Vol.16:构建可靠 LLM 应用的三大原则
⼤家好,Weekly Gradient 第 16 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
- 合规检查助手 AuditNet:在信息过载的时代,各个领域的专业人士面临着应对海量文档和不断变化标准的挑战。确保遵守标准、法规和合同义务是一项关键但复杂的任务,涉及多个专业领域。我们提出了一种多功能的对话式 AI 助手框架,旨在促进各个领域(包括但不限于网络基础设施、法律合同、教育标准、环境法规和政府政策)的合规性检查。通过利用大型语言模型的检索增强生成技术,我们的框架自动化了相关和具有上下文意识的信息的审查、索引和检索,简化了验证遵循既定准则和要求的过程。这个 AI 助手不仅减少了合规检查中手动工作的力度,还提高了准确性和效率,支持专业人士维持高标准的实践并确保在各自领域的合规性。
- REAPER:基于推理的复杂 RAG 系统的检索规划:复杂的对话系统常通过检索证据提供准确答案。RAG 系统从多个异构数据源中检索信息,这些源通常由多个索引或 API 组成,而不是单一数据库。针对特定查询,系统需从众多潜在源中筛选相关证据。有些复杂查询甚至需多步骤检索,例如,零售网站的对话代理在处理过往订单时,需先检索订单信息,再结合产品上下文提取证据。多数 RAG 系统通过交替推理和检索应对此类思维链任务,但每一步推理都会增加延迟,对于大模型而言,延迟可达数秒。虽然多代理系统可将查询指向特定源,但小型分类模型的性能限制了大语言模型的表现。本论文针对性推出了 REAPER——一种基于 LLM 的规划器,用于生成对话系统中的检索计划,显著降低延迟并灵活适应新场景。该方法适用于各种 RAG 系统,论文以亚马逊的对话购物助手 Rufus 为例,展示其应用成效。
- 利用自我推理改进 RAG 系统:RAG 旨在解决大语言模型(LLM)中的事实幻觉问题,但仍面临无关文档检索和缺乏引用的挑战。为此,百度提出了一种新的自我推理框架,通过利用 LLM 自身生成的推理轨迹来提升 RAG 系统生成答案的可靠性和可追溯性。这一创新框架以端到端的方式增强 LLM 的性能,避免依赖外部推理模型,提供了一种更有效的解决方案。该框架分为三个层级:基本 LLM 负责初步回答,标准 RAG 系统结合检索文档进行回答,而百度的自我推理框架则依赖自生成的推理轨迹输出答案。
- ChatQA 2:缩小开源模型在长上下文和 RAG 方面与商业闭源模型之间的差距:本论文推出的 ChatQA 2 模型基于 Llama3,旨在提升开源 LLM 在长上下文理解和检索增强生成(RAG)方面的能力,与私有模型如 GPT-4-Turbo 相媲美。通过将 Llama3-70B-base 的上下文窗口扩展至 128K 令牌并实施三阶段指令调优,我们显著增强了模型处理大量信息的能力。实验表明,Llama3-ChatQA-2-70B 在长上下文理解任务上与 GPT-4-Turbo-2024-0409 相当,并在 RAG 测试中表现更佳。此外,论文还发现先进的长上下文检索技术有效解决了 RAG 中的上下文碎片问题,进一步提升了性能,论文最后还深入比较了 RAG 与长上下文解决方案的优缺点。
工程
《理解 Transformer 所需的数学知识》:简要概述了学习 Transformer 架构所需要的核心数学原理,包括 FLOPS、混合精度计算、量化、总体推理内存、梯度、激活、训练共享优化器的区别和 3D 并行化。
可视化大模型量化原理指南:通过精美的图例演示和教学各种量化技术, 包括 FP16,BF16,INT8,后训练量化如 GGUF 等 4Bit 量化等各种技术细节,量化正在成为在端侧运行/压缩 LLM 最重要的技术。
构建可靠 LLM 应用的 LLM 三大原则:值得一读,AI 应用场景最佳落地实践=工程化能力 + 对应场景的大模型能力 + 业务上下文知识。
LLM-Native apps are 10% sophisticated model, and 90% experimenting data-driven engineering work

构建高效 RAG 的三大关键策略:Zilliz 官方博客文章,介绍了充分利用 RAG 的三个关键策略:
智能文本分块:首先,将文本数据分解为有意义、易于管理的块,以便向量数据库能快速准确地检索相关信息。文本分块类似于将长故事切成小段,方便计算机处理。主要分块技术包括:
a) 递归字符文本分割:基于字符数分成连贯块。
b) 从大到小的文本分割:从较大部分逐步拆分为更小块,以小块搜索,大块检索。
c) 语义文本分割:根据意义划分,使每块代表一个完整想法,保留上下文。迭代不同的嵌入模型:嵌入模型决定数据如何表示为向量,是 AI 的通用语言,提升了向量数据库检索准确信息的能力。固定分块方法为递归字符文本分割器(top_k=2),并尝试两种嵌入模型:
BAAI/bge-large-en-v1.5
Text-embedding-3-small(embedding-dim = 512)
使用 Milvus 文档和评估方法 Ragas,结果显示:BAAI/bge-large-en-v1.5 是最佳模型。
尝试不同的 LLM 或生成模型:
每个 LLM API 的成本、延迟和准确性各异,测试它们可选择最适合的模型。固定分块方法为递归字符文本分割器(top_k=2),嵌入模型为 BAAI/bge-large-en-v1.5,尝试六个不同的 LLM API,结果显示 MistralAI mixtral_8x7b_instruct AnyScale API 表现最佳。
RAG Pipeline 的评估因具体数据和用例而异,优化检索策略带来的改进最为显著。使用 Milvus 文档数据和 Ragas 评估方法观察到:
- 通过改变分块策略实现 35% 的改进
- 通过改变嵌入模型实现 27% 的改进
- 通过改变 LLM 模型实现 6% 的改进
LLM Data Pipelines:解析大语言模型训练数据集处理的复杂流程:在训练大语言模型时,构建高质量的训练数据集至关重要,但关于大模型训练所需数据集的通用数据处理流程的资料极为稀少。本文介绍了基于 Common Crawl 数据集的数据处理流程。首先,概述了 Common Crawl 的三种数据格式:WARC、WAT 和 WET 及其应用场景。接着,详细阐述了数据处理的几个关键步骤,包括数据获取、去重、语言识别、模型筛选以及 LLaMA 新增的“是否为参考来源”筛选等。在各步骤中,本文总结了不同的数据处理方案及其优缺点。高质量的数据最终推动高质量的语言模型的形成,而数据处理流程需投入大量实验和计算资源,每个决策都会影响最终结果,因此需谨慎评估。
如何让训练更快:GPU 算力评估:在深度学习训练中,训练时间的算涉及到多个因素,包括 Epochs 数量、全局批次大小(Global Batch Size)、微批次大小(Micro Batch Size)以及计算设备的数量等。以下是这些参数之间关系的一个基本公式(注意只是一个基本示意公式,主要解释正比反比,实际训练需要考虑的因素可能更多):

· Epochs 是指模型处理整个训练数据集的次数。
· Total Number of Samples 是训练数据集中的样本总数。
· Global Batch Size 是在每次训练迭代中处理的数据样本总数。
· Time per Step 是每次训练迭代所需的时间,这取决于硬件性能、模型复杂性、优化算法等因素。
· Number of Devices 是进行训练的计算设备数量,例如 GPU 数量。
这个公式提供了一个基本的框架,但请注意,实际的训练时间可能会受到许多其他因素的影响,包括 I/O 速度、网络延迟(对于分布式训练)、CPU-GPU 通信速度等。因此,这个公式只能作为一个粗略的估计,实际的训练时间可能会有所不同。
产品
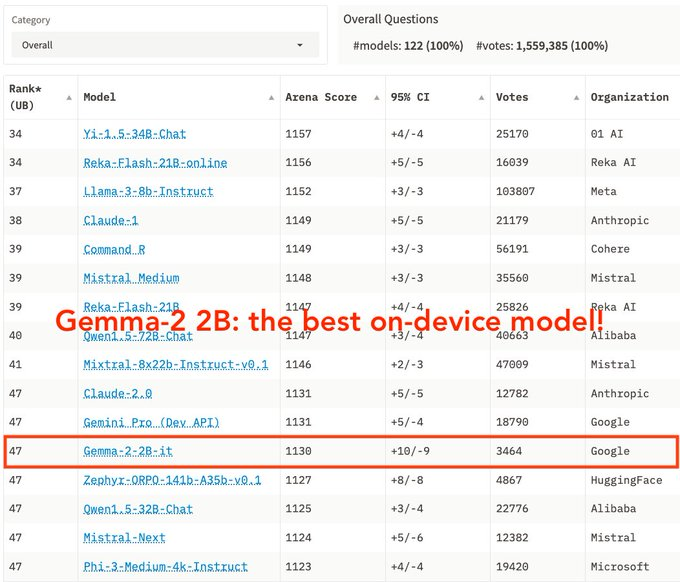
谷歌 DeepMind 正式发布 Gemma2 2B 模型并开源:谷歌在端侧模型继续发力,性能媲美大 10x 模型,超越 GPT-3.5-Turbo 和 Mistral-8x7b,Android Intelligence 快要来了,模型下载地址,LMSYS Chatbot Arena 排行数据。
苹果公司本周推出 Apple Intelligence 的开发者预览版,拥有 iPhone 15 Pro 或 iPhone 15 Pro Max 的用户可以下载 iOS 18.1 开发测试版体验 Apple Intelligence 的功能,同时也在 iPadOS 18.1 和 macOS 15.1 开发者预览版上线,苹果还发布了对应的技术报告,报告详细介绍了两款模型 AFM-on-device(Apple Foundation Model,约 30 亿参数)和更大规模的 AFM-server,后者能够高效、准确且负责任地执行特定任务。
AI 搜索 Perplexity 的产品构建之道:新成立的 AI 搜索公司 Perplexity 正在与 Google 和 OpenAI 竞争,争夺搜索市场的份额。尽管团队人数不到 50 人,Perplexity 已经吸引了数千万用户,并实现了超过 2000 万美元的年度经常性收入。近期,他们获得了 6300 万美元的融资,公司的估值超 10 亿美元,投资者包括英伟达创始人 Jensen Huang 及 OpenAI 创始成员等。在与知名博主 Lenny Rachitsky 的对话中,联合创始人 Johnny Ho 分享了 Perplexity 的高效组织与管理方式,强调团队的灵活性、小规模与扁平化管理,并指出 AI 在公司决策过程中的重要性。公司希望吸引既懂技术又具备产品洞见的优秀产品经理和工程师,认为这将是未来的关键资产。
Hebbia:一个为知识工作者提供解决方案的 AI 驱动企业搜索平台,利用其独特的 Matrix AI 技术,旨在帮助金融、法律等行业的专业人士高效处理大量复杂信息。该技术超越传统搜索,通过多步骤代理智能分析与决策支持,确保数据的安全性和隐私。同时,Hebbia 实现了多模态数据处理,集成了 PDF、图像、电子邮件和幻灯片等格式,并与 Dropbox、Google、Microsoft 等工具无缝对接,从而提升工作效率。自 2020 年成立以来,Hebbia 获得多轮融资,总额达到近 1.36 亿美元,已成为全球多家顶尖机构的付费客户,迅速成长为备受关注的 AI 企业。
市场
- 上半年视频生成产品全盘点:2024 年上半年,AI 视频生成领域经历了激烈的发展,自 Sora 在 2 月开启新纪元以来,多个企业接连推出新产品,标志着视频生成技术的快速进步。目前,国内外已有超过 8 家企业推出可以生成 10 秒以上的视频,有的甚至达到了 2 分钟的长度,反映出这一领域的竞争非常激烈。
- AI 应用还没有赛道:本文介绍了接近 10 家已经拥有大量用户的 AI 公司被曝卖出或寻求并购,让人反思 AI 应用是否可以作为一个专门赛道?
- 2023 年中国 RPA+AI 解决方案市场份额报告:自动化解决方案市场标准化产品软件与服务共同构成了市场营收的两大发展方向,并且这两者之间的相互促进作用愈发明显。标准化 RPA+AI 软件产品因其易于部署、便于维护和更新的特点,吸引了大量亟待提升运营效率的企业用户,特别是中小企业,它们希望通过即插即用的方式迅速实现业务流程的自动化升级。与此同时,针对大型企业及特定行业的复杂需求,专业定制化服务的重要性亦不可忽视。这类服务涉及深度咨询、方案设计、实施培训等一系列环节,旨在帮助企业客户打造最适合自身业务特性的智能自动化解决方案。而标准化产品与服务的占比也在动态变化,随着市场上对 RPA 技术熟悉程度的提升和企业 RPA 的逐步渗透,服务收入的比例预计会逐年下降。
观点
- AI Scaling 被神话了吗:截至目前,语言模型在规模和能力上不断增长,但过去的表现是否能预测未来?一种常见观点是,我们应预期当前趋势将持续下去,并可能达到一个新高度,从而实现 AGI。然而,作者认为这一观点源于若干神话和误解。尽管从表面上看,规模扩展似乎是可预测的,但这对已有研究的理解存在误区。此外,LLM 开发者已接近高质量训练数据的上限,且模型行业正面临尺寸增长的压力。虽然我们无法准确预测 AI 通过扩展能取得多大进展,作者认为仅凭扩展几乎无法实现 AGI。本文作者 Arvind Narayanan 是普林斯顿大学计算机科学教授,Sayash Kapoor 是普林斯顿大学计算机科学博士生。
Vol.16:构建可靠 LLM 应用的三大原则
