Vol.18:大模型是泡沫吗?
⼤家好,Weekly Gradient 第 18 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
上周四去参加了开源中国和浦东软件园组织的一场技术会议,分享了下LangChain的话题,除了我,其他嘉宾大多是带着推广自家产品或框架的任务而来,虽然场面热闹,但真正的干货并不多。不过,我还是在私下里与一些嘉宾进行了深入的交流,分享一些观点:
- 大模型的三大支柱:算力、算法、数据。在实际应用中,数据部分往往是拉开差距的关键。特别是在企业知识库产品领域,数据预处理成为了一个难题,面对企业中大量不同格式的非结构化数据,能够支持更多场景和解析更多版面格式的产品,PK时能够获得更多关注。必然数据项素虽然框架开源,但其高识别率的自研文档解析算法是收费的;枫清科技主要服务于金融领域,算法工程师吐槽最头疼的就是提高版面解析准确率;还有一家专注于在微软SK框架基础上进行二次开发,为制造业提供定制化平台的公司。数据解析这一块确实还有市场,并且适合以SaaS的形式交付,尤其是在处理复杂数学公式、化学公式、工程设计图等场景时。国内如TextIn(与扫描全能王、名片全能王同属一家公司)最近增长势头就很猛,国外的mathpix,OpenAI、Google等都是它的客户。
- 落地实施需考虑企业的数字化基础。如果企业的数字化基础薄弱,那么实施过程中需要做的“脏活累活”就会很多(为了推广自家扫地机器人,还得为客户把清水房地面改造成地板),这会导致投入产出比过低,如果💰不够有吸引力,客户再大还是选择观望。大多数有一定规模的客户都会选择定制化服务,而各家的策略也颇为一致:聚焦1~2个行业,80%作为标准化组件,20%根据客户需求进行定制开发,以提高实施效率,抢占客户。上述我提到的几家虽然都有行业标杆客户,营收过千万,但仍然处于亏损状态;国有企业整体上对大模型的应用持开放态度,他们会主动接触并邀请厂商进行评估落地可能。
- 推理加速。主要基于英伟达生态的推理软件(如TensorRT、vllm等),各家大模型厂商也都在通过自研+开源的策略来构建自己的算力适配和推理优化能力,在AI应用大幅增长的情况下,为产品推理加速和优化的市场需求正在猛增,硅基流动是专注于推理加速的公司,提供云+加速推理引擎私有化部署的两种服务形式。
- 推理硬件选择。推理用A800,A100,H100,4090,3090的都有,许多企业在选择推理硬件时,首先考虑的不是性价比,而是手头上有哪些卡。例如,某二线云服务商手头有一批4070卡,就会优先推荐给客户;某二线大模型厂商手头有大量3090卡,就会优先研究如何利用这些卡。华为芯片目前还没被深入研究,大家基本不愿自己吃第一口螃蟹,在等到市场认可度提高后,再考虑是否采用。
- 端侧AI大模型的落地。端侧模型支持度和生成效果都一般,用户最终还是需要访问云端的GPT-4、智谱清言、KIMI等,来满足一些复杂的任务需求。终端厂商开发端侧大模型更多是出于品牌考量,展示其大模型技术的自研能力。而像银行、电信等希望将数据这一核心优势掌握在自己手中,打造行业大模型,而不是完全依赖大模型厂商。面壁智能依靠小模型来打市场,其未来的市场空间还有待观察,被某硬件厂商收购可能是一个潜在的可能性。端云协同是目前端侧大模型落地的主流形式。
- 软件供应链安全:AI生成代码也纳入软件供应链安全,避免在商业化产品混入开源代码,还有代码水印。
论文
- BioRAG :一个用于生物学问题的推理 RAG 框架:论文介绍了 RAG-LLM 的基本概念,即结合了大语言模型和检索系统的框架,以提高信息检索和生成的准确性。随后详细剖析了 BioRAG 框架的构建和应用,包括其在生物学领域的具体应用案例。BioRAG 通过对大型生物医学文献库的检索,结合生成模型,能够对复杂的生物学问题进行准确的推理和回答。文章强调了模型微调在特定领域的重要性,指出通过微调,模型能够更好地适应特定领域的数据和术语,从而提升模型在该领域的性能。最后,文章通过实际案例展示了 BioRAG 在生物学问题理解和解答方面的实际效果,证明了微调大语言模型在特定领域应用的有效性。
- TransferTOD:利用LLM解决任务型对话系统在域外场景槽位难以泛化的问题:任务型对话系统旨在高效处理任务导向的对话,如何利用任务型对话系统准确、高效、合理地完成信息采集的工作一直是一项关键且具有挑战性的任务。目前的槽位填充数据集大多服务于用户主导型系统,往往会局限于预设好的特定场景和特定槽位。而在“客服-用户”信息收集这一系统主导型的对话场景中,需要填充的槽位与槽位值往往是陌生的,填槽的准确率会严重下降,系统也无法根据槽位填充的情况提出准确的问题引导用户回答,完成下一个填槽行为。最近的研究表明,大语言模型在对话、指令生成和推理方面表现出色,能够通过微调极大地提高任务型对话系统的性能。与此同时,大模型优秀的泛化能力也能够承担起系统主导型的对话系统针对空槽位提问的能力,以及对于未训练槽位值的准确填充能力。因此,我们可以利用LLM的相关技术,克服这一在小模型时代难以解决的问题。在本项工作中,我们提出了一个详细的多领域任务导向型中文对话数据构建流程,并基于此流程构建了中文数据集TransferTOD。该数据集真实地模拟了30个热门生活服务场景下共5760轮次的任务型人机对话。基于此数据集,我们采用全参数微调的方法训练出了TransferTOD-7B。实验结果表明,TransferTOD-7B具有出色的填槽能力和提问能力,并在下游场景中展现出良好的泛化能力,可广泛应用于信息收集场景。
- RAGCHECKER:用于诊断RAG的细粒度框架:RAGChecker 是由亚马逊 AWS AI 开源的一个评估框架,专为 RAG(Retrieval-Augmented Generation)系统设计,以解决现有评估指标的不足和对长文本响应评估的挑战。该框架通过从响应和真实答案中提取声明并与其他文本对照,实现了细粒度的评估。RAGChecker 提供了整体指标、诊断指标(包括检索器和生成器指标)、以及基于声明级别的细粒度评估,并附带了一个包含 4000 个问题、覆盖 10 个领域的基准数据集。此外,还提供了一个人工标注偏好数据集,用于评估 RAGChecker 结果与人类判断的相关性。通过在 10 个领域的公共数据集上对 8 个最先进的 RAG 系统进行测试,RAGChecker 展现了与人类评估者更强的相关性,并为 RAG 系统的组件行为和设计提供了深入的见解。RAGChecker 还提供了关于如何通过调整系统设置(如检索器数量、块大小、块重叠比例和生成提示)来改进 RAG 系统的建议。最后,文章还探讨了 Top-k 选择和片段大小对 RAG 系统性能的影响,并建议在特定情况下适度增加这两个参数以实现更忠实的生成。
- NL2Plan:通过最少的文本描述进行稳健的LLM驱动的规划:NL2Plan 系统旨在通过解析最小的自然语言描述,实现高效的任务规划。该系统利用了大语言模型(LLM)的强大能力,能够理解复杂的任务描述,并将其转化为可执行的计划步骤。NL2Plan 在处理不完整或模糊的信息时展现出了较高的鲁棒性,这使得它在实际应用中具有潜在的价值。系统的设计考虑了实际操作的复杂性,如任务的可能性、成本和执行顺序,从而确保生成的计划既高效又实用。此外,NL2Plan 还通过与现有的规划和执行系统集成,展现了其在实际任务中的应用潜力。
- GraphRAG 综述:论文阐述了 GraphRAG 技术的基本概念、方法论、应用场景以及未来的发展方向。GraphRAG 由三个主要阶段组成:基于图的索引、图引导检索和图增强生成。首先,通过基于图的索引构建图数据库并建立索引,以便快速检索。接下来,图引导检索阶段根据用户查询从图数据库中提取相关信息。最后,图增强生成阶段将检索到的图数据与查询结合,通过生成器生成最终响应。GraphRAG 在多种下游任务中得到了应用,包括问答任务、信息抽取、事实核查、链接预测、对话系统和推荐系统等,并在电子商务、生物医学、学术、文学和法律等领域有广泛的应用。此外,文章还讨论了 GraphRAG 系统的训练策略、评估基准和指标,以及工业中的实际应用案例。最后,文章对 GraphRAG 的未来展望提出了一系列挑战和研究方向,包括动态图的构建、多模态信息的整合、大规模知识图谱的高效检索机制、与图基础模型的结合以及上下文信息的无损压缩等。
- Prompt Cache:模块化注意力复用技术用于低延迟推理:这篇论文介绍了MoonShoot和DeepSeek团队最近推出的 Cache能力背后原理,讲的很细,使用Prompt Cache方法,可以通过在不同的大型语言模型提示之间重复使用注意力状态来加快推理速度。这种方法通过预先计算和存储输入提示中经常出现的文本段的注意力状态,以在用户提示中高效地重用它们。在多个大型语言模型上的评估显示,Prompt Cache显著减少了从第一个标记到输出的延迟,尤其对于基于文档的问答和推荐等较长的提示。改进范围从基于GPU的推理中的8倍到基于CPU的推理中的60倍,同时保持输出准确性,无需修改模型参数。
工程
如何准确且可解释地评估大模型量化效果?:本文详细介绍了大模型量化过程中的评估方法和实践案例。作者 Fireworks Team 强调量化没有一致的标准,需要根据具体使用场景定制量化方案。文章首先介绍了大模型在机器学习领域的重要性及其在实际应用中的挑战,特别是在模型部署时的内存和计算资源限制。作为一种模型压缩技术,量化能够减少模型的大小和加速推理,但这通常会牺牲一定的准确性。因此,如何评估量化后的模型效果成为了一个关键问题。接下来,文章详细阐述了量化的两种主要策略:一种是传统的均匀量化,另一种是新兴的非均匀量化。均匀量化通过将连续值映射到等距的离散值来减少位宽,而非均匀量化则采用了更为复杂的映射方法,如对数或线性 + 对数混合映射。文章指出,评估量化效果不仅要考虑模型的准确率,还应该包括模型的鲁棒性、泛化能力以及计算效率。此外,作者提出了一种可解释的评估框架,该框架能够揭示量化对模型内部表示的影响,并帮助理解量化后的性能变化。最后,文章强调了量化效果评估的重要性,并对未来的研究方向进行了展望,包括更高效的量化方法和更精确的评估指标的开发。
大模型与小模型:知乎@ybq一篇关于大模型和小模型讨论的文章,在同源小模型的研究中,通过使用相同的 tokenizer 和预训练数据,可以得到一系列小型的语言模型(llm),这些小模型在研究上的价值超过了单一的大模型。文章强调,小模型的性能表现可以用来预测大模型的效果,这一点在 pretrain 和 post_pretrain 阶段的实验设计中尤为重要。小模型能够快速地进行实验,帮助研究者在短时间内确定最佳的数据配比、学习顺序和数据质量等。在 alignment 阶段,小模型和 scaling law 的指导意义同样显著,尤其是在需要大量数据强化模型某个能力时。此外,大模型也能够通过蒸馏技术帮助小模型提升效能,同源大模型还可以作为小模型的 reward_model,提供更加公正的评估标准。
目前的大部分论文都把“利用 GPT4 造数据,喂给小模型去训练“叫做蒸馏,这种叫法也没错,不过更准确的叫法应该是”知识蒸馏“:让小模型去学习大模型的知识能力。而传统的“模型蒸馏”,指的是我们不再让模型学习 hard-label,而是 soft-label:
- hard_label:“台湾属于”,在预测下一个 token 的时候,“中国”的概率是 1,其他所有 token 的概率是 0;
- soft_label:“台湾属于”,在预测下一个 token 的时候,“中国”的概率是 0.3,“中华”的概率是 0.2,“大陆”的概率是 0.1……
不管从哪个角度考虑,似乎 soft_label 都是蕴含更多信息量可学习的。因此,利用大模型去“模型蒸馏”小模型,很有可能能得到一个能力远高于同等 size 的小模型,Google 的 Gemma 小模型 就应用了这项技术方案。
这么看,只做端侧小模型的厂商,模型能力天花板基本由开源大模型的能力上限决定。
10倍加速LLM计算效率:消失的矩阵乘法:矩阵乘法(MatMul)是深度学习中的主要计算瓶颈,尤其在ChatGPT等Transformer模型中,矩阵乘法的运行时长约占其总运行时长的45-60%,解决这一挑战对发展更经济的大模型具有重要意义。为此,加州大学的研究人员在论文《Scalable MatMul-free Language Modeling(可扩展的无矩阵乘法语言模型构建)》 中试图通过消除矩阵乘法来构建更便宜、耗能更少的语言模型,这将有助于解决当今大语言模型所面临的环境负担高和经济效益低的问题,基于该论文,本文作者Devansh在多个维度对无矩阵乘法语言模型的影响进行了深入分析。
如何让大模型输出 10k+字长文?:来自GLM技术团队,尽管长文本模型在预训练阶段接触了更长的文本序列,但其最大生成长度实际上被 Supervised Fine-Tuning(SFT)数据集中输出长度的上限所限制。通过对 GLM-4-9B-base 模型进行不同最大输出长度的 SFT 微调,研究人员发现随着要求长度的增加,微调出来的模型存在最大输出长度限制。这解释了当前模型普遍存在的 2000 字输出限制,因为现有的 SFT 数据集很少包含超过此长度的样例。此外,许多数据集是用现有的大语言模型(LLM)自动构建的,因此它们也继承了源模型的输出长度限制。为了解决这个问题,作者提供了一系列策略和技巧。首先,可以通过调整模型的一些超参数,如
max_tokens、temperature和top_p,来控制输出的长度和多样性。其次,可以采用分段生成的方法,即将长文本分成多个段落,逐段生成,每次生成时考虑前文信息。此外,还可以利用提示工程(prompt engineering)技巧,精心设计输入提示,引导模型生成连贯、有逻辑的长篇内容。文章还强调了在生成过程中进行质量控制的重要性,包括避免重复和保持话题一致性。最后,作者提到了在实际应用中可能需要的后处理步骤,如编辑和校对,以确保最终输出的质量。MiniCPM-V 2.6 面壁小钢炮 vs InternVL2-8B:谁能精准指路,多个路标也不迷路?: MiniCPM-V 2.6是面壁智能近期发布的多模态大模型,上期周刊已经介绍过,InternVL2-8B 是上海AI Lab开源的一款多模态的大型语言模型,属于 InternVL 2.0 系列,可以处理涉及文本、图像和视频的各种任务,支持 8k 的上下文。模型基于InternViT-300M +internlm2_5-7b-chat架构。本文通过对MiniCPM-V-2.6和InternVL2-8B的进行对比实测,发现两个模型在多模态任务中各有优势。MiniCPM-V-2.6在复杂视觉问答任务中表现更出色,例如能够准确理解和解析多个路标的信息,做到更精准地指路;而InternVL2-8B在OCR识别方面表现更优异,能够完整识别图像中的文字内容,在细节处理上更优,例如在文本和图表内容混合的情况下,能准确识别出图表中的单位。、
Task Facet Learning: A Structured Approach to Prompt Optimization:UNIPROMPT 是一个新提出的 Prompt 优化框架,它能够生成既复杂又全面的 Prompt,这是现有方法所缺乏的。该框架分为两个阶段:首先,利用大型语言模型(LLM)生成包含多个任务方面的初始 Prompt;其次,基于训练示例和辅助 LLM 对 Prompt 进行细化。UNIPROMPT 的主要创新点包括:将 Prompt 分解为多个独立的语义部分,每个部分对应任务的一个方面;通过对训练示例进行聚类来识别任务的不同方面;采用两层反馈机制,从具体示例中提炼出可泛化的概念。在实验中,UNIPROMPT 在多个标准数据集上的表现显著优于现有方法,包括 zero-shot 和 few-shot 设置,并且在真实世界的搜索查询意图任务上生成的 Prompt 甚至优于人工编写的最佳 Prompt。
产品
DeepSeek开源数学定理证明模型:DeepSeek 推出了 DeepSeek-Prover-V1.5,这是一款开源的数学定理证明模型。该模型通过将数学问题转换为 Lean 编程语言,并结合类似 AlphaGo 的强化学习系统,以及 Lean 证明器的监督,建立了一个自我迭代的学习环境。在高中水平的 miniF2F 和大学本科水平的 ProofNet 基准测试中,Prover-V1.5 分别达到了 63.5% 和 25.3% 的成功率,超越了其他开源模型。
这家一直在做模型层面的创新,这次的工作为未来开发能够自主提出并证明完整数学理论的 AI 系统奠定了基础。
论文和模型均已开源:
论文地址:https://arxiv.org/abs/2408.08152
模型下载:https://huggingface.co/deepseek-ai
GitHub 主页:https://github.com/deepseek-ai/DeepSeek-Prover-V1.5
微软发布了Phi-3.5系列模型:包括Phi-3.5 Mini Instruct、Phi-3.5 Vision Instruct和Phi-3.5 MoE,并且支持128K上下文。Phi-3.5 Mini Instruct拥有3.8B参数,适用于移动设备等环境。Phi-3.5 Vision Instruct是多模态模型,拥有4.2B参数,适用图像理解和视频摘要。Phi-3.5 MoE具有16x3.8B 参数,活跃参数为6.6B,经过4.9T tokens的训练,展现出强大的代码和数学理解能力。
数势科技SwiftAgent:一款基于大模型和AI Agent的企业数据分析与决策产品,自然语言取数问数的准确率达到95%以上,而且响应很快,对千奇百怪的自然语言表达还有黑话都能处理的很准确,搜罗了下资料,找到产研团队的一篇技术类talk,基本讲清楚了怎么实现才达到这么好的效果,对做BI和text2SQL的朋友很有用,还有另一篇技术分享的文章。
市场
- 中国大模型平台市场份额,2023:大模型元年——初局:IDC数据显示,2023年中国大模型平台及相关应用市场规模达17.65亿元人民币(比不过一只“猴子”🐶,《黑神话:悟空》全平台销量预测可最高达到700万套,以268元的最低销售价格计算,该游戏的买断制销售流水高达18.76亿元)。在过去的一年中,行业对于大模型更多的是早期投入,甚至观望而不重投入,因此2023年整体市场规模并不显著;并且市场格局也主要还是由早期投入者如百度、商汤、智谱、百川等公司构成。进入2024年,头部互联网公司加大对大模型的投入且发起价格战,预计未来2—3年,市场格局将发生多轮巨变。
- a16z 发布生成式AI消费者应用Top 100(app 基于月活的统计排序很奇怪,而且豆包比 talkie 低,国内上榜的相对位置看看就好。)
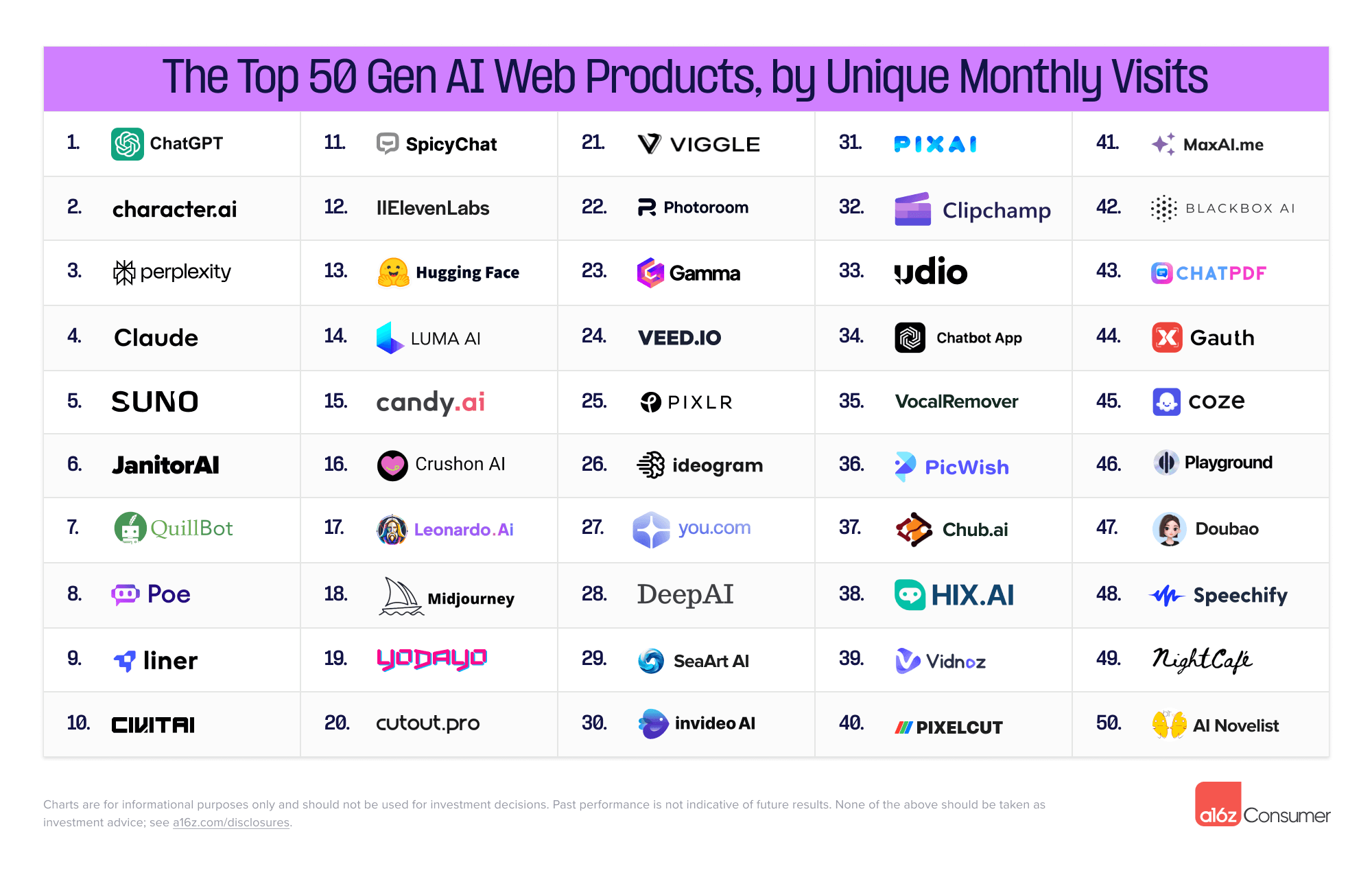
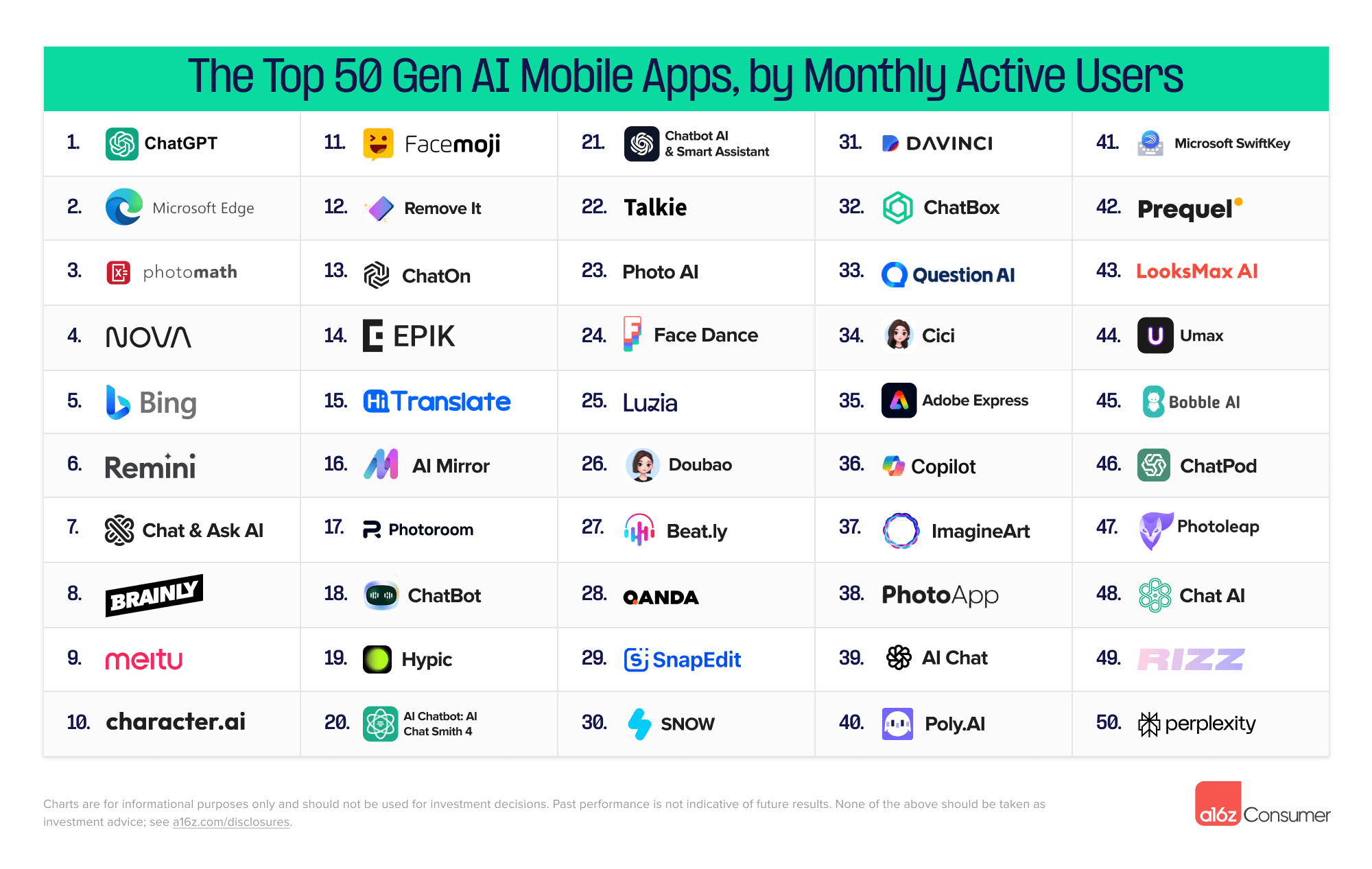
创意工具的吸引力不减:网页榜单上,超半数公司专注于内容创作或编辑,包括图像、视频、音乐和语音等多种类型。其中,12个新上榜应用中,超过一半属于创意工具,其中音乐生成器Suno的排名最为惊艳,从第36位飞跃至第5位。
AI助手领域竞争激烈:ChatGPT连续三次蝉联网页和移动端首位产品,在网页端,Perplexity和Anthropic的Claude排名第三和第四。移动端新晋Luzia直接排名第25。
字节跳动快速扩张AI产品线:字节跳动新增三款AI应用首次登上榜单,包括教育平台Gauth、机器人构建器Coze和通用助手Doubao,使得总共六款其应用进入排名。
新进入榜单的LooksMax AI、Umax和RIZZ等应用展示了AI在个性化美学和约会领域建议方面的巨大潜力。
Discord对AI应用排名的关键影响,Discord成为生成式AI应用在网页和移动端排名提升的关键指标,尤其在内容生成领域。Midjourney继续在所有Discord服务器的邀请流量中保持鳌头位置。
观点
- 大模型是泡沫吗?: 一篇关于从事大模型工作的感悟文章。不谈技术,只聊聊这两年从事 llm 工作的一些感悟。
Vol.18:大模型是泡沫吗?
