Vol.17:如何构建生成式 AI 应用平台?
⼤家好,Weekly Gradient 第 17 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
论文
- 智谱开源清影同源模型 C ogVideoX-2b:本文介绍了智谱开源清影同源模型 CogVideoX-2b 制作文本到视频生成数据集的方法,主要包括视频数据的收集、过滤、字幕生成、数据点收集、字幕数据的微调、高质量视频数据的筛选、光学流和图像美学评分,以及数据增强等步骤。首先,通过视频过滤器和重新字幕模型收集了一系列具有文本描述的高质量视频片段。接着,为了确保视频质量,开发了负标签系统来排除低质量视频,如人工编辑、缺乏运动连续性、以讲座为主等。在视频字幕生成方面,由于缺乏准确的文本描述,文章提出了一个流程,包括使用 Panda70M 模型生成简短字幕、CogVLM 模型为每一帧创建密集图像字幕、以及 GPT-4 整合所有图像字幕为最终视频字幕。在数据收集过程中,每两秒提取一帧进行图像字幕生成,收集了 50000 个数据点用于微调摘要模型。为了加速视频字幕生成,使用 GPT-4 生成的数据对 Llama2 模型进行了微调。此外,从预训练数据中筛选出高质量视频数据进行进一步的微调,以提高视觉质量并去除字幕和水印。最后,通过计算光学流和图像美学得分,动态调整阈值范围以确保视频流畅性和美学质量,并在训练过程中添加噪声以增强模型鲁棒性。
- 大语言模型 (LLM) 是如何解数学题的?:Meta FAIR、CMU 和 MBZUAI 的叶添、徐子诚、李远志、朱泽园团队在 arXiv 上发表了一篇论文,揭示了大语言模型(LLM)解决数学问题的推理过程。该研究在 ICML 2024 会议上引起了热烈反响,研究结果显示 LLM 能够进行超出数据集教授的推理技能的学习。研究人员通过创建 iGSM 数据集,使得 GPT-2 模型能够从零开始学习小学数学问题,并发现 GPT-2 能够学习「1 级推理」技能,即通过拓扑排序找到最短解答路径。这一发现挑战了之前报道的大模型无法学习推理的观点。研究还揭示了模型在推理过程中的「2 级推理」能力,即在解题前对所有变量关系进行因果梳理。此外,研究指出模型的深度对于推理能力更为重要,与之前的「唯大独尊」定律不同。最后,研究强调了当前大模型推理能力的局限性,即使是 GPT-4,也只能进行最多 10 步的推理,暗示了预训练数据集存在改进空间。
- 基于 LLM 构建一种高质量的模拟同声传译系统:ByteDance Research 团队提出了 Cross Language Agent - Simultaneous Interpretation(CLASI),一种高质量的模拟同声传译系统,该系统受到专业人类翻译的启发,采用了一种新型的读写策略来平衡翻译质量与延迟。为了解决专业领域术语翻译的挑战,CLASI 引入了一个多模态检索模块,该模块能够从外部知识中获取相关信息,以增强翻译内容。支持由大型语言模型(LLMs)的系统,CLASI 能够通过考虑输入音频、历史上下文和检索到的信息来生成容错翻译。实验结果显示,与其他系统相比,CLASI 在验信信息比例(VIP)这一更可靠的评估指标上超越了其他系统,特别是在中英文互译方向上,CLASI 分别达到了 81.3% 和 78.0% 的 VIP,而其他商业或开源系统仅达到了 35.4% 和 41.6%。在极端困难的数据集上,CLASI 仍然能够实现 70% 的 VIP,而其他系统的 VIP 低于 13%。论文还展示了 CLASI 的性能评估图表,以及系统的框架和架构。此外,通过比较演示,进一步说明了 CLASI 与其他系统相比的优势。
- 基于 RAG 的少样本学习增强语言模型中的代码翻译:这篇 论文由洛斯阿拉莫斯国家实验室提出了 RAG 框架,旨在通过少样本学习提升代码翻译任务的性能。RAG 框架通过维护一个丰富的代码翻译示例库,并能够根据输入的代码片段动态抓取最贴切的实例,结合大型语言模型(LLM)和检索机制,实现高质量的代码翻译生成。论文在 Fortran 和 CPP 的翻译任务中进行了实验,证明了 RAG 方法的有效性。实验结果显示,不同的模型和嵌入策略在性能上有显著差异,如 GPT-4 Turbo 和 GPT-3.5 Turbo 在零样本情境下表现出色,而 Granite-34B、Llama3-70B Instruct 和 Mixtral-8x22B 在少样本学习中展现了显著的性能提升。此外,研究还探讨了不同数量的示例和嵌入模型对方法鲁棒性和有效性的影响
工程
大模型幻觉比较:LLM Hallucination Index RAG Special 版本是一个评估大语言模型(LLM)的框架,旨在帮助开发者了解和选择最适合他们需求的模型。该报告针对 22 款顶尖 LLM 进行了广泛的测试,这些模型包括闭源和开源模型,如 Anthropic 的 Claude 系列、Meta 的 Llama 系列、Alibaba 的 Qwen 系列等。测试分为三个不同的文本长度场景:短上下文(<5k tokens)、中上下文(5k 到 25k tokens)和长上下文(40k 到 100k tokens),以评估模型在不同上下文长度下的表现。
报告发现,开源模型在性能上逐渐接近闭源模型,尤其是 Gemini、Llama 和 Qwen 等模型在控制成本的同时提高了性能。此外,一些模型在扩展的上下文长度下表现出色,而且模型的规模不一定与性能正相关,较小的模型有时也能出现更优的性能。Anthropic 的 Claude 3.5 Sonnet 和 Claude 3 Opus 在测试中得分接近完美,特别是在短上下文场景下。
最佳模型、成本效益最高的模型以及最佳开源模型分别为 Claude 3.5 Sonnet、Gemini 1.5 Flash 和 Qwen2-72b-Instruct。这些模型在各自的类别中表现出色,并且在不同的文本长度下都有出色的性能。报告还提供了模型在不同 RAG 任务上的具体表现和案例分析,以及它们在不同数据集上的性能。大模型微调到底有没有技术含量,或者说技术含量到底有多大?:大模型微调的技术含量取决于执行工作的方式,特别是在 LLM(Large Language Model)领域,入门门槛相较于传统自然语言处理(NLP)已经降低。接着,作者通过举例说明了大模型微调的几个关键环节,包括数据工作、训练代码编写和实验分析,并提出了不同的执行方法。
在数据工作方面,从简单地继承现有数据到精心设计和检查数据质量,再到利用用户交互日志和借鉴先进的思路来构造数据,每种方法都能完成最终目标,但对个人技术成长的帮助差异很大。
在训练代码编写方面,从直接运行现有代码到深入理解和改进代码,以及提出自己的见解和创新,这一过程不仅考验对代码的掌握,也考验对训练过程的理解和优化能力。
在实验分析方面,从基本的评估集运行到深入分析模型的 bad case,设计实验验证假设,以及关注模型效果与数据质量、训练方法之间的关系,这一过程揭示了模型优化和问题解决的复杂性。
LLM 生态介绍:从模型微调到应用落地:主要介绍了大语言模型(LLMs)生态系统,包括模型微调、量化、部署以及 Agent 和 RAG 框架的应用。文章首先阐述了从训练到实际应用落地的整个生态系统,强调了模型微调的重要性,并分别介绍了几款流行的微调工具,如 Axolotl、Llama-Factory 和 Firefly,它们支持多种模型和微调方法,提供了高效的训练和评估工具。接着,文章探讨了模型量化技术,如 AutoGPTQ、AutoAWQ 和 Neural Compressor,这些技术能够压缩模型大小,提高运行效率。在模型部署方面,介绍了 vLLM、SGL、SkyPilot、TensorRT-LLM 和 OpenVino 等工具,它们支持多云平台和硬件加速器,可以自动选择最优的部署方案,并提供成本优化功能。此外,文章还提到了在个人设备上运行 LLM 的可能性,例如使用 MLX、Llama.cpp 和 Ollama 等工具。最后,文章介绍了 Agent 及 RAG 框架,如 LlamaIndex 和 CrewAI,它们能够将 LLM 与外部数据和工具结合,构建更强大的应用,以及模型评测工具,如 LMSys 和 OpenCompass,帮助开发者选择合适的 LLM 并评估其性能。
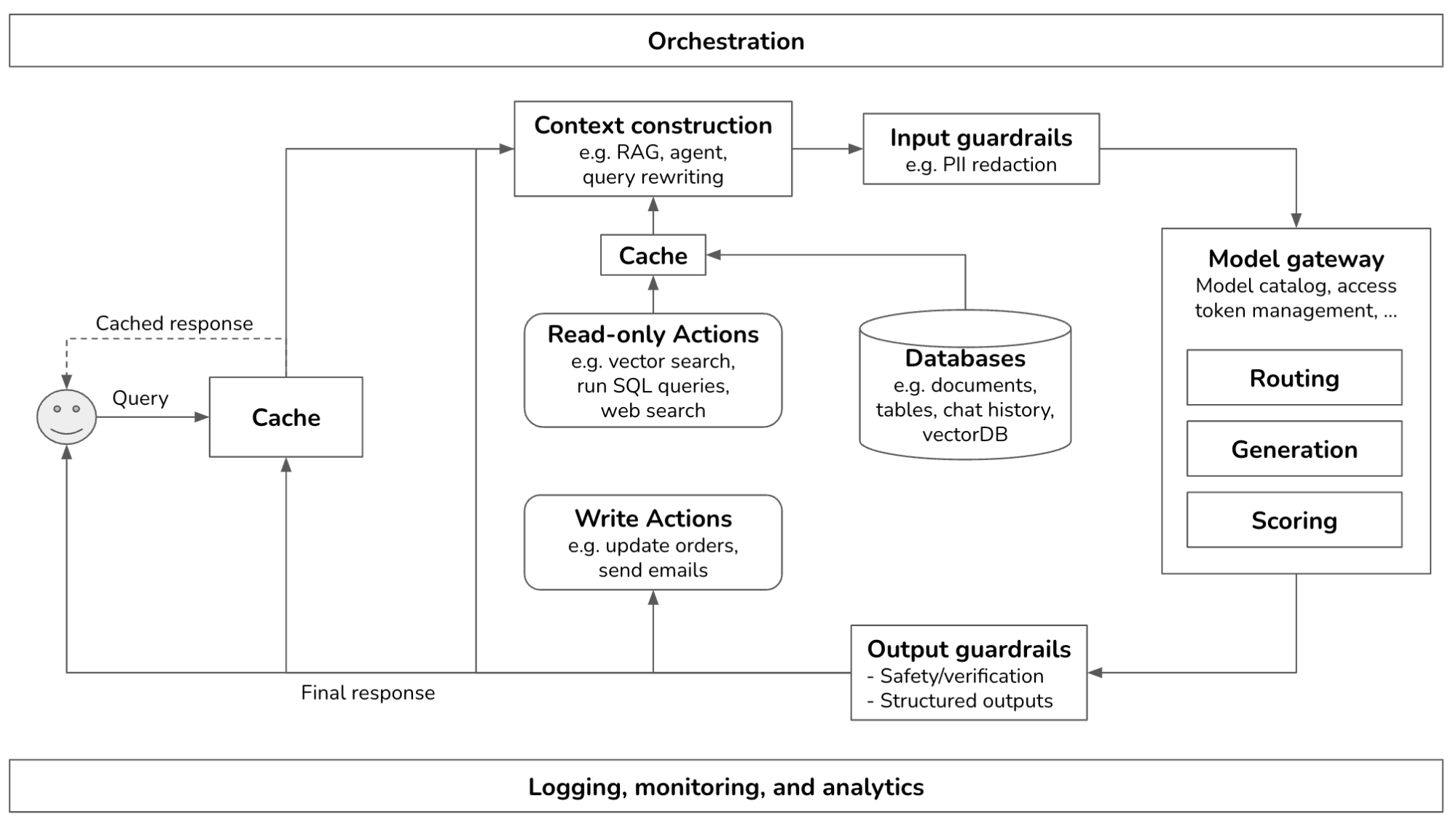
如何构建生成式 AI 应用平台:本文详细阐述了构建生成式人工智能平台的整体架构及其各个组件。首先,介绍了从最简单的架构逐步添加组件的过程,包括增强上下文输入、放置安全措施、添加模型路由和网关、优化延迟和成本、增加复杂逻辑和编写动作等。其中,上下文增强涉及让系统通过外部数据源和信息检索工具来获取相关信息,以提高模型的回答质量。安全措施分为输入和输出两类,输入措施保护用户和开发者免受潜在风险,如私密信息泄露和模型越狱,而输出措施则关注生成响应的质量和处理失败模式。模型路由和网关支持复杂的管道和提供额外的安全性。延迟优化主要通过缓存机制实现,包括提示缓存、确切缓存和语义缓存。复杂逻辑和编写动作使得系统能够执行更多任务,包括编写邮件或下单等。此外,文章还强调了可观测性的重要性,包括日志、追踪和指标等监控手段,以及如何通过 AI 管道编排来组织和连接各个组件,形成完整的应用流程。
产品
OpenAI 推出了结构化输出功能:OpenAI 宣布在其 API 中引入了结构化输出功能,这意味着开发者可以通过提供 JSON Schema 来强制模型生成的输出严格遵循预定义的结构。这一功能分为两种形式:函数调用和响应格式参数。通过函数调用,开发者可以在工具定义中设置 strict: true 来确保模型输出与工具定义相匹配。而通过响应格式参数,开发者可以提供 JSON Schema 来确保模型响应符合特定的结构。新的 gpt-4o-2024-08-06 模型在 OpenAI 的评估中得分为 100%,显著优于 gpt-4-0613 模型。此外,OpenAI 的 Python 和 Node SDK 已经更新,支持通过 Pydantic 或 Zod 对象直接提供 Schema,并自动处理数据类型转换和错误处理。结构化输出功能还能够用于生成用户界面、分离最终答案与推理过程、从非结构化数据中提取结构化数据等多种用例。OpenAI 通过基于上下文无关文法(CFG)的约束解码方法来实现这一功能,并对 JSON Schema 的使用进行了限制(不能超过 5 层嵌套,输出有延迟。。。),以确保性能。
Lepton AI 推出了 Voice Mode 技术:通过整合 LLM 和 TTS 能力,显著减少了 Time to First Audio (TTFA),提供了更自然、流畅的语音用户体验。与传统的文本聊天机器人相比,Voice Mode 提供了更丰富的交互方式,通过语音能力增强了用户体验。在医疗、娱乐和旅行导航等多个行业中,语音助手已经开始提供更加个性化和沉浸式的服务。然而,传统的语音 AI 系统在性能和工程复杂性方面面临着挑战,如实时交互的期望未得到满足、错误处理的复杂性以及对于长响应的分块和缓冲问题。Lepton AI 的 Voice Mode 通过将 LLM 和 TTS 服务整合为一个统一的服务,解决了这些问题,大幅缩短了 TTFA,提高了内容处理的效率和质量。此外,该技术与任何开源 LLM 模型兼容,为开发者提供了极大的灵活性和定制化选项。Lepton AI 鼓励开发者尝试其最新的演示,并探索与开源社区合作,共同构建更多创新的应用。
Stability AI 前研究员 Robin Rombach(Stable Diffusion 作者之一 ) 创立的 AI 公司,旗下 Black Forest Labs 推出了首个模型系列「FLUX.1」,包含了以下三个变体模型:
- **FLUX.1 [pro]**,具有极其丰富的图像细节、极强的 prompt 遵循能力和多样化风格,目前可以通过 API 使用(API 地址:https://docs.bfl.ml/)。
- **FLUX.1 [dev]**,它是 FLUX.1 [pro] 的开放权重、非商用变体,并直接基于后者蒸馏而成。该模型的表现优于 Midjourney 和 Stable Diffusion 3 等其他图像模型。推理代码和权重已经放在了 GitHub 上(GitHub 地址:https://github.com/black-forest-labs/flux)。
- **FLUX.1 [schnell]**,超高效的 4-step 模型,遵循了 Apache 2.0 协议,可以在 Hugging Face 上使用。(Hugging Face 地址:https://huggingface.co/black-forest-labs/FLUX.1-schnell)
FLUX.1 的语言理解和文本控制能力很牛,可以在画面中嵌入短的英文字符,基本告别「鬼画符」,极其丰富的图像细节、极强的 prompt 遵循能力和多样化风格,对复杂提示词的理解相当到位。
面壁智能开源端侧多模态模型 MiniCPM-V 2.6:MiniCPM-V 2.6 是目前 MiniCPM-V 系列中性能最佳的模型,它基于 SigLip-400M 和 Qwen2-7B 构建,拥有 80 亿参数。与前一版本 MiniCPM-Llama3-V 2.5 相比,2.6 版本在性能上有显著提升,并新增了多图和视频理解的功能。在 OpenCompass 榜单上,MiniCPM-V 2.6 平均得分为 65.2,在单图理解方面超越了多个主流商用闭源多模态大模型。此外,MiniCPM-V 2.6 支持多图对话和推理,在多图评测基准上表现出色,展现出优秀的上下文学习能力。在视频理解方面,该模型能够接受视频输入进行对话和提供详细描述,在视频评测场景下的表现优于 GPT-4V、Claude 3.5 Sonnet 和 LLaVA-NeXT-Video-34B 等商用闭源模型。MiniCPM-V 2.6 还具备处理高分辨率图像的能力,在 OCR 方面的性能超越了 GPT-4o、GPT-4V 和 Gemini 1.5 Pro 等模型,并且具备较低的幻觉率。此外,MiniCPM-V 2.6 的视觉 token 密度领先,能够以更少的 token 处理更高像素的图像,优化了推理速度和资源占用。该模型支持多种使用方式,包括本地 CPU 推理、量化模型、高吞吐量和内存高效的推理、微调以及快速设置本地 WebUI 演示等。
阿里开源 Qwen2-Math:该系列包括 1.5B、7B 和 72B 三种规模的模型,它们基于 Qwen2 LLM 进行初始化,并在精心设计的数学专用语料库上进行了预训练。这些语料库包括大规模高质量的数学网络文本、书籍、代码、考试题目以及由 Qwen2 模型合成的数学预训练数据。Qwen2-Math 系列在三个广泛使用的英语数学基准上进行了评估,包括 GSM8K、Math 和 MMLU-STEM,以及三个中国数学基准,即 CMATH、GaoKao Math Cloze 和 GaoKao Math QA。所有评估都采用了 Few-shot CoT 方式。此外,还对 Qwen2-Math 指令微调模型进行了介绍,该模型在英语和中文的数学基准评测上进行了评估,包括更具挑战性的考试和基准。网页还展示了一些具体的案例分析,包括解决 IMO 竞赛题的能力。最后,网页强调了在预训练和微调数据集上进行的去污染处理工作,以及未来的发展计划,包括推出支持英文和中文的双语模型,并且正在开发多语言模型。
市场
The Rise of AI Agent Infrastructure:美国风投 Madrona 的合伙人 John Turow 发表了行业洞察《The Rise of AI Agent Infrastructure》,分享了他对 agent 领域的观察。他指出尽管当前 agent 存在明显局限,但这并未阻止其激增的趋势,反而推动了新的基础设施的发展,通过梳理 agent 领域的项目,探讨 agent 基础设施的发展现状。整体来说,目前 AI Agent 技术栈分为平台、记忆、规划与编排、执行和应用 5 个板块。

中国大模型公司们的 200 亿估值“陷阱”:文章介绍了中国大模型公司的融资情况,月之暗面完成了新一轮 3 亿多美元融资,估值达到 33 亿美元;百川智能完成了 50 亿人民币 A2 轮融资,估值 200 亿人民币;智谱 AI 完成了 4 亿美元 B +轮融资,估值约 210 亿人民币。这些公司在两个月内加入了 “200 亿俱乐部”,仅 MiniMax 尚未达到这一估值。文章指出,200 亿元估值在过去的互联网时代是一个很高的数值,但现在可能只是一个数字,不一定代表实际商业价值。投资人分析称,大模型公司的估值可能是基于同行业比较的结果,而非技术、产品或商业模式的评估。随着估值的提升,创业公司面临着商业化的考验,需要展示可行的商业模式并实现盈利。文章举例说明,C.AI 虽然拥有庞大用户规模,但缺乏可见的商业模式,最终被谷歌以降低估值收购。国内大模型公司在面向 C 端用户的产品几乎全部免费,而在 to B 领域,创业公司的优势较弱。创业公司在商业化和管理问题上面临着挑战,需要在投资人的推动下探索新的商业模式。融资方面,创业公司可能会接受地方产业基金或国外大财团风投基金的投资,这可能导致产业向中心化靠拢,形成新的格局。文章最后指出,中国大模型的角逐才真正开始,创业公司的长期发展将考验其创新能力、内部管理和战略定力。
25 个智谱 AI 孵化的 AI 项目:智谱 Z 计划自发布以来,举办的首届大规模路演活动。现场路演项目覆盖大模型赛道各关键生态位,涉及算力优化、数据治理等基础设施,以及法律、金融、生物医药等多个垂直行业应用场景。
几个不错的项目 mark 下
《林间聊愈室》 (MoodTalker)是一款面向年轻用户,打造懂你+关心你的 AI 心灵伙伴的 APP
中财数碳基于内容增强型知识插槽技术的大模型应用服务商,主要落地场景包括双碳、财金等领域,已经落地多个应用场景,产品具有明显的价格优势。
艾语智能个人无抵押信贷资产处置领域是一个超级市场,每年的佣金规模超过 2000 亿!这个行业有超过 180 万的从业人员,他们长期在压抑的环境中工作。在处置过程中,他们需要与大量的借款人以及法院进行对话,同时还需要处理海量的文档生成和识别需求,从技术角度说是特别适合 LLM 的场景。因此,我们构建了 AI 个贷纾困机器人,旨在彻底取代人工,实现高质量的无抵押资产处置流程。
观点
- 吴恩达专访:构建 AI 应用的成本和复杂度的显著降低,大量新应用正在蓬勃发展:在吴恩达的专访中,他提到了生成式 AI 技术如何革新 AI 应用的开发过程。通过这一技术,开发周期从原本的六个月大幅缩短到可能的一周甚至几天。这种变革意味着之前需要半年时间才能完成的项目,现在可以有数百万甚至数十万人在一周内完成。这一显著的成本和复杂度降低,不仅提高了开发效率,也促使了大量新的 AI 应用的蓬勃发展。这些应用之前因为技术和成本的限制是不可能实现的,现在却可以逐渐成为现实。
Vol.17:如何构建生成式 AI 应用平台?
