Vol.36:YC 回顾 2024 年 AI 行业创业生态
大家好!Weekly Gradient 第 36 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
腾讯元宝的文档深度解析功能挺好用的,特别是读论文,以后的论文尽可能丢个元宝的链接,有翻译,有精读,有总结,方便大家阅读
EdgeRAG:解决在资源受限的边缘设备上部署 RAG 的挑战:这篇论文提出了一种名为 EdgeRAG 的新型 RAG 系统,旨在解决边缘设备的内存限制问题。EdgeRAG 通过剪枝不必要的二级嵌入、在执行过程中选择性地存储或重新生成它们以及缓存生成的嵌入来优化两级 IVF 索引。这种方法使得在超出可用内存的数据集上实现高效的 RAG 应用成为可能,同时保持低检索延迟且不降低生成质量。评估结果表明,EdgeRAG 在平均情况下将检索延迟提高了 1.22 倍,在无法适应内存的大数据集上提高了 3.69 倍。此外,EdgeRAG 在保持相似的召回率和生成质量的同时,显著减少了内存占用和计算开销。该系统的设计不仅适用于基本的文本数据,还可以扩展到支持多模态数据和更复杂的检索技术。通过利用现代边缘设备的硬件加速器,如神经处理单元(NPU),EdgeRAG 可以进一步提升嵌入生成和向量相似性搜索的性能。总体而言,EdgeRAG 为在资源受限的边缘平台上实现高效、可扩展的 RAG 应用提供了一种有效的解决方案。
TradingAgents: 一个基于大语言模型(LLMs)的多代理金融交易框架:这篇论文介绍了 TradingAgents,一个基于大语言模型(LLMs)的股票交易框架,旨在模拟真实交易公司的多代理决策过程。通过引入专门的角色如基本面分析师、情绪分析师、技术分析师和具有不同风险偏好的交易员,TradingAgents 能够有效地整合多样化的市场数据,并通过代理之间的辩论和协作做出明智的交易决策。实验结果表明,该框架在累计回报、夏普比率和最大回撤等关键指标上优于基线模型,展示了多代理 LLM 框架在金融交易中的潜力。此外,该框架的自然语言操作确保了高度的可解释性,使其在透明性和可解释性方面优于传统的深度学习交易算法。未来的工作将集中在将该框架部署到实时交易环境中,并扩展代理角色以进一步提高性能。
一篇关于 GraphRAG 技术的最新综述:全面总结了 GraphRAG 技术的现状、挑战和未来发展方向。GraphRAG 通过结合图结构数据和生成模型,增强了下游任务的表现,特别是在知识图谱、文档图谱、科学图谱等多个领域。论文提出了一个整体的 GraphRAG 框架,包括查询处理器、检索器、组织者、生成器和数据源五个关键组件,并详细回顾了每个组件的代表性技术。论文还根据不同领域的具体应用,分类讨论了 GraphRAG 的设计和技术细节,指出了当前研究的碎片化问题和数据集的不平衡问题。未来的研究方向包括图的构建、检索器的设计、组织者的优化、生成器的改进以及系统整体的评估和应用扩展。论文强调了跨学科合作的重要性,以推动 GraphRAG 技术的进一步发展和应用。
Github 地址:https://github.com/Graph-RAG/GraphRAG/
AgreeMate:训练大语言模型进行讨价还价:这篇论文介绍了 AgreeMate 框架,用于训练 LLMs 通过自然语言进行战略价格谈判。研究表明,使用提示工程、微调和链式思维提示可以显著提高 LLMs 在谈判中的表现。较大的模型通常能达成更多协议,表现出更高的公平性和较低的偏见。此外,模型的个性特征显著影响谈判过程,攻击性模型倾向于主导谈判,而被动模型则促进更平滑的谈判动态。注意力探针分析揭示了模型在谈判过程中对语义关系的关注,研究强调了在谈判场景中优化 LLMs 的重要性,并指出了当前模型在对话流畅性和现实性方面的局限性。
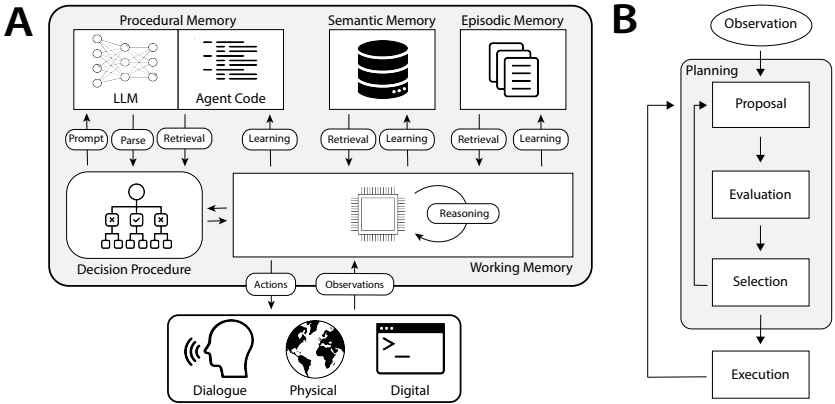
Agent 认知架构:这篇论文提出了认知架构语言代理(CoALA),旨在描述和构建语言代理。CoALA 借鉴了符号人工智能和认知科学的历史研究,提出了一个框架来组织现有的语言代理并指导新代理的开发。该框架通过模块化的内存组件、结构化的动作空间和通用的决策过程来定义语言代理。论文回顾了大量相关工作,并识别出未来发展的可行方向。CoALA 将 z 当今的语言代理置于更广泛的 AI 历史背景中,并概述了一条通往基于语言的通用智能的道路。
BaiJia: 中国历史人物角色扮演语料库:语料库包含了中国历史人物的信息,旨在提升大语言模型(LLMs)在历史角色扮演任务中的表现。通过整合来自不同来源的碎片化信息,BaiJia 填补了当前 LLMs 在角色扮演任务中的数据空白,特别是在低资源环境下。BaiJia 在增强 LLMs 的角色扮演能力方面的有效性,并提出了一个新的评估基准,涵盖六个维度:角色一致性、对话能力、角色吸引力、情感表达与智力深度、创造力与角色深度扩展以及文化与历史适宜性。实验结果表明,使用 BaiJia 语料库后,各种 LLMs 在这些评估维度上均取得了显著提升。BaiJia 为低资源历史 AI 角色扮演研究领域提供了一个宝贵的数据资源。
工程
速通 LLM 微调:手把手带你用 SiliconCloud 打造领域大模型:此前,SiliconCloud 上线了语言模型的在线 LoRA 微调功能。通过简单的上传语料数据、创建微调任务,就可以获得专属微调语言模型。 最近,SiliconCloud 的 LLM 在线 LoRA 微调,更是扩展了 Qwen2.5-32B、Qwen2.5-14B 以及 Llama-3.1-8B 模型作为微调基座模型,进一步丰富了微调的可玩性,也进一步降低了微调模型的训练、使用成本。 事实上,微调一个自己的专属大语言模型非常简单。使用 SiliconCloud 的微调功能,仅需准备几十条训练语料,就可以让模型产生“显著”区别于基础模型的变化。
eliza:Eliza 是一个针对开发者的开源 AI 框架,专为构建能够跨多个社交平台(包括 Discord、Twitter 和 Telegram)交互的 AI 助手而设计。Eliza 的核心亮点包括:能够构建多平台的 AI 助手;提供高级功能,如记忆系统、信息处理能力、自动化交易和多模型兼容;以及强大的扩展性,允许开发者自由定义 AI 的功能。
Ultravox:一个针对实时语音应用的快速多模态大语言模型。它能够直接将音频信号转换为大语言模型所使用的高维空间,从而省略了传统的语音识别(ASR)步骤。Ultravox 支持 Llama 3、Mistral 和 Gemma 等不同的 LLM 后端,并且能够以大约 150ms 的时间到第一个令牌(TTFT)和每秒 60 个令牌的速率工作。该模型目前能够接收音频输入并输出流文本,未来版本将支持直接生成语音令牌,进一步提高实时语音处理的效率和性能。Ultravox 的训练过程是可重复和可定制的。用户可以根据自己的需求选择不同的 LLM 或音频编码器后端,甚至可以使用自己的数据集来支持新的语言或应用场景。
nv-ingest:英伟达开源的一个针对多模态数据提取的微服务,它支持对 PDF、Word、PowerPoint 文档以及图像的内容和元数据进行解析和提取。该服务能够接受 JSON 格式的任务描述,执行一系列文档处理任务,并返回处理结果。它支持多种文档类型的提取方法,包括使用 pdfium、Unstructured.io 和 Adobe Content Extraction Services 等不同的 PDF 解析方法,以及使用 YOLOX 和 PaddleOCR 进行表格和图表的提取。它利用 NVIDIA NIM 微服务进行内容分类、提取和上下文理解,支持 OCR 技术将内容转换为 JSON 格式,并可选地计算嵌入向量和存储到向量数据库中。
这个项目来自 NVIDIA NIM Agent Blueprints 工具,官方在这篇博客对此进行了系统性介绍 为何企业需要 AI 查询引擎来推动代理式 AI?
微软 Phi-4 模型开源:Phi-4 参数规模 14B,效果非常好,超过 Qwen2.5-14B,某些方面超过 70B 的大模型 Llama3.3 70B、Qwen2.5 72B。
产品
AI 设计产品 Recraft 的故事:Recraft 是我唯一付费的一款 AI 辅助设计类产品,它能够生成带有长文本的图像,Recraft 的风格设计旨在解决特定任务或专业场景,并提供了创造力控制功能,Recraft 还提供了一些创意功能,如一键生成特定节日风格的图片和 meme 图。Recraft 的自研模型 Recraft V3 在 Artificial Analysis Text to Image Model Leaderboard 上超越了超过了 Midjourney、Ideogram、FLUX 等一众图像生成模型。Recraft 也在尝试让设计师对生成的图像拥有更多的控制,比如生成风格一致的系列图像,效果模拟(Mock up,指可以将平面图拓展到立体产品上),局部修改等,这也让 Recraft 被称为 AI 版的 Photoshop。本文是该 Rectaft 创始人兼 CEO 的采访。
Q:下一步,Recraft 打算做什么?
A:我们正在构建两个部分。一个是技术,也就是带有控制的模型。它包含图像生成,也包括各种用 AI 进行的图像编辑和设计编辑。现在,行业和模型、技术都还没有达到那个水平,设计师要获得需要的结果还很难。人们可能觉得它就是写一个提示词,AI 就能产出你想要的图像。但事实并非如此。它需要大量的迭代,在很多情况下,这甚至是不可能的。所以我们明年的目标是解决这个问题。目标是构建能够为用户提供足够控制的模型,让他们能够获得他们需要的结果。
第二个部分是工作流程。现在,作为一个设计师,你在使用 Recraft,你也在使用其他一堆工具,你要为所有工具付费,而且要在它们之间切换。我们真的想消除这种情况。我们希望我们的用户能够在 Recraft 中完全解决他们的任务,而不需要来回切换。
Cohere 发布企业级搜索产品 North: Cohere 将 North 定位于自动化处理内部财务互动和客户支持等任务的 AI 代理市场。
NVIDIA 在 CES 2025 上的展示内容。
- RTX 50 系显卡:RTX 5070 的性能媲美前代 4090,但价格仅为后者的 1/3,RTX 5090 内存增加至 32GB。
- DLSS4 技术:新增神经渲染功能,可实现多帧生成,显著提升帧率。
- 个人 AI 超算:Project Digits 个人 AI 超算计算机的推出,价格为 3000 美元,具备强大的算力,支持高达 2000 亿参数的 AI 模型。采用 Grace Blackwell NVLink72,全新的数据中心超级芯片。(虽然内存高达 128G,但是根据 NVIDIA Grace CPU 的 datasheet,Grace CPU 的内存带宽只有 512GB/s。所以跟 MacBook Pro M4 Max 差不多(70b-4bit 大模型大概 13token/s 的速度)。Project Digits $3000 提供 128GB 统一内存,对比 Mac mini 选配 64GB 统一内存需要 2899 刀,换四台 5090 更是太贵。所以 Project Digits 用来本地推理+微调看起来是很不错的选择。)
- NVIDIA Cosmos 平台:用于加速物理 AI 开发的平台,支持机器人和自动驾驶汽车的开发。(NVIDIA Cosmos 一种开源、开放权重的世界基础模型。它基于 2000 万小时的视频进行训练,权重从 4B 到 14B。Cosmos 提供两种风格:扩散(连续标记)和自回归(离散标记);以及两种生成模式:文本->视频和文本+视频->视频。研究人员和开发者,无论其公司规模如何,都可以在 NVIDIA 的宽松开源模型许可下免费商用。Hugging Face :https://huggingface.co/collections/nvidia/cosmos-6751e884dc10e013a0a0d8e6)
- 世界基础模型 WFMs:通过分析真实世界数据,生成和模拟虚拟世界,用于机器人和自动驾驶,一共分为三类:Nano,针对实时、低延迟推理和边缘部署进行了优化;Super,高性能的基线模型;Ultra,提供极致的质量和保真度,适合用于定制模型。
- 自动驾驶和机器人:利用 NVIDIA Omniverse 3D 和 WFMs 生成的合成数据,推动机器人和自动驾驶技术的发展。
让一个具身智能机器人真正学会怎么移动身体、怎么和物体交互, NVIDIA 认为最少得有三台计算机配合:
- 第一台是大规模训练系统,比如那些超级 GPU 集群,用来训练基础模型和算法。
- 第二台就是这个世界模型加数字孪生平台,给机器人提供各种模拟环境和虚拟数据,类似不停地做仿真测试、迭代动作。
- 第三台才是部署到机器人体内或车里那台小型计算机,负责实时决策和感知处理。
数字孪生概念起来这么多年, 要在 NVIDIA 手里真实现了, NVIDIA 不光握有算力,现在这个场景还有数据。
雷鸟发布 V3 AI 眼镜:雷鸟 V3 AI 眼镜的核心优势包括:轻量化设计(重量仅 40 克,搭载骁龙 AR1 芯片,采用台积电 4nm 制程工艺)、长续航时间、快速 AI 响应(基于阿里通义千问模型)、高画质影像能力(与母公司 TCL 合作优化光学性能,硬件采用索尼 IMX681 背照式传感器,像素达 1200 万),以及相比 Meta 产品更具竞争力的价格(售价 1799 元)。销售渠道方面,雷鸟与博士眼镜合作,产品宣传全程都在对标 Meta 的 Ray-Ban,雷鸟创新创始人兼 CEO 李宏伟在发布会上表示,“对我们而言,目标非常明确:就是要让 V3 在耳机、相机、AI 和眼镜四方面的体验上全面超越 Meta,真正站在 Meta 的肩膀上,设计一款超越 Meta 的产品。”
今年肯定有大量 AI 眼镜发布,这款产品也算是打了个样,产品能力和配置水平,以及定价可以作为一个基准。
CES 2025 上其他有亮点的硬件产品
- Timekettle 推出最新的 W4 Pro 耳机:支持多种语言之间的即时翻译,能够在不同的通讯平台上实现双向翻译。支持一对一模式:与他人共享耳机,进行面对面的实时翻译;支持听录播放模式:通过应用录制音频并接收翻译,之后可以回放;支持语音模式:将耳机中的翻译语音通过手机扬声器播放,适用于会议或演讲。(售价为 449 美元)
- Based Hardware 推出 AI 穿戴设备 Omi,Omi 可以通过脑机接口检测用户是否在与设备交谈,提供更加个性化的交互体验。用户只需说出「嘿,Omi」即可激活 AI 助手,进行问题回答、对话总结、创建待办事项以及会议安排等操作。设计小巧,可以佩戴在颈部,或者使用医用胶带固定在头部侧面。Omi 基于开源平台开发,用户可以清晰了解数据处理流程,并有选择将数据保存在本地。设备会持续监听用户的声音并使用 GPT-4o 进行处理,同时根据用户的背景信息提供个性化建议。开发者可以自行构建应用或使用他们选择的 AI 模型。Omi 的应用商店上线了超过 250 款应用,为用户提供了丰富的功能和服务。(价格为 89 美元,预计于 2025 年第二季度开始发货,开发者版本的 Omi 则以约 70 美元的价格即刻发货)
市场
TAAFT 年终总结:如果你关注 AI 工具,你一定知道一个很火的网站叫 TAAFT (there is an ai for that),一个按照使用场景收录 AI 工具的网站,它发布了一份关于 2024 年 AI 工具趋势分析报告。涵盖了 AI 工具开发的主要趋势、新兴 AI 类别分析、垂类市场增长统计以及对 AI 行业未来的预测。报告中还包含了一些具体数据,例如美国是提交 AI 工具最多的国家,Freemium 定价模式成为 AI 工具最常用的模式,以及人们偏好在秋季和周二发布 AI 产品。中文版
-
- 模型的选择和多样性减少了垄断定价的可能性。随着多个 AI 模型的出现,其他能力如产品能力、销售能力等变得更加重要,而不是仅仅依赖模型本身。
- AI 的应用已经超越了聊天层面,进入了智能体化的概念。AI 应用不再仅限于聊天机器人,而是开始在各个领域实现智能化,如语言学习、客户支持等。
- 开源模型和多模型架构的使用促进了 AI 初创企业的发展。开源模型如 Llama 的推出,以及公司采用多模型架构来优化不同任务的处理,为 AI 初创企业提供了新的发展路径。
- 初创企业可以在不筹集大量资本的情况下实现快速增长和收入实现。例如,Opus Clip 在短时间内实现了数千万美元的收入,而且没有进行正式的 A 轮融资。
- AI 在垂直领域的应用变得越来越专业和细分。AI 语音、机器人和 AI 编程等领域的应用越来越多样化,满足不同行业的具体需求。
- AI 编程工具的进步改变了编程面试和招聘策略。AI 编程工具的普及使得编程面试的方式和招聘要求发生了变化,更多地关注对 AI 工具的使用能力和生产力。
观点
只有大公司能继续做超大模型:近日,零一万物 CEO 李开复在《晚点对话》中表示,未来超大模型的研发可能主要由大企业推动。零一万物将继续进行预训练,但不再追求超大模型。他认为,实现人工通用智能(AGI)需要大量资源,而零一万物目前的首要任务是加强自身的竞争力。
-
- AI4S 将推动科学研究范式的变革,2025 年多模态大模型将更多地融入科学研究,帮助科学家解决复杂的科学问题。
- 具身智能的发展将进入元年,具身大小脑和本体的协同进化将是关键趋势,具身智能将在工业场景下有更多应用。
- 多模态大模型的进化将通过统一的多模态数据训练实现更高效的 AI,这是 AI 技术发展的关键方向。
- Scaling Law 的扩展将继续推动基础模型性能的提升,强化学习在后训练和推理阶段将得到更多应用。
- 世界模型的加速发布将赋予 AI 更高级别的认知和推理能力,有望推动 AI 在自动驾驶等领域的深度应用。
- 合成数据的重要性将作为大模型迭代和应用落地的重要催化剂,有助于提高模型处理复杂问题的能力。
- 推理优化的加速是 AI Native 应用落地的必要条件,算法和硬件的优化将共同推动 AI 应用的发展。
- Agentic AI 的重要性,更通用和自主的智能体将重塑产品应用形态,成为大模型产品落地的重要模式。
- AI 超级应用(Super APP)的兴起,尽管尚未确定哪些应用将成为最终的赢家,但 AI 应用的热度正在上升。
- AI 安全治理体系的完善是模型能力提升与风险预防并重的重要部分,需要引入新的技术监管方法平衡行业发展和风险管控。
Vol.36:YC 回顾 2024 年 AI 行业创业生态
