Vol.47:workflow 与 Agent 方案如何选择?
大家好!Weekly Gradient 第 47 期内容已送达!
✉️ 免费订阅更新
订阅我的免费通讯,第一时间获取生成式 AI 领域优质内容
我承诺保护您的隐私,不会向第三方分享您的信息。
您可以随时取消订阅。
Web Agent 专题
ReasonerAgent 是一个基于 LLM 的开源 Agent,它能够在浏览器中执行复杂的任务,包括但不限于航班搜索、在线购物以及新闻报道的研究。该 Agent 通过模拟世界模型来规划行动,而不是依赖自回归的语言模型,这使得它在复杂的网页导航任务上表现出色,例如将成功率从 0 提升到 32.2%。对 LLM 驱动自动操作实现原理感兴趣可以先看这篇文章。
ReasonerAgent 建立在 OpenHands BrowsingAgent 基础上,使用 Reasoner( 一个使用LLM 进行高级推理的库)实现了基于模拟的规划。世界模型和反思部分的提示词改编自 Web Dreamer (一种基于模型的网页浏览规划方法),对于网页浏览器,采用了 BrowserGym ,这是一个用于网页代理的开源环境。
Browserbase 是一个为 AI 应用及 Agent 提供 Web 浏览功能的SaaS服务,支持主要的自动化测试工具和框架:Playwright、Puppeteer、Selenium 和 Stagehand (Browserbase 自家框架),这些工具和框架可以与 Browserbase 无缝集成,以提供自动化测试和浏览器自动化的解决方案。
An Internet Browser for AI :这是 Browserbase 创始人 2023 年 11 月的一篇文章,总结现有的数据抓取方法和挑战、浏览器自动化现状及现有解决方案的局限性。详细分析了作为新型 AI 应用的核心原语,Web Agent 的重要性,为 AI 应用提供交互式网页浏览和数据抓取的能力,以及 AI 应用为未来浏览器自动化带来的新市场和机会。
它的 blog 可以了解下基于 browser-use-agent在一些垂直场景的产品创新。
Manus 依赖的开源工具 browser-use 近日完成 1700 万美元种子轮融资,Browser Use 的核心功能是:将网站中的按钮和界面元素解析成更易于处理、类似文本的结构化格式,以便 AI 理解页面上的各种操作选项,并自主做出决策。联合创始人 Müller 表示:“现在很多 AI Agent 依赖视觉系统,通过截图来导航网页,但这个过程经常出错。我们把网页转换成 Agent 可以理解的形式,这种方法让我们可以用更低的成本反复执行相同的任务。”
open-operator:一个开源的 Web Agent 实现,理解用户的意图,将其转换为无头浏览器操作并执行操作。
论文
OmniTalker :一个实时文本驱动的头像生成框架,它能够同时生成语音和视频头像动画,并且能够在不需要额外样式提取模块的情况下,从单个参考视频中捕捉到音频和视觉风格的特征。该框架采用了双分支的扩散变换器(Diffusion Transformer)架构,其中音频分支负责合成 mel 频谱,视觉分支则负责预测头部动作和面部表情。OmniTalker 通过一个新的音视频融合模块,确保了音频和视频输出之间的时间同步和风格一致性。该框架还具备实时推理能力,可以在 25 FPS 的速度下进行实时生成,并且在样式复制和音视频同步方面超越了现有的方法。
很有 C 端娱乐向产品商业潜力,效果比之前介绍的字节的 OmniHuman-1更进一步,除此之外还有Meta 出品的 MoCha(实现电影级别人物口型合成的系统)
文档识别用多模态还是 OCR:基于实验结果,提炼出 MM-LLMs 在工业级 OCR 应用的实施建议
- 高价值文档必须专业扫描:合同、票据等关键文件需使用 ≥300PPI 的扫描设备。
- 数字验证场景双系统并行:对验证码、身份证号等场景,建议采用”MM-LLMs 语境理解+传统 OCR 字符校验”的双重机制。
- 复杂文本发挥大模型优势:当处理古籍或手写笔记时,MM-LLMs 能结合上下文纠正单字错误。
大语言模型自动规划能力综述:讨论了 LLMs 在自动规划中的应用,包括它们在提高规划能力、增强语言模型的泛化能力、作为独立规划器的局限性等方面的研究。在此基础上,论文进一步探讨了 LLMs 在增强传统规划器、提供高级子任务指导、评估计划质量和风格、以及处理多智能体规划等方面的潜在应值和面临的挑战。LLMs 在自动规划在实际应用中需要解决的问题,如处理语言中的歧义、评估计划成本、提高计算效率、减少知识盲点、提高模型的解释性和可解释性、以及实现因果世界模型等。
工程
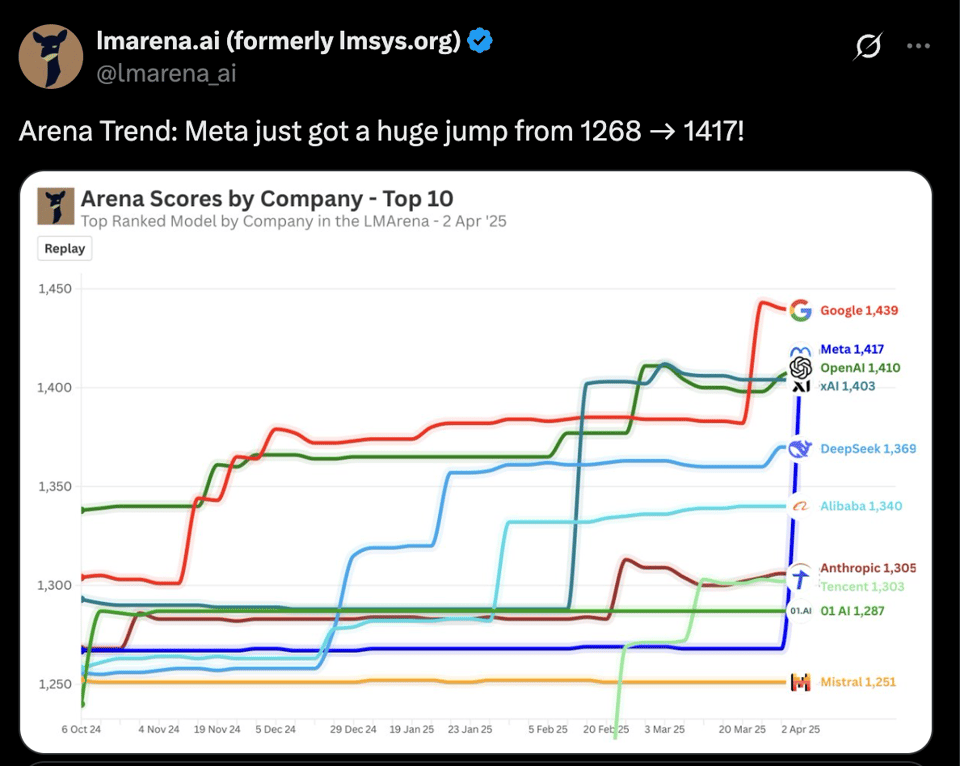
Meta AI 发布 Llama 4 系列:包括了 Llama 4 Scout 和 Llama 4 Maverick 两种模型。Llama 4 Scout 是一个 170 亿参数的模型,具有 16 个专家系统,它在单个 NVIDIA H100 GPU 上运行,上下文窗口长度 10M。Llama 4 Maverick 同样是一个 170 亿参数的模型,拥有 128 个专家系统,它在单个 H100 主机上运行,并在 LMArena 上获得了 1417 的 ELO 评分。这些模型由 Llama 4 Behemoth(一个 2880 亿参数的模型) 训练而成。
AWS MCP 服务器是一套集成了多个功能服务器的解决方案,旨在将 AWS 的最佳实践直接融入到开发者的工作流程中:包括核心服务器、AWS 文档服务器、AWS CDK 服务器、Amazon Nova Canvas 服务器、Amazon Bedrock 知识库检索服务器以及成本分析服务器。每个服务器都具备特定的功能和特点,例如:
- 核心 MCP 服务器 负责管理和协调其他 MCP 服务器,提供自动化安装、配置和管理功能。
- AWS 文档 MCP 服务器 提供对 AWS 文档的访问,以及如何使用 AWS 的最佳实践。
- AWS CDK MCP 服务器 提供了 AWS Cloud Development Kit(CDK)的最佳实践、基础设施即代码模式,以及使用 CDK Nag 进行安全合规性的方法。
- Amazon Nova Canvas MCP 服务器 使得 AI 助手能够使用 Amazon Nova Canvas 生成图像。
- Amazon Bedrock 知识库检索 MCP 服务器 允许 AI 助手从 Amazon Bedrock 知识库中检索信息。
- 成本分析 MCP 服务器 允许 AI 助手分析 AWS 服务的成本,并生成成本报告和洞察。
-
- 缺乏内部一致性:多次执行相同的输入可能得到不同的结果,建议采用自我一致性的 prompt 设置,并保留多数结果。
- 自我偏好:LLM 更偏好自己的输出模式,建议采用陪审团机制。
- 输入扰动不敏感:LLM 难以提供一致的评分范围,建议模型先输出详细的推理过程再给出评分。
- 位置偏差:LLM 偏好特定位置的答案,建议随机调整答案位置。
- 冗长偏好:LLM 偏好冗长的答案,建议考虑答案中的长度差异。
- 格式偏差:如果输入模型的 prompt 格式与训练数据格式差异大,可能导致评估结果不准确。
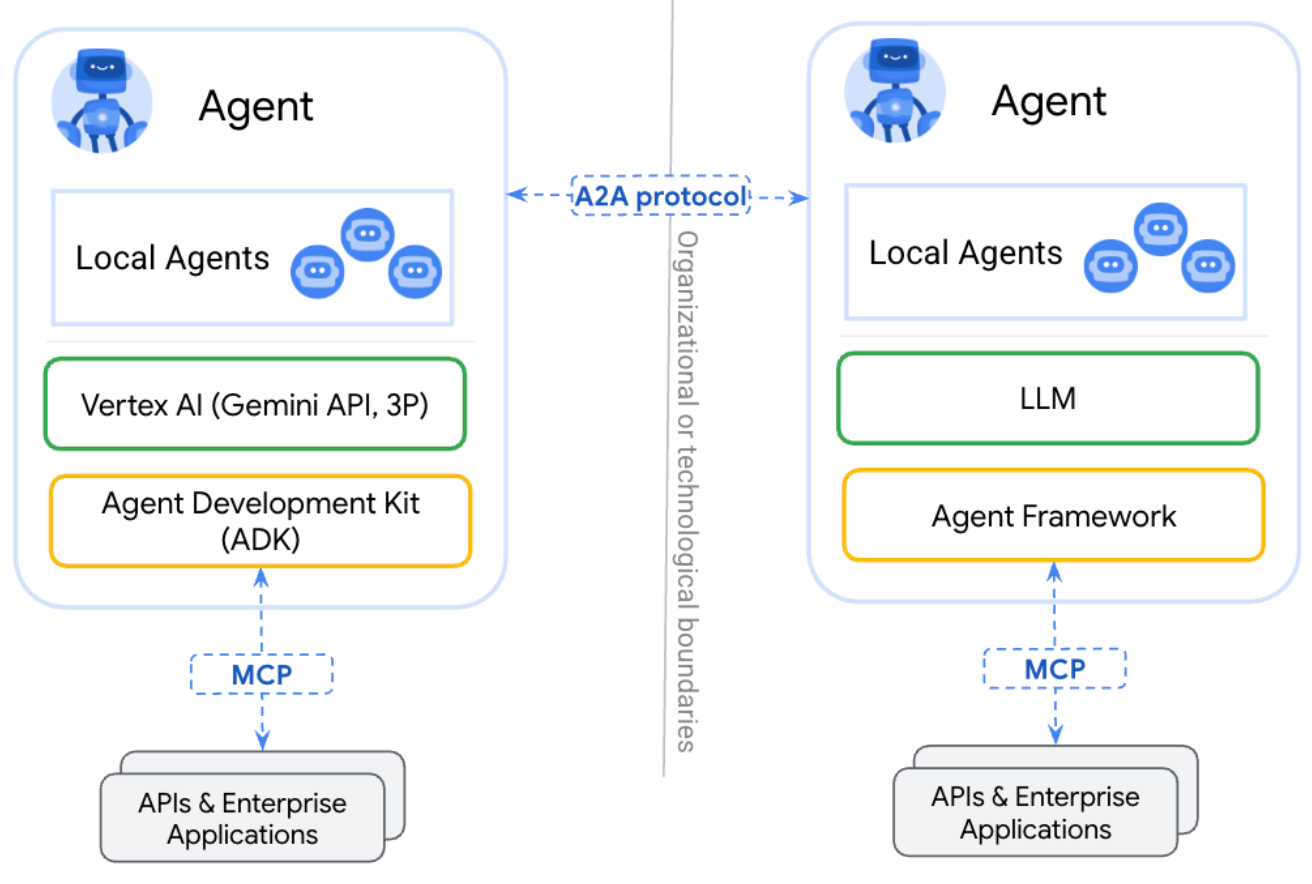
宣布推出 Agent2Agent 协议 (A2A):A2A 协议是为了解决不同智能代理之间互操作的问题,使得它们能够更流畅地相互协作和交流。该协议基于开放的标准和规范,旨在消除技术壁垒,促进更广泛的协作。A2A 的目标是通过建立一个共同的通信和交互标准,让智能代理能够更有效地共同工作,实现多智能体之间的协同和互操作性。这将有助于实现更复杂的智能体系构,为用户提供更丰富的互动体验。
Google 的 Gemini 2.5 Pro 在编码能力、推理能力以及整体性能方面超过了 Claude 3.7 Sonnet,成为了当前最佳的编码模型:在四个编码测试中,Gemini 2.5 Pro 都显示出了优异的表现,包括制作一个简单的飞行模拟器、Rubik 魔方解决器、3D 恐龙游戏模型以及解决复杂的 LeetCode 问题等。
Kimi开源了两个MoE视觉理解大模型-Kimi-VL-A3B-Instruct和Kimi-VL-A3B-Thinking:总参数16.4B,激活参数仅为2.8B,上下文长度128K。
产品
Anthropic 向开发者提供 50 美元的免费 Claude API 积分,鼓励开发者尝试 Claude Code 工具。
百炼支持部署自定义 MCP 服务:百炼支持部署自定义 MCP 服务,目前仅支持 npx 的安装方式,未来会支持 uvx 和 SSE 的安装方式,在百炼部署的 MCP 服务目前仅支持接入百炼应用,暂不支持在其他 MCP 客户端使用。

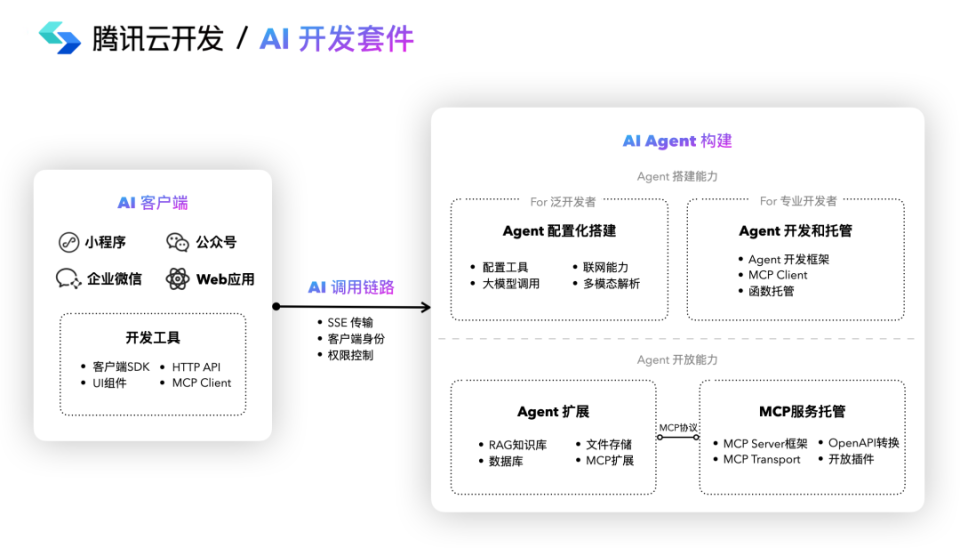
腾讯云发布「AI开发套件」:帮助开发者快速搭建业务型AI Agent,支持MCP插件托管服务,插件开发、部署、运维全「打包」,无需自搭服务器、运维环境,让Agent扩展能力真正「即插即用」,让开发者专注业务创新。
GitHub 官方开源 MCP 服务器,AI 无缝集成 GitHub API:GitHub 官方开源了与 GitHub API 无缝集成的 MCP 服务器,支持在 VS Code Agent Mode 和 Claude Desktop 中或任何支持 MCP 服务器的环境中使用。
市场
OpenAI 正在考虑收购 CEO Sam Altman 和苹果前设计主管 Jony Ive 共同创办的 AI 硬件公司 io Products,收购价可能超过 5 亿美元,合作开发也是可能选项。目前该项目还在早期阶段,主要开发 AI 驱动的硬件设备,包括无屏幕手机和智能家居产品。
170 多家 AI 代理初创公司: CB Insights Research 分享了 AI Agent 市场的现状和未来发展趋势,包括市场地图、AI Agent 技术的进展、应用场景、以及对企业影响。
a16z 推出 AI 数字人报告:提到了创建 AI 数字人的要素。
创建一个可信的 AI 数字人是一项挑战,有关逼真度的每个要素都会带来各自的技术障碍。这不仅要避免出现难以想象的障碍,还要解决动画、语音合成和实时渲染方面的基本问题。以下是对所需技术的细分,为何如此难以实现,以及我们在哪些方面取得了进展:
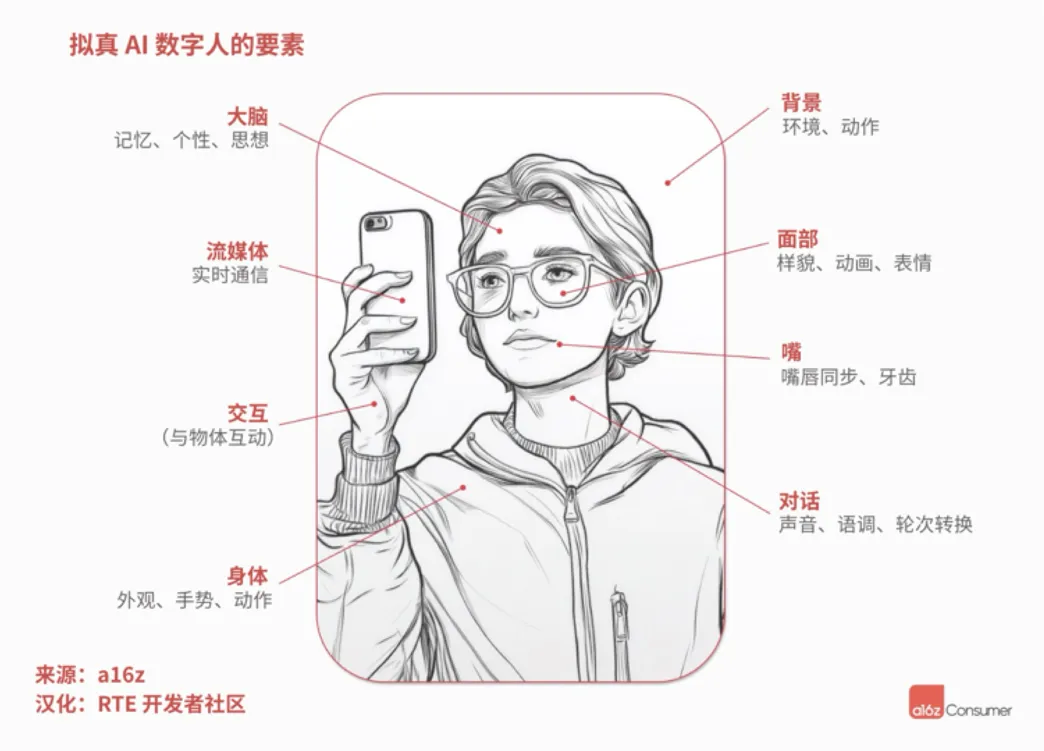
- 面部:无论你是在克隆一个人还是在创建一个新角色,你都需要一张在不同帧之间保持一致,并且在说话时动作逼真的面部。上下文感知的表现力仍然是一个挑战(例如,一个数字人在说 「我累了」时打哈欠)。
- 声音:声音需要听起来真实并与角色相匹配;少女的脸不应该有老妇的声音。我们遇到的大多数 AI 数字人公司都使用 ElevenLabs ,它拥有一个庞大的语音库,并允许用户克隆自己的声音。
- 唇部同步:要获得高质量的唇部同步非常困难。许多公司,如 Sync 都致力于解决这一问题。其他模型,如 MoCha(来自 Meta)和 OmniHuman 是在更大的数据集上进行训练,并使用各种技术对伴随音频的人脸生成进行强条件限制。在更大的数据集上进行训练,但找到了根据音频强烈调节人脸框架生成的方法。
- 身体:数字人不能只是一个漂浮的头部!较新的模型可使数字人拥有可移动的完整躯体,但在扩展躯体和向用户交付躯体方面,我们仍处于早期阶段。
- 背景:数字人并非存在于真空中。数字人周围环境的照明、深度和交互需要与场景相匹配。理想情况下,数字人甚至能够触摸和接触环境中的事物,例如拿起产品。
观点
- 什么时候应该拆workflow,什么时候应该指望模型:作者讨论了在新场景构建时,如何通过拆分 workflow 以及在什么情况下应该采用模型的方法来解决问题。在已有系统的演进过程中,如何平衡拆分 workflow 与等待模型发展的需求,特别是在有效的中间过程检查验证方案存在时。
Vol.47:workflow 与 Agent 方案如何选择?
