Vol.15:大语言模型应用如何实现端到端优化?
⼤家好,Weekly Gradient 第 15 期内容已送达!
论文部分提到了一种优化查询生成的方法 QOQA,用于提升 RAG(Retrieval-Augmented Generation)中的文档检索准确性。AGENTPOISON 是一种针对 LLMs 代理的红队攻击方法,通过毒化记忆或知识库来实现攻击。另一篇论文探讨了在递归生成的数据上训练 AI 模型时可能出现的问题。微软亚洲研究院提出了 Parrot 系统,以优化 LLMs 应用的端到端性能。
在工程实践方面,文章详细分析了 RAG 技术的应用和挑战,以及 LangChain 博客中提出的增强代理规划的方法。WWDC 24 介绍了使用 Core ML 运行 Mistral 7B 的方法。微软推出了 MInference 工具,用于优化长上下文语言模型的推理过程。
产品发布部分包括了开源模型 Llama-3.1 的发布,Mistral Large 2 的推出,以及 OpenAI 宣布的 AI 搜索引擎产品 SearchGPT 的内测。智谱 AI 推出了新一代视频生成模型 CogVideoX,DeepSeek API 也进行了升级。
市场动态部分梳理了 15 家获得投资的 AI 搜索公司的情况,发布了《生成式 AI 商业落地白皮书》,并统计了六个城市在人工智能赛道的融资情况。还讨论了 Voice Agent 作为 AI 时代的交互界面。
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
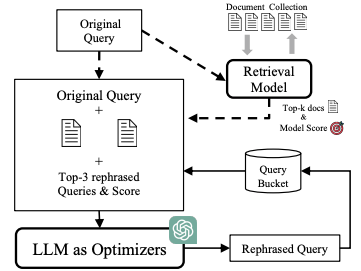
优化查询生成以提升 RAG 中的文档检索:本论文提出了一种精确查询优化方法(Query Optimization using Query expAnsion,QOQA),通过前 k 个平均查询-文档对齐得分,利用 LLMs 优化查询。该方法计算效率高,能提升文档检索的准确性并减少误导。首先,输入原始查询,通过检索器获取相关文档。接着,将原始查询与检索到的顶级文档合并,形成扩展查询,并提交给 LLM 生成一系列重新表述的查询。改写后的查询将根据与检索文档的契合度进行评估,相应的查询-文档对齐得分及查询文本将被存入查询池,其中查询-文档对齐得分分为三种:基于稀疏检索的 BM25 分数、基于密集检索的密集分数、融合了稀疏与密集检索的混合分数。
AGENTPOISON:通过毒化记忆或知识库对大语言模型代理进行红队测试:大模型代理在众多应用中表现出色,这主要归功于它们在推理、利用外部知识、调用 API 以及与环境互动等方面的先进能力。目前,这些代理普遍采用记忆模块或增强检索生成(RAG)机制,从知识库中检索历史知识和相似实例,以辅助任务规划和执行。然而,对未经验证的知识库的依赖也引发了对其安全性和可信度的严重担忧。为了揭示这些潜在的脆弱性,本论文提出了一种创新的红队攻击方法——AGENTPOISON。这是首次针对通用和基于 RAG 的 LLM 代理的后门攻击,目的是通过污染它们的长期记忆或 RAG 知识库来实现。论文将触发器的生成过程转化为一个受约束的优化问题,通过将触发实例映射到一个独特的嵌入空间来优化后门触发器,确保当用户指令中包含这些优化后的触发器时,恶意示例能以高概率从被污染的记忆或知识库中被检索出来,同时,不含触发器的正常指令仍能维持其正常性能。AGENTPOISON 与传统的后门攻击不同,它不需要额外的模型训练或微调。优化后的后门触发器表现出了更好的可迁移性、上下文一致性和隐蔽性。通过广泛的实验,AGENTPOISON 在攻击三种真实世界的 LLM 代理(包括基于 RAG 的 Coplilot 代理、知识密集型问答代理和医疗电子健康记录代理)方面的有效性,通过将毒化实例注入这些代理的 RAG 知识库和长期记忆中,展示了 AGENTPOISON 的通用性,在每个代理上,AGENTPOISON 都实现了平均攻击成功率 ≥80%,同时对正常性能的影响 ≤1%,毒化率<0.1%。相关代码和数据可以在以下 GitHub 获取:https://github.com/BillChan226/AgentPoison。
利用 RAG 构建应用的目的是降低 LLM 的幻觉,但是如果是在知识库直接投毒呢,论文团队的投毒思路很妙,对应用正常性能影响很低,让用户不易察觉,但是一旦命中对应案例,成功率很高。
当人工智能模型在递归生成的数据上训练时,会崩溃:来自牛津大学、剑桥大学、帝国理工大学、多伦多大学等机构的这篇论文,本周登上了《自热》杂志封面,研究者发现,如果在训练中不加区别地使用 AI 产生的内容,模型就会出现不可逆转的缺陷——原始内容分布的尾部(低概率事件)会消失,有人形容“合成数据就像是近亲繁殖,会产生质量低劣的后代”。研究团队认为,AI 生成的数据并不是完全不可接受,但必须对数据进行严格的筛选。比如,在每一代模型的训练数据中,保留 10%或 20%的原始数据;使用多样化的数据,例如人类生成的数据。
大语言模型应用如何实现端到端优化?:基于大语言模型(LLMs)开发的应用目前主要使用公共 LLMs 服务提供的 API 进行,但是这些 LLMs 服务的 API 设计以请求为中心,缺乏应用级信息,难以有效优化整个应用流程,影响任务的端到端性能。为此,微软亚洲研究院的研究员们开发了一个专注于 LLMs 应用端到端体验的服务系统 Parrot,它具有减少网络延迟、提高吞吐量、减少冗余计算等优势。Parrot 可以通过引入语义变量,向公共 LLMs 服务公开请求间关系,从而开辟了 LLMs 应用端到端性能优化的空间。相关论文已被计算机系统领域顶级学术会议 OSDI 2024 收录。
工程
- RAG 技术真的“烂大街”了吗?:本文详细分析了 RAG 技术在大语言模型中的应用,包括精准问答、推荐系统和信息抽取等领域的优势,以及面临的挑战,如数据杂乱、用户意图不明确时的语义 gap 等。文章强调了 RAG 技术与长上下文模型、Agent 的合作关系,指出 RAG 加 Agent 的本质是复杂问题的分治。此外,文章还探讨了 RAG 技术在推荐系统中的应用前景,以及与大模型结合的未来发展方向,包括多模态应用和数据安全性等关键点,以及如何打造 RAG 爆款应用。
- 代理规划:LangChain 最新博客,探讨了大语言模型 (LLM) 在代理规划和推理方面的局限性,特别是在长期场景中,虽然函数调用允许立即选择行动,但复杂的任务需要一系列步骤。本文提出通过向 LLM 提供全面信息、修改认知架构和采用领域特定方法来增强代理规划,值得注意的是,它强调了领域特定认知架构在通过硬编码特定步骤来指导代理方面的有效性,从而减少了 LLM 的规划负担,是对 LangGraph 设计哲学的阐述。
- WWDC 24: 使用 Core ML 运行 Mistral 7B:本文详细介绍了如何在 Apple 设备上使用 Core ML 运行 Mistral 7B 语言模型,重点介绍了 WWDC 24 中的新功能。文章解释了 Apple Intelligence 如何利用 Apple Silicon 实现设备端 AI,并介绍了 Core ML 的关键改进,例如 Swift Tensor,它简化了张量操作;Stateful Buffers,它在大型模型中实现了高效的状态管理;以及新的量化技术,用于减小模型尺寸。然后,文章指导读者完成 Mistral 7B 的转换和运行,包括模型追踪、使用 4 位线性量化进行量化,以及利用包含对这些新功能支持的 ‘swift-transformers’ 的 ‘preview’ 分支。最终结果是一个显著更小的模型(3.8GB 对比 14GB),可以在内存小于 4GB 的 Mac 上高效运行。文章最后强调了未来的方向,包括针对 iPhone 上的 Neural Engine 进行优化,以及将这些技术整合到 ‘exporters’ Python 工具中。
- 微软最新发布了一个推理工具 MInference:长上下文语言模型推理分为两个主要阶段:预填充阶段和解码阶段。在预填充阶段,模型处理输入的长上下文,通过计算注意力权重和生成初始的隐藏状态以便高效处理数据。解码阶段则是基于预填充阶段生成的隐藏状态,模型逐步生成输出,通常一个词一个词地进行,直到满足预定长度或终止条件。MInference 通过优化预填充阶段的时间,采用了稀疏计算方法,减少了注意力矩阵元素的计算量,从而加速了计算过程,Minference 主要适用于输入 token 长的情况。
产品
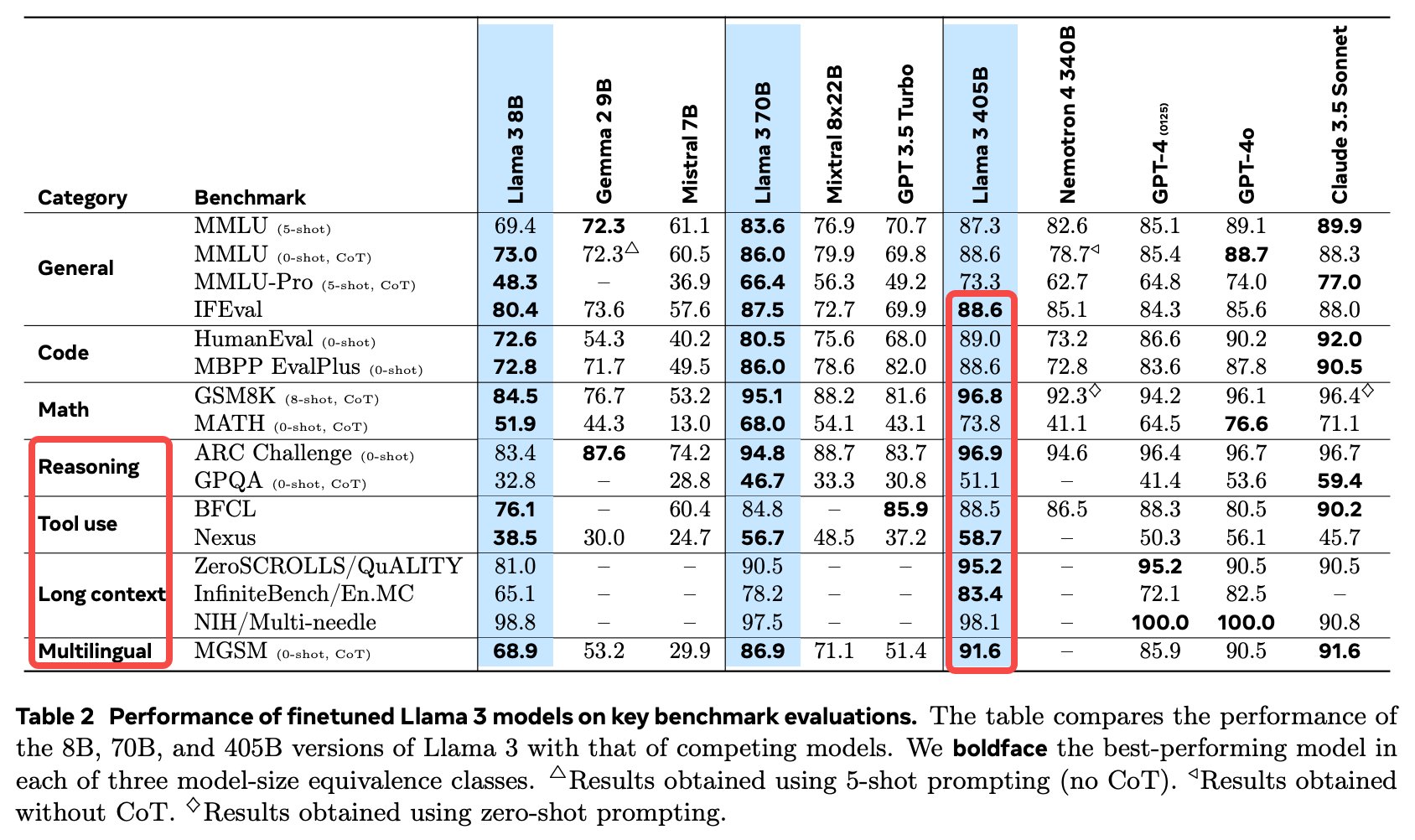
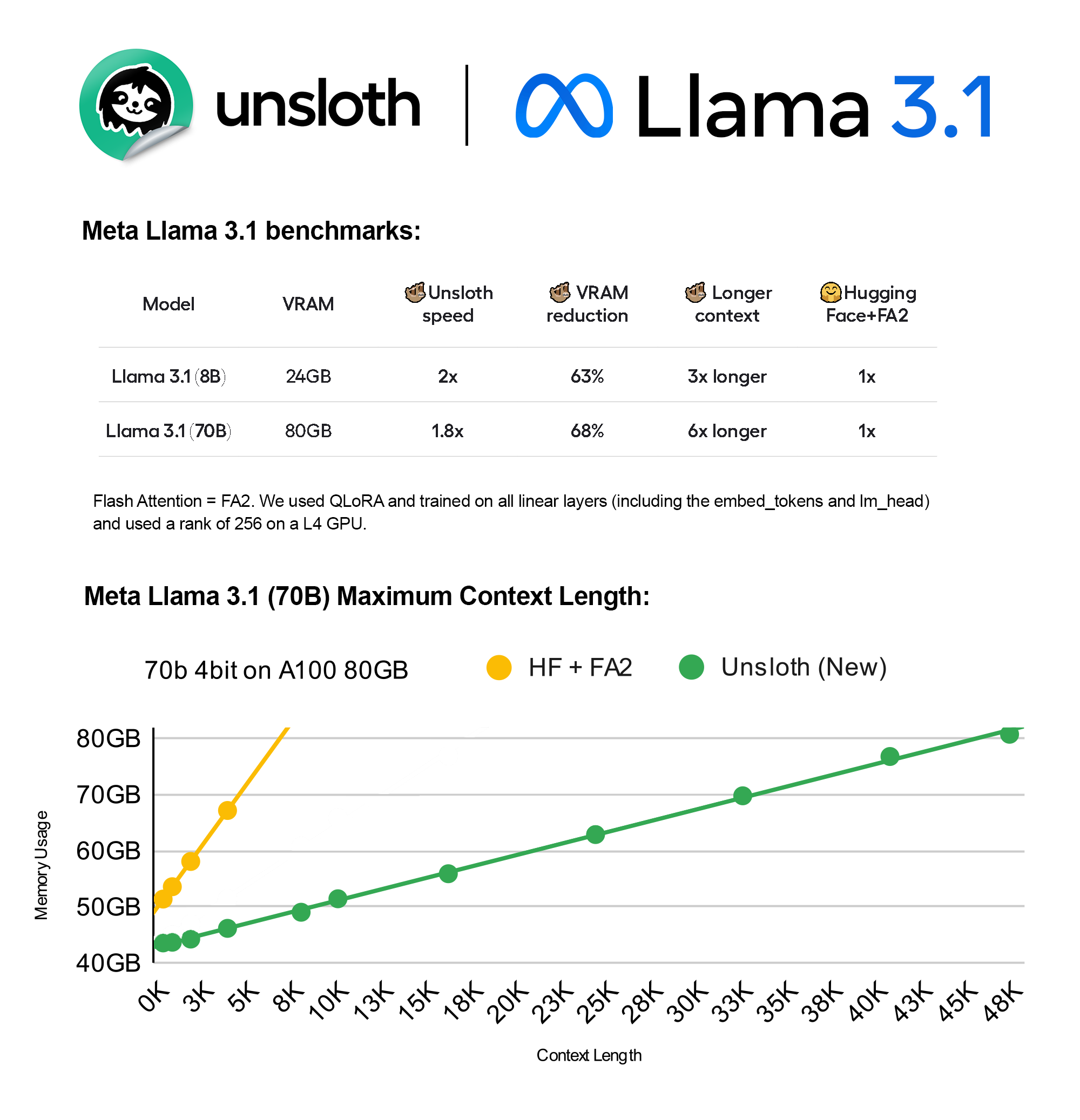
开源模型 Llama-3.1 正式发布:其最大参数达 405B,多个指标优于 GPT-4o 和 Claude-3.5-Sonnet,并发布了相关论文。支持多语言 SOTA,128K 上下文,具备类 Function Calling 能力;使用 1.6 万个 H100,公开数据达到 15T Token,不采用 MoE,提供合成数据生成微调(SFT)示例。这篇 HuggingFace 的技术解读值得一看
Llama 3.1 模型下载地址:https://llama.meta.com/
Llama 3.1 论文下载地址:https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
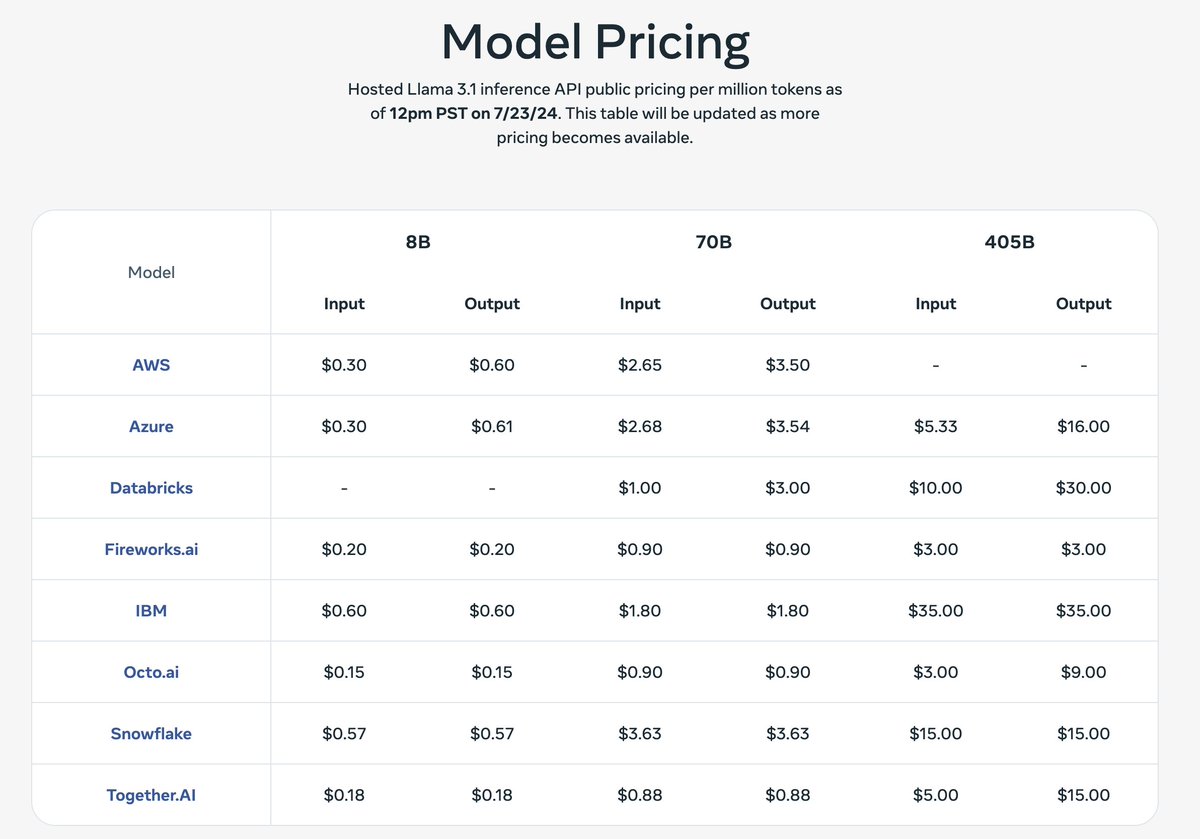
各家推理平台的模型价格:405 B 模型的价格和 GPT-4o 差不多。
Unsloth 平台支持对 8B 和 70B 两个规模的模型进行微调。:VRAM 减少 65%,推理速度提高 2.1 倍,可以在 8GB GPU 上运行
ollama 已支持 Llama 3.1 405B
Mistral Large 2 发布:Mistral Large 2 是法国 AI 公司Mistral AI 发布的新一代 AI 大语言模型, 与前代产品相比,Mistral Large 2 在代码生成、数学和推理方面的能力大大增强。Mistral Large 2 具有 128k 的上下文窗口,支持多种语言和 80 多种编程语言。该模型专为单节点推理和长上下文应用设计,参数量达到 1230 亿,具有高效的性能和成本优势。在评估指标上,Mistral Large 2 在 MMLU 上的准确率为 84.0%,超越了前一代模型,达到与市场领先模型相当的水平。此外,它在训练过程中注重减少信息“幻觉”的倾向,改进了推理能力和问题解决能力,能够准确承认自身知识的局限性。同时,该模型在跟随指令和进行多轮对话方面有显著提升,性能在多个基准测试中表现优异,特别注重生成的简洁性和高效性,以适应商业应用需求。新发布的 Mistral Large 2 模型使用了大量多语言数据进行训练,其在英语、法语、德语、西班牙语、意大利语、葡萄牙语、荷兰语、俄语、中文、日语、韩语、阿拉伯语和印地语等语言上表现优异。该模型在多语言 MMLU 基准测试中相比于之前的 Mistral Large、Llama 3.1 模型及 Cohere 的 Command R+展现了良好的性能。此外,Mistral Large 2 增强了功能调用和检索能力,适用于复杂商业应用。Mistral AI 还与主要云服务提供商合作,将其模型扩展到全球市场,包括与 Google Cloud Platform、Azure AI Studio、Amazon Bedrock 和 IBM watsonx.ai 的合作。
不论是开源的 LIama3.1 还是 Mistral Large 2 ,综合指标已经逼近 GPT-4o,这里引用 张俊林老师的一些观点,开源和闭源模型随着时间能力差异曲线,可以看出两者差距随着时间是逐步减小的,而 LLaMA 3 405B 让两线出现了交点,我想这图基本可以终结“开源闭源之争”了。
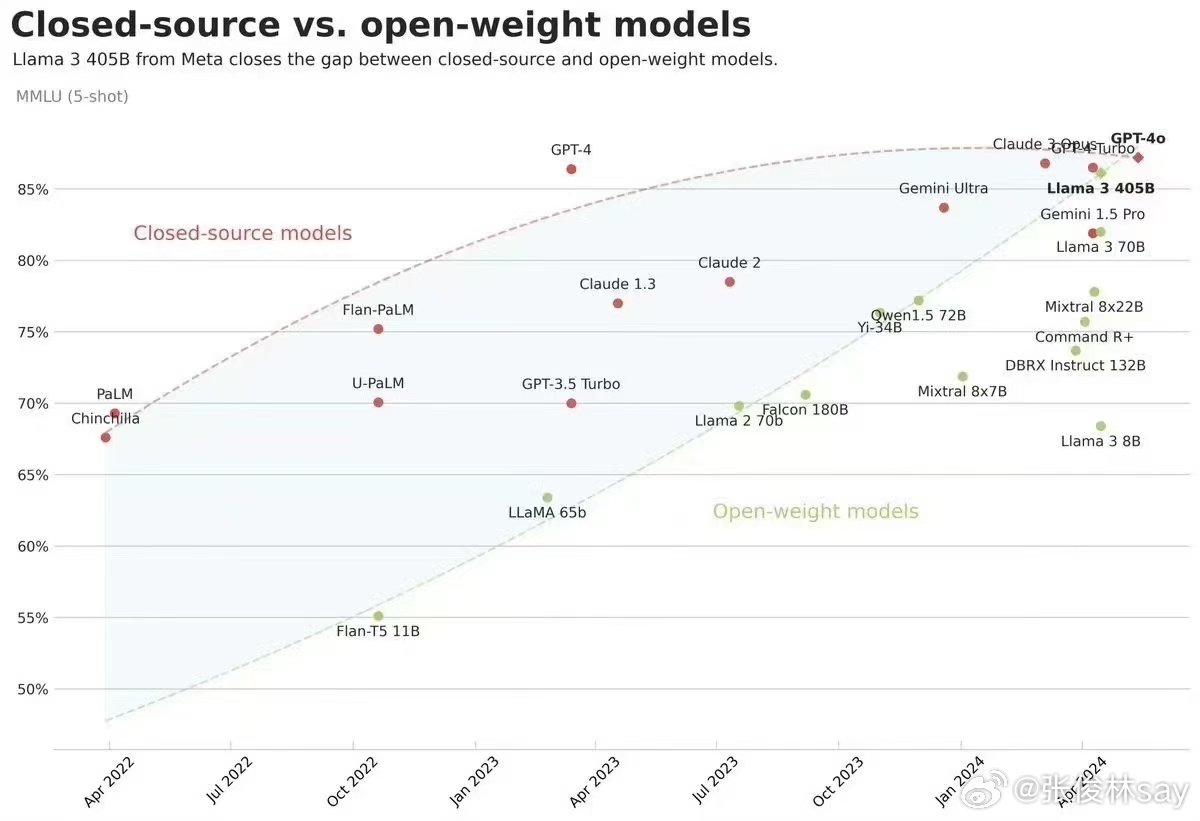
LLaMA 3 405B 的开源,对于其它无论闭源还是开源模型,都有重大影响。对于闭源模型,如果其能力还赶不上 LLaMA 3,就需要向公众解释对用户收费的依据问题(除了覆盖推理成本外的费用)。对于开源模型而言,如果能力不如 LLaMA 3,就需要考虑如何作出差异化和不同特色的问题。目前看 Meta 继续开源比如 LLaMA 4 等后续更强模型的决心是比较大的(毕竟从大模型开源带来的股价上涨就能覆盖成本了,这买卖合算的),随着 LLaMA 4 的进一步开源,形势将逼迫很多原先定位为基础模型 AGI 的创业公司转向特色产品赛道。我觉得这其实是个负面作用,尤其是对开源界,即使是开源赛道也是百家争鸣比一两家独大要好,但是逐渐收敛看样子不可避免。 我觉得之后一方面要重视 LLAMA 和 Gemma 的中文化工作,让中文支持效果更好。如果这方面作出特点,完全可以实现小公司、小投入,但是拥有当前最强中文模型的能力,从能力角度看,并不弱于获得大量资金支持的专业大模型公司,而从投入角度则小的多,性价比很高。 另外一方面,在做小模型的时候,要注重用 LLaMA 405B 这种最强开源模型来蒸馏小模型的思路,这样做对小模型效果提升会非常明显,很明显这也是小投入高产出合算的买卖。
OpenAI 宣布其 AI 搜索引擎产品 SearchGPT 开放内测:目前市面上比较热门的 AI 搜索引擎已经有十几款了,还来卷,而且看官方给出的演示效果,没有特别惊艳的点。
智谱 AI 推出新一代视频生成模型 CogVideoX:模型开放平台 bigmodel.cn 上也部署了,企业和开发者可通过 API 调用方式,同时 C 端用户可以使用「智谱清影」,体验文本生成视频和图像生成视频功能。
模型训练算力是北京亦庄高性能算力集群提供的,数据是 B 站提供的。
DeepSeek API 升级,支持续写、FIM、Function Calling、JSON Output
更新接口 /chat/completions
- JSON Output
- Function Calling
- 对话前缀续写(Beta)
- 8K 最长输出(Beta)
新增接口 /completions
- FIM 补全(Beta)
所有新功能,均可使用 deepseek-chat 和 deepseek-coder 模型调用。
市场
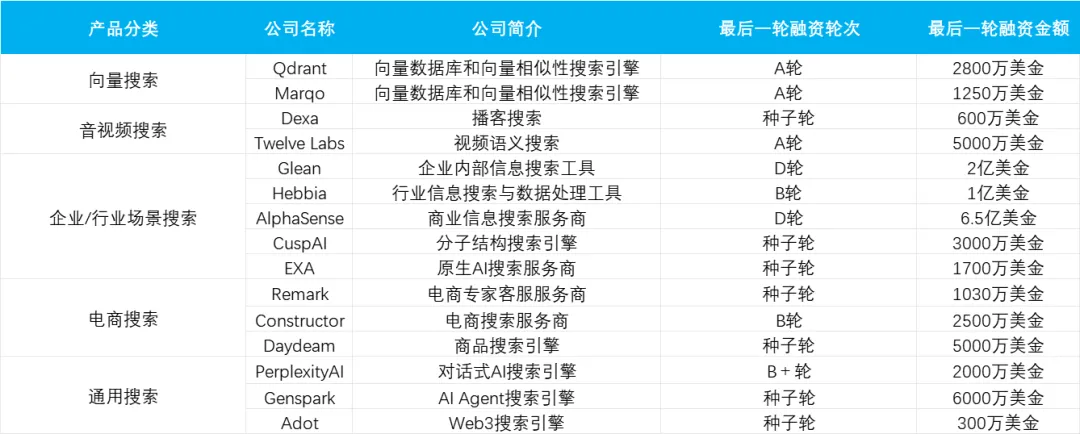
上半年拿到投资的 15 家 AI 搜索公司,他们都在做什么?: 信息检索是能与当前大模型能力匹配的一大应用场景,即使 AI 搜索也存在种种问题,例如 PMF 的验证、尚难以难以撼动传统搜索引擎等等,且依旧被创业者视作「LLM 初期最有可能跑出 Killer APP 的领域」,很被资本看好。本文梳理了向量搜索、音视频搜索、企业/行业场景搜索以及电商搜索和通用搜索领域的 15 家公司及产品情况。(国内公司做 AI 的思路基本上都是将搜索功能整合进「大而全」的 AI 产品中,很难将其定义为单纯的 AI 搜索产品,除了很难界定的产品外,国内并没有找到做 AI 搜索且在上半年获得融资的产品)
《生成式 AI 商业落地白皮书》:火山引擎与 RollingAI 联合 InfoQ 研究中心进行了一项关于企业生成式 AI 应用现状的调研,共回收 590 份有效问卷,涵盖金融、消费零售、汽车、医药大健康等八大行业。调研集中分析了企业 CXO 层对生成式 AI 的六个关键关注点,并结合专家访谈及实践案例,希望为企业提供一份 AI 转型的专业指南,发布了《生成式 AI 商业落地白皮书》。
2024 上半年上海、北京、深圳、苏州、杭州、成都六个城市人工智能赛道融资情况统计:本来以为北京、上海、深圳会在同一梯队,结果数据上来看北京属于断档式存在。
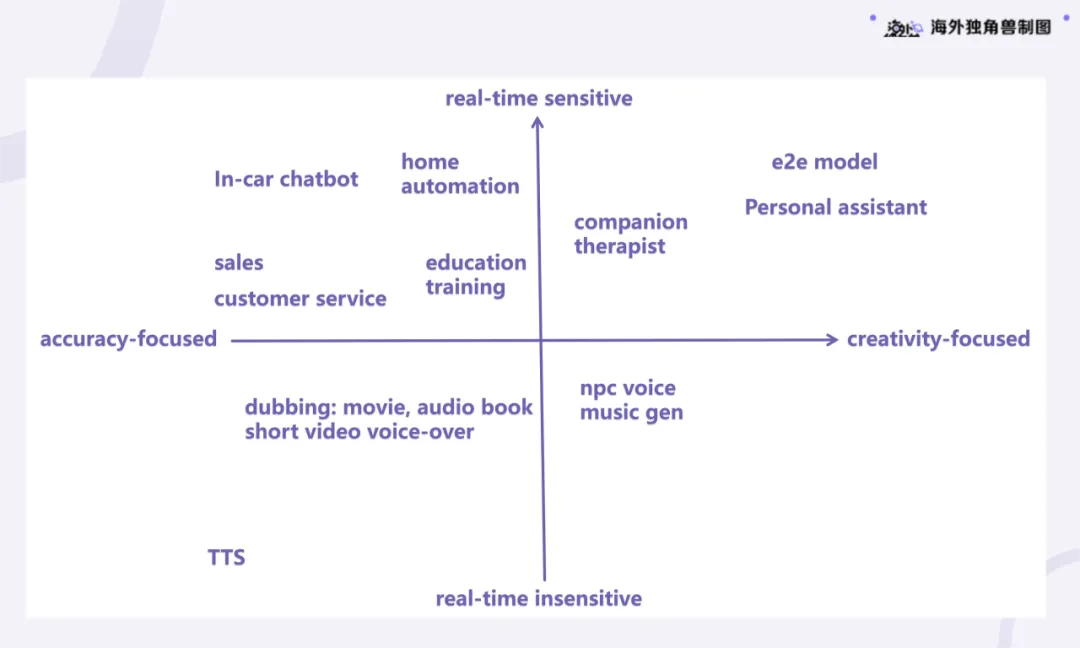
Voice Agent:AI 时代的交互界面,下一代 SaaS 入口:Voice Agent 是一种新型的 AI 人机交互界面,通过语音与人类进行沟通,具有较高的自然性和低能耗的优势。相比于文本交互,语音交互更适合简短即时的信息交流,并能够独立完成交流任务,潜在地替代人类的参与。可关注的机会分为四个象限:第一象限强调实时性和创造性,适合陪伴及心理疗愈场景;第二象限要求实时的高准确度,涉及呼叫中心和教育等领域;第三象限可离线处理,适合有声书和短视频配音;第四象限则强调创意,适合音乐生成等应用。
观点
- AI 提供的是服务不是产品:本文是 a16z 创始人马克·安德森和本·霍洛维茨对谈的第二部分,聚焦于 AI 创业。他们首先探讨了 CEO 的角色和选拔,指出 CEO 应具备领域专业知识而非仅限于管理能力。他们认为,硬件创业虽然面临周期长、风险高等挑战,但成功后能建立更强的竞争优势。文章还深入探讨了 AI 服务模式,指出 AI 公司销售的是服务而非产品,并以特斯拉为例强调了数据驱动的 AI 发展模式。最后,他们展望了 AI 与机器人技术整合的未来,认为这需要克服技术和商业障碍,并依赖大量数据构建数据飞轮。
Vol.15:大语言模型应用如何实现端到端优化?
