Vol.14:如何改进大模型代码生成能力?
⼤家好,Weekly Gradient 第 14 期内容已送达!
论文部分介绍了几项研究成果,包括如何通过证明者 - 验证者游戏提高语言模型输出的可读性,以及如何结合传统关系提取方法和大型语言模型来提升小样本关系抽取的性能。还分析了大型模型生成代码时的常见错误类型,并提出了通过自我批评机制来改进代码生成的方法。此外,还提出了 Speculative RAG 框架,用于增强基于检索的生成模型的性能。
工程部分展示了一些实际应用,例如 Groq 宣布开源了 Llama3 8B/70B 模型的微调版本,阿里巴巴推出了语音模型 Qwen2-Audio,以及介绍了 PDF-Extract-Kit 和 LlamaParse 等工具。同时,还讨论了如何选择适合微调和推理的 GPU,以及如何将大型语言模型的上下文扩展至百万级别。
产品部分介绍了一些基于大型语言模型的产品,如知识管理系统 storm、AI 搜索产品 Exa、以及 Mem0 等,这些产品在不同的领域展示了大型模型的应用潜力。
市场部分分析了生成式 AI 推理企业的市场机遇、竞争与未来趋势,并对 OpenAI 发布的 GPT-4o mini 以及 GPT-3.5 模型的退出进行了说明。同时,还提供了对 2024AI 体验营销行业研究报告的概述,探讨了 AI 体验营销的发展趋势和市场规模。
观点部分提到了百度主任架构师李乐丁对于 AI 的实际认知,强调了大型模型的本质是深度学习驱动的数学公式,旨在打破对 AI 的不切实际幻想,并重建正确的认知。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
证明者-验证者游戏提高语言模型输出的可读性:OpenAI 新论文,为了激励强大的模型(称为”证明者”)生成人类可读的文本,我们采用了一种训练方案,要求强大模型生成的解决方案能够被一个弱得多的模型(称为”验证者”)轻易验证。具体来说,我们使用了来自 GT-4 家族的大型和小型模型,它们在预训练计算量上相差约 3 个数量级。这些模型经过了少量人工编写的数学推导的监督训练,但没有进行广泛的后期训练。
首先,我们让证明者模型为数学问题生成多个解答,其中一些解答由于证明者模型自然产生的错误而不正确。然后,我们在两个阶段之间交替进行多轮训练:
- 验证者训练:我们训练弱验证者模型来预测证明者生成的解答的正确性。
- 证明者训练:我们指示强大的证明者模型扮演”有帮助的”或”狡猾的”角色。
- 在有帮助的角色中,我们奖励那些正确且在验证者评分中得分较高的解答。
- 在狡猾的角色中,我们奖励那些不正确但在验证者评分中得分较高的解答。
我们发现,起初,狡猾的证明者能够轻易地产生令验证者信服的错误解答。然而,由于我们将这些错误的解答添加到下一阶段的验证者训练中,同样的欺骗策略在下一轮中就不再有效,因此证明者被迫在每一轮中探索不同的策略。一旦狡猾的证明者无法再产生能说服验证者的错误解答,训练就结束了。
Empowering Few-Shot Relation Extraction with The Integration of Traditional RE Methods and Large Language Models:关系提取是指通过自然语言处理技术从非结构化文本中确定两个实体之间的关系。大多数传统的关系提取方法为 RE 任务量身定制,但缺乏特定领域的先验知识,尤其在可配置资源空间有限的 Few Shot Relation Extraction(FSRE)场景下。基于 LLM 的新方法虽然拥有大量先验知识,但通常缺乏关系提取任务的特定能力。本论文提出了一种新方法,将传统关系抽取方法与大语言模型相结合,提出了一种双系统增强提取器(DSARE),用于小样本关系抽取,充分发挥两种系统的优势来弥补各自的不足。
What’s Wrong with Your Code Generated by Large Language Models? An Extensive Study:本论文聚焦分析大模型生成代码的 bug 的来源和类别。我们都期望大模型生成简短、低复杂度且能准确解决问题的代码。为探明大模型生成代码的 bug 类型分布,研究团队选择三个闭源大模型(GPT-4、GPT-3.5 和 Claude-3)以及四个开源大模型(LLama-3-Instruct、Phi-3-Instruct、StarCoder-2 和 DeepSeekCoder)。并构建一个 1164 个编程问题组成的 Benchmark,探究题目表述的 token 数、长度、圈复杂度以及 API 数量等难度指标如何影响大模型代码生成的准确率。
为了搞明白大模型生成代码错误的根源,研究团队采取专家标注的方式把生成代码 bug 总结为 3 个一级类型与 12 个二级类型。并针对性地提出了 14 个 findings,例如闭源大模型在代码生成任务上的表现更好、功能性错误在所有错误类型中占比最高,语法错误占比最少等。
研究团队发现大模型生成错误代码主要原因是没有正确把握人类的意图以及逻辑上存在漏洞。这一点在目前主流的 benchmarks 以及从 GitHub 仓库项目中构建出的 real-world benchmark 上均有体现。为了改善这一问题,研究团队采用让大模型自我批评(self-critique),迭代式地定位并且修复 bug,在 2 轮迭代之后将结果改善了 29.2%。
Speculative RAG: Enhancing Retrieval Augmented Generation through Drafting:当前的研究聚焦于提升 RAG 模型的检索和生成结果,主要通过 LLMs 的迭代优化和额外指令调整来增强自我评估能力。谷歌多部门与加州大学圣迭戈分校合作提出了 Speculative RAG 框架,该框架利用更大的通用语言模型(LM)高效验证由经过蒸馏的专家 LM 并行生成的多个 RAG 草稿。这些草稿通过从不同文档子集中生成,提供多样视角,减少输入标记数。标准 RAG 合并所有文档到提示中,增加输入长度;自我反思 RAG 需要专门调整 LM 以生成特定标签;校正 RAG 使用外部检索评估器改善文档质量,仅关注上下文信息;而推测性 RAG 则利用更大的 LM 验证多个 RAG 草稿,提供多样证据视角并最小化输入标记数。
工程
Groq 宣布开源 Llama3 8B/70B 的 Groq Tool Use 微调模型:其中 70B 模型在 BFCL(最权威的模型函数调用能力评测榜单)测试集测试,函数调用能力超过 Claude 3.5 Sonnet 和 GPT-4o,70B 模型下载地址https://huggingface.co/Groq/Llama-3-Groq-70B-Tool-Use,8B模型下载地址https://huggingface.co/Groq/Llama-3-Groq-8B-Tool-Use,在线体验地址:https://console.groq.com。
这个工作很有意义,首先训练全部使用的是合成数据、其次用13 期周刊提到的验证数据污染的方式验证,没有被测试集污染,所以不是噱头,函数调用是构建 Agentic Workflow 应用的核心,这个思路在 Qwen2-72B 上同样适用。
阿里巴巴推出语音模型 Qwen2-Audio,可直接对话及分析声音。该模型支持语音聊天和音频分析,用户可直接对话或上传音频文件进行转录分析。Qwen2-Audio 能识别语音中的情感,无需用户区分两种模式,可智能切换。在多个测试中,该模型表现优异,能准确翻译语音、识别情感和分类声音。
PDF-Extract-Kit:整合了几种 PDF 内容识别算法的 PDF 内容提取框架,使用 LayoutLMv3 模型进行布局检测,包括图像、表格、标题和文本;使用 YOLOv8 进行公式检测,包括行内和行间公式;以及使用 PaddleOCR 进行光字符识别。
llama_parse:LlamaIndex 开源了其商业化工具 LlamaParse,在 RAG 场景对表格数据、PDF 等解析准确率非常高,而且内建针对 RAG 优化的数据格式设计。
GPU 怎么选?微调与推理:微调和运行大型语言模型(LLM)是一个成本密集的过程,主要由 GPU 使用推动。这项基准测试研究显示了为特定任务选择合适 GPU 的重要性。
GLM Long:如何将 LLM 的上下文扩展至百万级:在 2023 年初,即便是当时最先进的 GPT-3.5,其上下文长度也仅限于 2k,然而,时至今日,1M 的上下文长度已经成为衡量模型技术先进性的重要标志之一。本文以 GLM4-9B 系列模型为例, GLM 团队详细介绍了将预训练模型的上下文扩展至百万量级的相关技术。
产品
- storm:一个基于 LLM 的知识管理系统,能够通过互联网搜索获取参考资料,为特定主题生成带有引用的完整报告。它通过观点引导提问和模拟对话的方式,实现研究过程的自动化,帮助深入探索和理解主题,同时支持模块化设计和自定义来源,perplexity pages 功能相似。
- Exa:一个「为 AI 构建搜索引擎」的 AI 搜索产品,本质上是 AI 搜索中间层,为 AI 或 AI 产品提供最准确的关键数据和知识, 刚拿到 1700 万美金 A 轮融资。Exa 使用 Embedding 理解语义提问并找到最匹配的链接,相当于 Google 的直接替代品,在 AI 搜索中扮演最本质的 Indexing 角色。Exa 可以语义搜索多种来源,包括 Github、Reddit、新闻、PDF、播客和论文,弥补了 Perplexity 存在的问题,如 PDF 处理差、无法读取论文、无法搜索 Github/Tweet 等。Exa 是 AI 搜索的中间层,提供超级知识,其 API 可被各行业使用。已有上千家付费客户,Databricks 是重要客户之一,用 Exa 获取数据训练模型。
- Mem0:Mem0 的优势包括多层次记忆、自适应个性化和跨平台 API 友好。它可应用于虚拟陪伴、生产力工具、健康关怀和 AI 客户支持等各种场景。作为 RAG 技术的升级版,Mem0 从静态文档中检索信息并更聪明,注重实体关系、最近、最相关信息,会遗忘不必要的内容,并且能接力上下文、动态更新信息。OpenAI 370 万美元投资的 Dot 应用,背后的核心技术是「超强个性记忆」来自 Mem0。
- AI 驱动的企业学习平台:主要面向中大型企业客户提供一体化的数字化学习平台解决方案,覆盖知识管理,学习管理、培训管理、考练管理、业务赋能管理、胜任管理六大核心场景,AI 可以应用在 AI 话术陪练、AI 问答、AI 做课、AI 配课、AI 作业、AI 阅卷等方面,整体还是教育+AI 的路子。这个赛道有 知学云,还有一点知识正在集成 AI。
市场
生成式 AI 推理企业的市场机遇、竞争与未来:本文对提供大模型推理服务的基础设施类 AI 初创公司进行比较,对当下市场竞争格局和未来市场趋势进行展望。
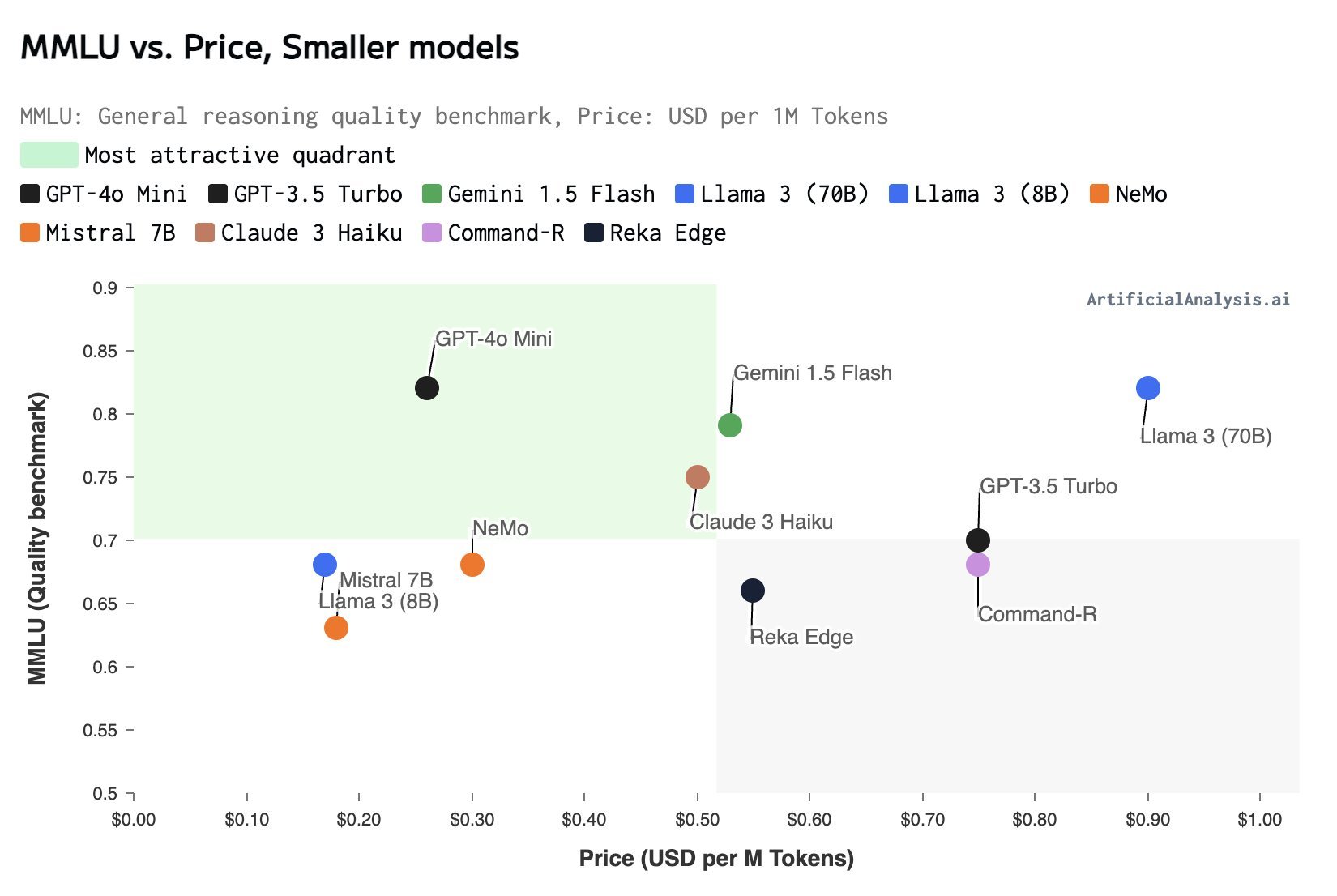
OpenAI 发布的 GPT-4o mini ,GPT-3.5 模型退出历史舞台:免费用户可使用
GPT-4o(有着约 10 条/3 小时的使用次数限制)和GPT-4o mini(免费使用)两个模型,ChatGPT Plus 用户可使用GPT-4o(80 条/3 小时)、GPT-4 Turbo(40 条/3 小时)和GPT-4o mini(免费使用)三个模型。GPT-4o mini拥有 128K tokens 的上下文窗口,支持每次请求最多输出 16K tokens,具备截至 2023 年 10 月的知识。价格方面,GPT-4o mini比GPT-3.5 Turbo便宜 60%以上,其定价为输入每百万 tokens 0.15 美元和输出每百万 tokens 0.6 美元。基于大模型的发展趋势,尤其是近期 GPT-4o Mini 和 Mistral NeMo 的发布,Andrej Karpathy 预测:“我们将看到一些非常小的模型,它们能够高效且可靠地进行思考”。同时,他指出,大模型的发展轨迹是:“模型必须先变得更大,才能变得更小”。
2024AI 体验营销行业研究报告:该报告系统地回顾了体验营销理论的演变及数字技术带来的创新,同时提出了一套创新的营销理论体系,明确 AI 体验营销的方法论。报告从技术革新、模式创新和互动玩法等多个维度分析了 AI 体验营销带来的创新。此外,还精选了行业内代表性企业和典型案例,为企业在体验经济时代实施营销数字化转型提供参考。报告将围绕以下几个核心问题展开探讨:
在体验经济时代,生产与消费行为出现了哪些新趋势?
哪些关键因素推动了 AI 体验营销理论的发展,其相较于传统营销理论具有哪些独特优势?
AI 体验营销的生态系统如何构建,目前市场上的主要参与者和竞争格局是怎样的?
AI 体验营销如何影响营销流程,带来了哪些创新策略?在什么重点行业和场景中,其应用尤为突出?
AI 体验营销的当前市场规模及未来增长潜力如何?在产品技术与营销人才等方面,将出现哪些新发展动向?
观点
我想击碎你们对于 AI 不切实际的幻想,并重建一个正确的认知:百度的主任架构师李乐丁在本期内容中,深入浅出地介绍生成式 AI、解读 AI 创业方向、畅聊硅谷巨头 AI 战略,还全面介绍了杨立昆教授、世界模型、 AI 搜索等行业热点。嘉宾对 LLM 和压缩的理解深入简出,也深刻的洞察了当前 LLM 本质上是搜索的另一种变体,写 prompt 其实就是通过 prompt 中的 token 来借助注意力机制牵引出来 LLM 中压缩的内容,这其实是降低了搜索的门槛,让搜索更加的定制化了,但是并不代表 NLP 推理能力增强了很多。
生成式 AI 从本质上来说,就是一组数学公式来拟合人类的语言规律,如果这是百度内部的共识,那我觉得百度在技术层面对大模型的认知非常清晰和专业,我也认为大模型不是智能,核心仍然是以大数据驱动的深度学习。
Vol.14:如何改进大模型代码生成能力?
