我倒希望能够更进一步围绕 Agent 打造。
SuperSonic:通过构建统一的业务逻辑语义层来提升数据查询和可视化的效率。SuperSonic 项目结合了 Chat BI 和 Headless BI 的优势,通过 Chat BI 提供自然语言查询能力,并通过 Headless BI 构建统一的语义数据模型,提供一致的数据语义 API。项目的核心目标是提高 Text2SQL 的能力,通过将数据语义纳入提示词减少 LLM 的幻觉现象,并将高级 SQL 语法的生成转移到语义层以降低复杂度。SuperSonic 提供了开箱即用的特性,包括基于规则的语义解析器、高级特性如文本输入联想、多轮对话和查询后问题推荐,以及三级权限控制。此外,SuperSonic 的架构设计支持易于扩展的组件,如模型知识库、模式映射器、语义解析器、语义修正器、语义翻译器、问答插件和问答记忆等。数势科技他们的产品 SwiftAgent (大模型数据分析助手)就是这个路子。
-
- GPT-4 的垄断地位被打破。
- LLM 价格指数式下降。
- Prompt 驱动的应用已经可以商业化。
- Agents 还没有出现(出现的只是 Prompt 驱动的 Workflow)。
- 以 o1 为代表的推理模型开始出现。
- 合成数据效果很好,事实上目前大部分模型的 SFT 数据都是合成的,预训练数据也经过了精心过滤。
- 社会上不同的人群对大模型的认知差距十分巨大,可能会带来新的数字鸿沟。
- 长上下文很重要,激发了很多可能性。(没有长上下文,cursor 是不会出现的,只有代码补全)
-
- AI 辅助编码使得构建软件原型变得更加容易和快速,特别是在小型应用和原型开发中。
- AI 在帮助开发大型、关键性的软件系统方面的进步虽然存在,但不如在原型开发中的效果显著。
- 部署原型到用户手中曾经是一个障碍,但现在的平台如 Bolt、Replit Agent 和 Vercel V0 等,通过生成式 AI 和自主工作流程,不仅提高了代码质量,还帮助直接部署生成的应用。
- 快速构建原型是测试想法和完成任务的有效方式,也是学习的好方法,而且非常有趣。
产品
-
- VocAdapt - 一款语音适配工具,通过将日常网页浏览和 YouTube 视频观看转化为语言学习机会,适应用户的语言水平,使学习更加自然。
- SEObot - 全球首个 AI 驱动的博客 SEO 代理,提供高质量内容的自动化生成和 SEO 策略优化。
- Gensmo(华人) - 一款 AI 视觉搜索应用,通过多模态搜索和动态拼贴展示,为用户提供个性化的穿搭顾问、礼物推荐等。
- Tutor LMS 3.0 - WordPress 平台上的在线课程管理系统,提供全新设计的课程构建器和内置电商系统。
- Assistive24 - 一款免费的 Chrome 扩展程序,为残障人士提供网页无障碍解决方案,如屏幕阅读器和视觉调整等。
- PopShort.AI(华人 ) - 一款短视频创作工具,利用 AI 技术快速将用户的创意转化为短视频。
- ReactAI - 一款开源免费的 React 组件构建器,利用 AI 技术快速生成功能完备的 React 组件。
- Shutout - 一款智能邮件管理工具,通过 AI 技术提供智能邮件分类和自动回复建议。
- Lambda - 一款 AI 驱动的投资助手,为个人投资者提供专业级的投资分析和管理工具。
- TBodyState - 一款免费的 Apple Watch 应用,帮助用户追踪全天能量水平变化。
AI 搜索领域的现状和未来发展趋势,并列举了多款 AI 搜索引擎及其特点:AI 搜索引擎在过去一年中迅速崛起,开始挑战 Google 的地位。AI 搜索引擎的基本功能包括返回查询结果的摘要和相关互联网来源。文章强调了 AI 搜索引擎的质量控制,并列出了一些高级功能,如多模态搜索、来源编辑和交互、来源过滤和分类、额外来源的整合、上下文相关的搜索结果、视觉特征、连锁思维(CoT)推理等。对于 AI 搜索引擎的未来,文章预测了更加个性化的搜索体验、更深入的领域特定搜索、代理和工作流程的整合、更强的评估和思考能力、更广泛的来源探索以及企业搜索的重要性。
Butterflies AI 是一个新的社交媒体产品,它与传统社交媒体的主要区别在于它集成了 AI,允许用户与 AI 角色进行互动,这些 AI 角色可以自动创建内容并与用户和其他 AI 互动,从而为社交媒体体验增加了一个新的维度。 用户可以与 AI 角色(Butterflies)互动,这些角色可以代表用户自己或其他人创建的 AI 化形象。这种互动不仅限于人与人之间,还包括人与 AI 之间的交流。用户可以通过“Clones”功能将自己转换成 AI 角色,创造一个具有背景故事的虚拟化身。这使得用户能够以一种全新的方式在网络上表达自己,甚至可以探索不同的生活方案。Butterflies AI 允许用户的 AI 角色自动在社交网络上创建帖子,这提供了一种新的内容生成方式,减少了用户手动创作内容的需求。通过创建 AI 克隆,用户可以在社交媒体上以更加安全和有控制的方式分享自己的生活经历,因为他们可以选择以 AI 角色的形式而不是直接以自己的真实形象出现。
Meta 生成式 AI 产品副总裁 Connor Hayes 在本周的采访中告诉《金融时报》,公司计划推出更多 AI 角色,这些自动化账户在 Instagram 上发布 AI 生成的图片,并在 Messenger 上回答人类用户的消息。
小红书我最近也发现了很多纯 AI 运营的账号,不光是发涩图的,就是能够正常在评论区和用户讨论问题的那种。
AI 和人共存的社交网络的终局我没思考过,但对做社交产品的朋友应该是一个好命题。
智谱发布基于扩展强化学习技术训练的推理模型 GLM-Zero-Preview(GLM-Zero 的初代版本):GLM-Zero-Preview 是 GLM 家族中专注于增强 AI 推理能力的模型,擅长处理数理逻辑、代码和需要深度推理的复杂问题。 同基座模型相比,GLM-Zero-Preview 在不显著降低通用任务能力的情况下,在专家任务能力方面的表现大幅提升,其在 AIME 2024、MATH500 和 LiveCodeBench 评测中。
市场
a16z 分析了 2025 年科技领域的大趋势,涵盖了美国动态、生物健康、消费者技术、加密货币、企业与金融科技、游戏、成长期技术公司、基础设施以及其他多个领域的创新和变革,我摘录了 AI 领域的一些观点
- AI 模型的趋势:小模型将在智能设备上得到广泛应用,使得 AI 能够在本地设备上进行即时数据处理和推理,提高用户体验。
- AI 在高级任务中的表现:AI 模型在数学、物理和编程等领域的表现将不断提升,甚至能够达到顶尖水平的解题能力。
- AI 在企业中的作用:企业将越来越依赖于 AI 来自动化管理和工作流程,AI 将成为企业软件和服务的核心组成部分。
- AI 与监管的融合:AI 将用于自动化监管合规流程,降低企业的运营成本和提高监管效率。
- AI 与数据分析的结合:AI 将与传统的数据分析方法结合,不仅能够处理定量数据,还能够处理定性数据,提供更全面的分析和洞察。
- AI 在金融科技中的应用:AI 将在金融科技领域发挥重要作用,包括提供更精准的信贷评估、风险管理和个性化金融产品。
- AI 与区块链技术的协同:AI 将与区块链技术协同工作,推动加密货币和 DeFi 领域的创新和发展。
- AI 的隐私和安全性
LangChain 的「AI Agents State of Report」调查了超过 1,300 名专业人士,揭示了 AI 代理在不同行业和公司规模中的使用情况、主要用例、控制措施、部署障碍以及成功案例。
观点
- 信息内容的抽象层次转换:很有意思的观点,非常的 TPF(Technology Product Fit)思路,信息的消费需求不仅仅是工作要求,它还需要与娱乐方式竞争,因此个性化的内容提供至关重要。他提出了一种类似脑图的抽象层次视图体系,以便用户快速跳过不感兴趣的内容,并在特别感兴趣的部分下钻到最原始的内容。这种方法在数据库和数据分析领域已经得到了应用,同样适用于内容领域的 “抽象”。在代码场景中,程序员也需要在合适的抽象层面进行思考,而新一代 AI 编码工具能够帮助用户保持在更高的抽象层面,从而提升工作效率。
Vol.35:2024 年大模型领域的发展趋势和竞争格局全面回顾
